python爬虫——爬取用js实现翻页的网站
——————————————-背景介绍———————————————
首先,这次想爬取的网站地址为:http://www.zhuhai.gov.cn/hd/zxts_44606/tsfk/

查看网站的源代码后,发现页面数据没有在源代码中,猜测应是js生成的。
检查元素后,刷新Network,可找到表格数据所在的URL:
https://www.zh12345.gov.cn/external/zf/getAllListView.do?pwType=1&type=1&callType=11&orgCode=-1

复制这条连接,在浏览器查看后,其内容如下:
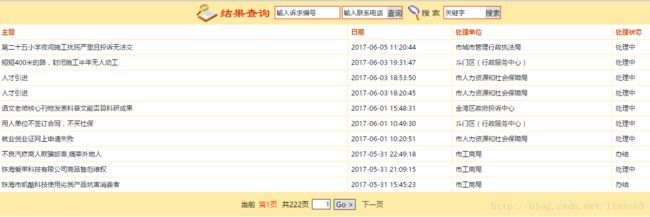
很好,接下来就是如何根据当前的链接得到下一页的数据信息,点击【下一页】,发现浏览器上方的URL却没有改变,依旧是
https://www.zh12345.gov.cn/external/zf/getAllListView.do?pwType=1&type=1&callType=11&orgCode=-1

那么对【下一页】这个地方检查元素试试:
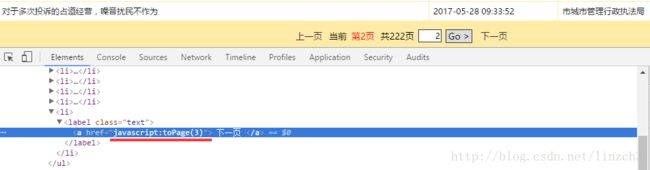
可以看到这里的翻页操作是使用【js】进行的。
虽然知道可以用selenium来模拟浏览器来实现点击效果,但是selenium也是出奇地慢,所以就不先使用它,而是尝试如下的方法。
——————————————-解决方法———————————————
google了之后,看到如下的资料:

看到这里,恍然大悟,与其在请求页面的时候选用post方式并携带data这里参数,那还不如就自己修改页面的链接:
https://www.zh12345.gov.cn/external/zf/getAllListView.do?pwType=1&type=1&callType=11&orgCode=-1
不过感觉,直接在上面的链接上加上page参数试试,得到下面的链接:
https://www.zh12345.gov.cn/external/zf/getAllListView.do?pwType=1&type=1&callType=11&orgCode=-1&page=1
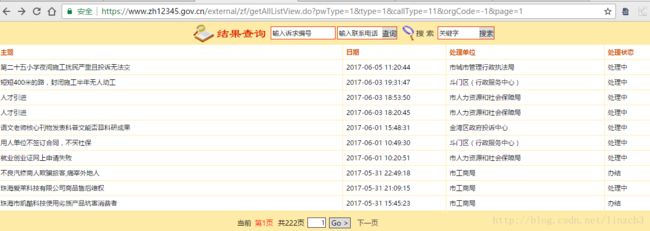
哇!竟然成功了!对比原网站数据,可发现这里记录的信息都是和原网站一样的。
看来以后遇到用js翻页的网站,可以试试自己修改其URL,说不定也可以这样成功“弱智而高效”地翻页。