一致性hash Ketama
一致性hash算法
一致性hash算法用于解决在服务器集群中,添加/删除Server只影响极少部分的Client。例如我们有10台Server提供服务,且有一个均衡负载的前端,前端通过普通的取模将Client定向到某一台Server:
client_hash_val % 10
当10台Server中有一台Server宕机时,这个取模操作成了:
client_hash_val % 9
当新添加1台Server时,这个取模操作成了:
client_hash_val % 11
凭感官认识,我们可知当Server集群发生机器变动时,大部分Client会被定向到不同的Server。一致性Hash可避免这样的问题。我们还是以那两幅经典的一致性hash图来了解这个算法。
首先将Server分布在一个圆上。有Client发起连接请求时,也将Client散列到这个圆上,按顺时针方向搜索离它最近的一台Server:
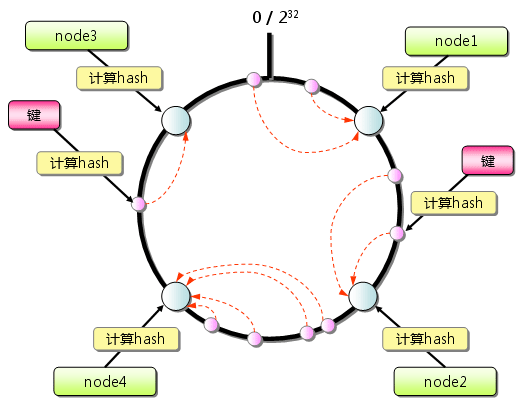
当有Server被删除或宕机时,只影响分布到它上面的Client,且这些Client继续沿顺时针方向找到新Server,其他的Client则完全不受影响:

现实中,每个Server会被散列到圆上的多个点,且多个Server会被均匀的分布在整个圆上。下面是我的一个测试对比,测试环境是10台Server,2,000,000个Client,当Server集合变化时受影响的Client比例:
| 添加1台Server | 删除一台Server | |
|---|---|---|
| 取模算法 | 90.91% | 90% |
| 一致性hash算法 | 8.29% | 8.28% |
Ketama一致性hash实现的代码框架
Ketama一致性hash的实现代码比较简练,以下分析它的主要代码结构。Ketama一致性hash限制最多支持1024个Server,平均每个Server在圆上占据200个点:
#define MAX_SERVERS 1024 #define POINTS_PER_SERVER 200
构造圆是这份代码的关键:
int create_continuum(ketama_continuum contptr);
函数开始处的初始化:
int create_continuum( ketama_continuum contptr ) { // 获取服务器列表 serverinfo* slist = contptr->sv_list; /* 一个Point对应一个mcs对象,这里创建了一个Points数组 */ mcs continuum[contptr->numsv * POINTS_PER_SERVER ]; unsigned int i, j, k, cont = 0, numservers = contptr->numsv; /* 通过内存计算服务器权重,这里先计算服务器集群的总内存数 */ unsigned long memory = sum_memory( contptr ); /* 临时容器,存储生成的Points */ const int dupecheck_size = numservers * POINTS_PER_SERVER * 10; char seenHvals[dupecheck_size]; for( i=0; i<(unsigned int)dupecheck_size; i++) seenHvals[i]=0;
seenHvals的作用是检查hash冲突。当存在冲突,将用新的Server值覆盖旧的Server值。接下来有两重循环(伪代码):
for server in server_list: for point in server_points: point_hash_val = hash(point); slot = point_hash_val % dupecheck_size if seenHvals[slot] == 1: // 已占(hash冲突) bool bail = false; // 标志是否是真正的冲突 for cpoint in continuum: // 遍历已生成的Points集合 if cpoint.hash_val == point_hash_val: // 找到冲突 if the not same server: cpoint.server = server // 用新的替换 bail = true; // 是真正的冲突 break; // 冲突解决完毕 if bail: // 是真正冲突(并已解决冲突),不用创建新Point continue; else: seenHvals[slot] = 1 // 没有冲突,或“假”冲突 continuum.push(new point);
逻辑关系大致如上,以下是实现代码:
// 遍历Server列表 for( i = 0; i < numservers; i++ ) { // 计算该Server占总内存的比例 float pct = (float)slist[i].memory / (float)memory; // 依据内存比例来决定Server在圆上占据的点的个数 unsigned int ks = (unsigned int)floorf( pct * (float)numservers * POINTS_PER_SERVER ); /* 如果Server将占据N个点,则每个点的字符串设为:ip:port-n * 例如: 127.0.0.1:80-1, 127.0.0.1:80-2 .... 127.0.0.1:80-n * hval存储Server的hash值,这里用了FNV hash算法 */ Fnv32_t hval = FNV1_32_INIT; // FNV1_32_INIT是一个无符号整数,这里可先忽略之 // 生成每个Point for( k = 0; k < ks; k++ ) { char ss[30]; sprintf( ss, "%s-%d", slist[i].addr, k ); hval = fnv_32a_str(ss, hval); // 每次生成的hash值,将参与下一次hash计算 /* BEGIN COLLISION DETECTION * 根据hash值判断是否存在冲突 */ unsigned int slot = hval % dupecheck_size; if(1 == seenHvals[slot]) { // 遍历已生成的Points集合,发现是否是真正存在冲突 int bail = 0; for( j = 0; j < cont; j++ ) { if( continuum[j].point == hval ) // 确实存在冲突 { if ( continuum[j].svptr != slist + i ) continuum[j].svptr = slist + i; // 用新的Server替换 bail = 1; break; } } // 真正的冲突,不用生成新的Point了 if(bail) continue; }else{ seenHvals[slot]=1; } /* END COLLISION DETECTION */ // 生成新的Point,加入到continuum中 continuum[cont].point = (unsigned int) hval; // point is the value between 0-2^32 continuum[cont].svptr = slist+i; // svptr will point server infor structs on sv_list cont++; } }
所有的Server和每个Server的Points都处理完毕后,就是把这些数据,通过函数参数contptr传出:
/* Sorts in ascending order of "point" */ qsort( (void*) &continuum, cont, sizeof( mcs ), (compfn)ketama_compare ); contptr->numpoints = cont; contptr->sv_circle = (mcs*)malloc( cont*sizeof(mcs) ); memcpy( contptr->sv_circle, continuum, cont*sizeof(mcs) ); return 0; }
除了构建圆,另一个关键函数是查找Client所属Server:
mcs* ketama_get_server(const char* key, int len, ketama_continuum cont );
查找用二分搜索即可。
FNV hash算法
FNV又称Fowler/Noll/Vo,来自3位算法设计者的名字(Glenn Fowler、Landon Curt Noll和Phong Vo)。FNV有3种:FNV-0(已过时)、FNV-1、FNV-1a,后两者的差别极小。FNV-1a生成的hash值有几个特点:无符号整形;hash值的bits数,是2的n次方(32, 64, 128, 256, 512, 1024),通常32 bits就能满足大多数应用。
FNV-1a的算法框架是:
hash = hash_init _hash(data, hash): for byte in data: hash ^= byte hash *= prime return hash
hash_init有一个初始值,对32bits hash而言,这个值是0x811C9DC5,每次hash结束后返回的新值,将加入下一次的hash运算;prime的值是另一个关键,32bits hash的prime值是0x01000193。
因为FNV hash只返回2的n次方bit位的hash值,要获得其他bit位的hash需要做一些简单的额外运算。如要获取24bits的hash值:
hash = _hash(data, hash); hash = (hash >> 24) ^ (hash & 0xFFFFFF);
获取[0,9999]之间的hash值:
hash = _hash(data, hash); hash = hash mod (9999 + 1);
参考
FNV Hash。