ufldl学习笔记与编程作业:Convolutional Neural Network(卷积神经网络)
ufldl学习笔记与编程作业:Convolutional Neural Network(卷积神经网络)
ufldl出了新教程,感觉比之前的好,从基础讲起,系统清晰,又有编程实践。
在deep learning高质量群里面听一些前辈说,不必深究其他机器学习的算法,可以直接来学dl。
于是最近就开始搞这个了,教程加上matlab编程,就是完美啊。
新教程的地址是:http://ufldl.stanford.edu/tutorial/
本节学习地址:http://ufldl.stanford.edu/tutorial/supervised/ConvolutionalNeuralNetwork/
一直没更新UFLDL的学习笔记,因为之前用octave跑这份代码失败了,检查了代码觉得没错误,后来想着用matlab跑,
不过一直耽搁着,今天装了matlab,果然,成功了。
其实卷积神经网络没什么特别,卷积层的连接可以看成是local connection就可以了。
下面是主要代码:
cnnCost.m
function [cost, grad, preds] = cnnCost(theta,images,labels,numClasses,...
filterDim,numFilters,poolDim,pred)
% Calcualte cost and gradient for a single layer convolutional
% neural network followed by a softmax layer with cross entropy
% objective.
%
% Parameters:
% theta - unrolled parameter vector
% images - stores images in imageDim x imageDim x numImges
% array
% numClasses - number of classes to predict
% filterDim - dimension of convolutional filter
% numFilters - number of convolutional filters
% poolDim - dimension of pooling area
% pred - boolean only forward propagate and return
% predictions
%
%
% Returns:
% cost - cross entropy cost
% grad - gradient with respect to theta (if pred==False)
% preds - list of predictions for each example (if pred==True)
if ~exist('pred','var')
pred = false;
end;
weightDecay = 0.0001;
imageDim = size(images,1); % height/width of image
numImages = size(images,3); % number of images
%% Reshape parameters and setup gradient matrices
% Wc is filterDim x filterDim x numFilters parameter matrix %convolution参数
% bc is the corresponding bias
% Wd is numClasses x hiddenSize parameter matrix where hiddenSize
% is the number of output units from the convolutional layer %这个convolutional layer应该是包含了卷积层和pool层
% bd is corresponding bias
[Wc, Wd, bc, bd] = cnnParamsToStack(theta,imageDim,filterDim,numFilters,...
poolDim,numClasses);
% Same sizes as Wc,Wd,bc,bd. Used to hold gradient w.r.t above params.
Wc_grad = zeros(size(Wc));
Wd_grad = zeros(size(Wd));
bc_grad = zeros(size(bc));
bd_grad = zeros(size(bd));
%%======================================================================
%% STEP 1a: Forward Propagation
% In this step you will forward propagate the input through the
% convolutional and subsampling (mean pooling) layers. You will then use
% the responses from the convolution and pooling layer as the input to a
% standard softmax layer.
%% Convolutional Layer
% For each image and each filter, convolve the image with the filter, add
% the bias and apply the sigmoid nonlinearity. Then subsample the
% convolved activations with mean pooling. Store the results of the
% convolution in activations and the results of the pooling in
% activationsPooled. You will need to save the convolved activations for
% backpropagation.
convDim = imageDim-filterDim+1; % dimension of convolved output
outputDim = (convDim)/poolDim; % dimension of subsampled output
% convDim x convDim x numFilters x numImages tensor for storing activations
activations = zeros(convDim,convDim,numFilters,numImages);
% outputDim x outputDim x numFilters x numImages tensor for storing
% subsampled activations
activationsPooled = zeros(outputDim,outputDim,numFilters,numImages);
%%% YOUR CODE HERE %%% %调用之前写的两个函数
activations = cnnConvolve(filterDim, numFilters, images, Wc, bc);
activationsPooled = cnnPool(poolDim, activations);
% Reshape activations into 2-d matrix, hiddenSize x numImages,
% for Softmax layer
activationsPooled = reshape(activationsPooled,[],numImages);%就变成了传统的softmax模式
%% Softmax Layer
% Forward propagate the pooled activations calculated above into a
% standard softmax layer. For your convenience we have reshaped
% activationPooled into a hiddenSize x numImages matrix. Store the
% results in probs.
% numClasses x numImages for storing probability that each image belongs to
% each class.
probs = zeros(numClasses,numImages);
%%% YOUR CODE HERE %%%
z = Wd*activationsPooled;
z = bsxfun(@plus,z,bd);
%z = Wd * activationsPooled+repmat(bd,[1,numImages]);
z = bsxfun(@minus,z,max(z,[],1));%减去最大值,减少一个维度
z = exp(z);
probs = bsxfun(@rdivide,z,sum(z,1));
preds = probs;
%%======================================================================
%% STEP 1b: Calculate Cost
% In this step you will use the labels given as input and the probs
% calculate above to evaluate the cross entropy objective. Store your
% results in cost.
cost = 0; % save objective into cost
%%% YOUR CODE HERE %%%
logProbs = log(probs);
labelIndex=sub2ind(size(logProbs), labels', 1:size(logProbs,2));
%找出矩阵logProbs的线性索引,行由labels指定,列由1:size(logProbs,2)指定,生成线性索引返回给labelIndex
values = logProbs(labelIndex);
cost = -sum(values);
weightDecayCost = (weightDecay/2) * (sum(Wd(:) .^ 2) + sum(Wc(:) .^ 2));
cost = cost / numImages+weightDecayCost;
%Make sure to scale your gradients by the inverse size of the training set
%if you included this scale in the cost calculation otherwise your code will not pass the numerical gradient check.
% Makes predictions given probs and returns without backproagating errors.
if pred
[~,preds] = max(probs,[],1);
preds = preds';
grad = 0;
return;
end;
%%======================================================================
%% STEP 1c: Backpropagation
% Backpropagate errors through the softmax and convolutional/subsampling
% layers. Store the errors for the next step to calculate the gradient.
% Backpropagating the error w.r.t the softmax layer is as usual. To
% backpropagate through the pooling layer, you will need to upsample the
% error with respect to the pooling layer for each filter and each image.
% Use the kron function and a matrix of ones to do this upsampling
% quickly.
%%% YOUR CODE HERE %%%
%softmax残差
targetMatrix = zeros(size(probs));
targetMatrix(labelIndex) = 1;
softmaxError = probs-targetMatrix;
%pool层残差
poolError = Wd'*softmaxError;
poolError = reshape(poolError, outputDim, outputDim, numFilters, numImages);
unpoolError = zeros(convDim, convDim, numFilters, numImages);
unpoolingFilter = ones(poolDim);
poolArea = poolDim*poolDim;
%展开poolError为unpoolError
for imageNum = 1:numImages
for filterNum = 1:numFilters
e = poolError(:, :, filterNum, imageNum);
unpoolError(:, :, filterNum, imageNum) = kron(e, unpoolingFilter)./poolArea;
end
end
convError = unpoolError .* activations .* (1 - activations);
%%======================================================================
%% STEP 1d: Gradient Calculation
% After backpropagating the errors above, we can use them to calculate the
% gradient with respect to all the parameters. The gradient w.r.t the
% softmax layer is calculated as usual. To calculate the gradient w.r.t.
% a filter in the convolutional layer, convolve the backpropagated error
% for that filter with each image and aggregate over images.
%%% YOUR CODE HERE %%%
%softmax梯度
Wd_grad = (1/numImages).*softmaxError * activationsPooled'+weightDecay * Wd; % l+1层残差 * l层激活值
bd_grad = (1/numImages).*sum(softmaxError, 2);
% Gradient of the convolutional layer
bc_grad = zeros(size(bc));
Wc_grad = zeros(size(Wc));
%计算bc_grad
for filterNum = 1 : numFilters
e = convError(:, :, filterNum, :);
bc_grad(filterNum) = (1/numImages).*sum(e(:));
end
%翻转convError
for filterNum = 1 : numFilters
for imageNum = 1 : numImages
e = convError(:, :, filterNum, imageNum);
convError(:, :, filterNum, imageNum) = rot90(e, 2);
end
end
for filterNum = 1 : numFilters
Wc_gradFilter = zeros(size(Wc_grad, 1), size(Wc_grad, 2));
for imageNum = 1 : numImages
Wc_gradFilter = Wc_gradFilter + conv2(images(:, :, imageNum), convError(:, :, filterNum, imageNum), 'valid');
end
Wc_grad(:, :, filterNum) = (1/numImages).*Wc_gradFilter;
end
Wc_grad = Wc_grad + weightDecay * Wc;
%% Unroll gradient into grad vector for minFunc
grad = [Wc_grad(:) ; Wd_grad(:) ; bc_grad(:) ; bd_grad(:)];
end
minFuncSGD.m
function [opttheta] = minFuncSGD(funObj,theta,data,labels,...
options)
% Runs stochastic gradient descent with momentum to optimize the
% parameters for the given objective.
%
% Parameters:
% funObj - function handle which accepts as input theta,
% data, labels and returns cost and gradient w.r.t
% to theta.
% theta - unrolled parameter vector
% data - stores data in m x n x numExamples tensor
% labels - corresponding labels in numExamples x 1 vector
% options - struct to store specific options for optimization
%
% Returns:
% opttheta - optimized parameter vector
%
% Options (* required)
% epochs* - number of epochs through data
% alpha* - initial learning rate
% minibatch* - size of minibatch
% momentum - momentum constant, defualts to 0.9
%%======================================================================
%% Setup
assert(all(isfield(options,{'epochs','alpha','minibatch'})),...
'Some options not defined');
if ~isfield(options,'momentum')
options.momentum = 0.9;
end;
epochs = options.epochs;
alpha = options.alpha;
minibatch = options.minibatch;
m = length(labels); % training set size
% Setup for momentum
mom = 0.5;
momIncrease = 20;
velocity = zeros(size(theta));
%%======================================================================
%% SGD loop
it = 0;
for e = 1:epochs
% randomly permute indices of data for quick minibatch sampling
rp = randperm(m);
for s=1:minibatch:(m-minibatch+1)
it = it + 1;
% increase momentum after momIncrease iterations
if it == momIncrease
mom = options.momentum;
end;
% get next randomly selected minibatch
mb_data = data(:,:,rp(s:s+minibatch-1));
mb_labels = labels(rp(s:s+minibatch-1));
% evaluate the objective function on the next minibatch
[cost grad] = funObj(theta,mb_data,mb_labels);
% Instructions: Add in the weighted velocity vector to the
% gradient evaluated above scaled by the learning rate.
% Then update the current weights theta according to the
% sgd update rule
%%% YOUR CODE HERE %%%
velocity = mom*velocity+alpha*grad;
theta = theta-velocity;
fprintf('Epoch %d: Cost on iteration %d is %f\n',e,it,cost);
end;
% aneal learning rate by factor of two after each epoch
alpha = alpha/2.0;
end;
opttheta = theta;
end
运行结果:
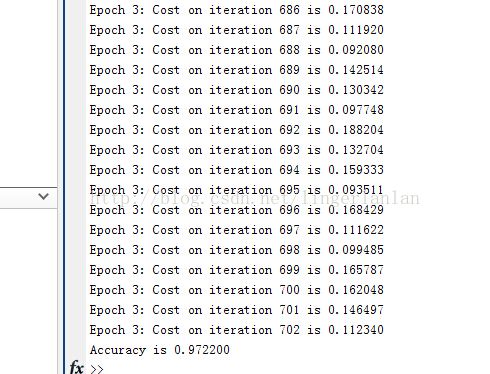
本文作者:linger
本文链接:http://blog.csdn.net/lingerlanlan/article/details/41390443