Flink Kafka Connector分析
文章目录
- Flink Kafka Connector分析
- 1 FlinkKafkaConsumer
- 1.1 FlinkKafkaConsumerBase
- 1.2 AbstractPartitionDiscoverer
- 1.3 AbstractFetcher
- 1.4 KafkaConsumerThread
- 1.5 Handover
- 1.6 总结
- 2 FlinkKafkaProducer
Flink Kafka Connector分析
1 FlinkKafkaConsumer
Flink kafka consumer connector 是用来消费kafka数据到flink系统的连接器,作为flink系统的一个source存在。目前flink支持的kafka版本有0.8、0.9、0.10、0.11以及2.0+。由于目前我们使用的kafka版本是0.10.0.1,所以接下来主要基于0.10来分析。

上图是FlinkKafkaConsumer的继承关系图,我们关心的FlinkKafkaConsumer010是继承自FlinkKafkaConsumer09,并且FlinkKafkaConsumer010是一个RichFunction。它的基础类是FlinkKafkaConsumerBase,接下来我们开始分析FlinkKafkaConsumerBase
1.1 FlinkKafkaConsumerBase
FlinkKafkaConsumerBase是FlinkKafkaConsumer的基础类,也是非常核心的一个类,它除了继承自RichParallelSourceFunction,还实现了CheckpointedFunction和CheckpointListener这两个接口,主要用于checkpoint的快照保存和恢复以及快照完成后执行的回调。
public abstract class FlinkKafkaConsumerBase<T> extends RichParallelSourceFunction<T> implements
CheckpointListener,
ResultTypeQueryable<T>,
CheckpointedFunction
下面来看看FlinkKafkaConsumerBase里定义了哪些属性?
//FlinkKafkaConsumerBase
//pendingOffsetsToCommit中最多保存100个checkoint,超过会删除最旧的。
public static final int MAX_NUM_PENDING_CHECKPOINTS = 100;
//partition discovery开关,默认关闭
public static final long PARTITION_DISCOVERY_DISABLED = Long.MIN_VALUE;
//metrics开关
public static final String KEY_DISABLE_METRICS = "flink.disable-metrics";
//partition discovery 间隔时间的key
public static final String KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS = "flink.partition-discovery.interval-millis";
//partition-offset state的名字
private static final String OFFSETS_STATE_NAME = "topic-partition-offset-states";
//topic的描述,即:topic的名称
private final KafkaTopicsDescriptor topicsDescriptor;
//kafka消息反序列化的schema
protected final KafkaDeserializationSchema<T> deserializer;
//从指定offset位置开始订阅topic的分区
private Map<KafkaTopicPartition, Long> subscribedPartitionsToStartOffsets;
//周期性watermark分配器
private SerializedValue<AssignerWithPeriodicWatermarks<T>> periodicWatermarkAssigner;
//间隙性watermark分配器
private SerializedValue<AssignerWithPunctuatedWatermarks<T>> punctuatedWatermarkAssigner;
//基于checkpoint提交offset开关,默认打开
private boolean enableCommitOnCheckpoints = true;
//使用当前topic描述去过滤不匹配的分区(基于快照恢复时)
private boolean filterRestoredPartitionsWithCurrentTopicsDescriptor = true;
//offset提交模式:关闭/基于checkpoint提交/基于kafka周期性提交
private OffsetCommitMode offsetCommitMode;
//partition discovery 间隔时间
private final long discoveryIntervalMillis;
//从指定offset位置开始订阅topic的分区的模式:EARLIEST/LATEST/GROUP_OFFSETS/SPECIFIC_OFFSETS/TIMESTAMP,其中0.10.0.1版本不支持TIMESTAMP
private StartupMode startupMode = StartupMode.GROUP_OFFSETS;
//从指定特殊的offset位置开始订阅topic的分区
private Map<KafkaTopicPartition, Long> specificStartupOffsets;
//从指定特殊的时间对应的offset位置开始订阅topic的分区
private Long startupOffsetsTimestamp;
//记录正在进行的快照(即partition-offset的state)
private final LinkedMap pendingOffsetsToCommit = new LinkedMap();
//用于从kafka 拉取数据
private transient volatile AbstractFetcher<T, ?> kafkaFetcher;
//用于分区实时发现
private transient volatile AbstractPartitionDiscoverer partitionDiscoverer;
//基于该state恢复
private transient volatile TreeMap<KafkaTopicPartition, Long> restoredState;
//保存的partition-offset state,为union state
private transient ListState<Tuple2<KafkaTopicPartition, Long>> unionOffsetStates;
//是否支持从老的状态恢复,老状态是指Flink 1.1 or 1.2.的状态
private boolean restoredFromOldState;
//分区实时发现的线程
private transient volatile Thread discoveryLoopThread;
//运行标志
private volatile boolean running = true;
//mrtrics
private final boolean useMetrics;
private transient Counter successfulCommits;
private transient Counter failedCommits;
private transient KafkaCommitCallback offsetCommitCallback;
FlinkKafkaConsumerBase中暴露给用户的api包括assignTimestampsAndWatermarks、setStartFromEarliest、setStartFromLatest、disableFilterRestoredPartitionsWithSubscribedTopics等,主要用于watermark的设置以及从指定位置开始消费数据。
FlinkKafkaConsumerBase中最先执行的方法是initializeState,主要用于状态的初始化:
(1) 从上下文获取stateStore
(2) 从stateStore中获取状态,包括老状态(应该是为了兼容1.2版本)和新状态,如果有老状态,迁移到unionOffsetStates 中
(3) 将unionOffsetStates 插入到restoredState,用于恢复状态。
//FlinkKafkaConsumerBase
public final void initializeState(FunctionInitializationContext context) throws Exception {
OperatorStateStore stateStore = context.getOperatorStateStore();
//获取老版本的状态
ListState<Tuple2<KafkaTopicPartition, Long>> oldRoundRobinListState =
stateStore.getSerializableListState(DefaultOperatorStateBackend.DEFAULT_OPERATOR_STATE_NAME);
//从stateStore中获取状态,如果没有会创建。
this.unionOffsetStates = stateStore.getUnionListState(new ListStateDescriptor<>(
OFFSETS_STATE_NAME,
TypeInformation.of(new TypeHint<Tuple2<KafkaTopicPartition, Long>>() {})));
if (context.isRestored() && !restoredFromOldState) {
restoredState = new TreeMap<>(new KafkaTopicPartition.Comparator());
// 迁移老的状态到unionOffsetStates
for (Tuple2<KafkaTopicPartition, Long> kafkaOffset : oldRoundRobinListState.get()) {
restoredFromOldState = true;
unionOffsetStates.add(kafkaOffset);
}
oldRoundRobinListState.clear();
//存在老的状态并且partition discovery没有关闭
if (restoredFromOldState && discoveryIntervalMillis != PARTITION_DISCOVERY_DISABLED) {
//抛异常
}
// 将unionOffsetStates中的状态插入restoredState中
for (Tuple2<KafkaTopicPartition, Long> kafkaOffset : unionOffsetStates.get()) {
restoredState.put(kafkaOffset.f0, kafkaOffset.f1);
}
//log
} else {
//log
}
}
FlinkKafkaConsumerBase的open方法主要用于初始化,执行于initializeState方法之后,下面结合代码来看看具体流程:
(1) 初始化offsetCommitMode,在开启了checkpoint的情况下,如果enableCommitOnCheckpoint开启,则为ON_CHECKPOINTS,否则为DISABLED;如果未开启checkpoint,开启了自动提交offset,则为KAFKA_PERIODIC,否则为DISABLED。最后如果offsetCommitMode为ON_CHECKPOINTS或DISABLED,enable.auto.commit将被设置为false,具体是在adjustAutoCommitConfig方法中实现,比较简单。offsetCommitMode初始化完成后,接着初始化partitionDiscoverer,010创建的是Kafka010PartitionDiscoverer,然后调用AbstractPartitionDiscoverer的open方法,主要是初始化kafka consumer。
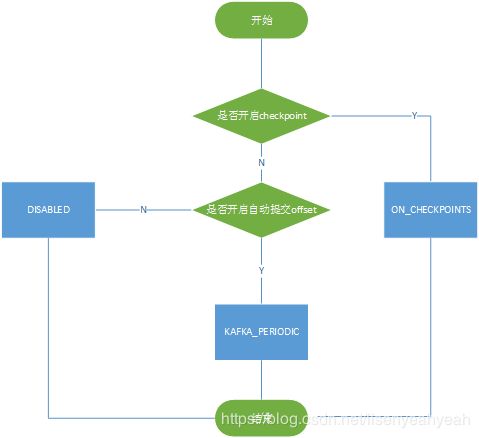
| offsetCommitMode | 描述 |
|---|---|
| DISABLED | 不开启offset提交 |
| ON_CHECKPOINTS | 确保checkpoint完成以后再提交offset到kafka |
| KAFKA_PERIODIC | 周期性的自动提交offset到kafka |
(2) 查找topic对应的所有分区,并初始化每个分区的消费位点,保存到subscribedPartitionsToStartOffsets中。
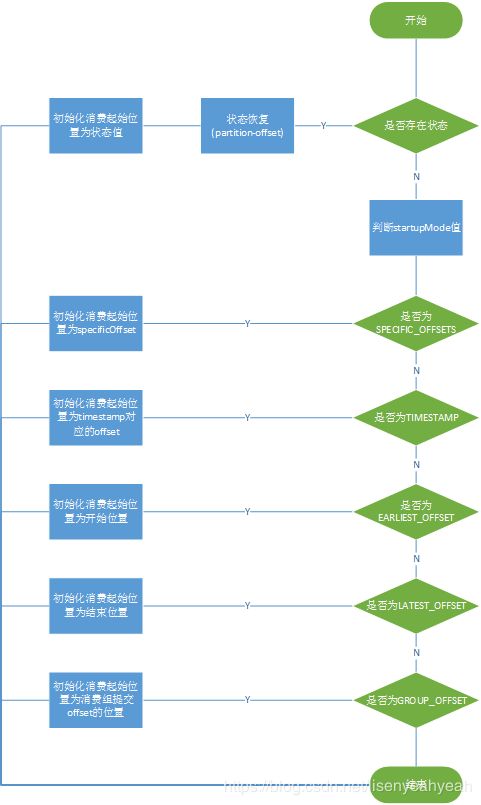
| startupMode | 描述 |
|---|---|
| GROUP_OFFSETS | 从该组最后提交的offset位置开始消费 |
| EARLIEST | 从开始位置开始消费 |
| LATEST | 从结束位置开始消费 |
| TIMESTAMP | 从指定时间戳对应的提交的offset位置开始消费 |
| SPECIFIC_OFFSETS | 从指定的offset位置开始消费 |
//FlinkKafkaConsumerBase
public void open(Configuration configuration) throws Exception {
// 初始化offsetCommitMode
this.offsetCommitMode = OffsetCommitModes.fromConfiguration(
getIsAutoCommitEnabled(),
enableCommitOnCheckpoints,
((StreamingRuntimeContext) getRuntimeContext()).isCheckpointingEnabled());
// 初始化partitionDiscoverer,并调用open方法
this.partitionDiscoverer = createPartitionDiscoverer(
topicsDescriptor,
getRuntimeContext().getIndexOfThisSubtask(),
getRuntimeContext().getNumberOfParallelSubtasks());
this.partitionDiscoverer.open();
subscribedPartitionsToStartOffsets = new HashMap<>();
// 查找topic的所有分区,后面介绍PartitionDiscoverer时会详细介绍
final List<KafkaTopicPartition> allPartitions = partitionDiscoverer.discoverPartitions();
// 如果从状态恢复
if (restoredState != null) {
for (KafkaTopicPartition partition : allPartitions) {
if (!restoredState.containsKey(partition)) {
//如果恢复的状态不包含该分区,则默认以EARLIEST开始消费,并插入restoredState
restoredState.put(partition, KafkaTopicPartitionStateSentinel.EARLIEST_OFFSET);
}
}
//遍历restoredState
for (Map.Entry<KafkaTopicPartition, Long> restoredStateEntry : restoredState.entrySet()) {
if (!restoredFromOldState) {
//不从老状态恢复,则分配给该task订阅的分区和offset,并插入subscribedPartitionsToStartOffsets
if (KafkaTopicPartitionAssigner.assign(
restoredStateEntry.getKey(), getRuntimeContext().getNumberOfParallelSubtasks())
== getRuntimeContext().getIndexOfThisSubtask()){
subscribedPartitionsToStartOffsets.put(restoredStateEntry.getKey(), restoredStateEntry.getValue());
}
} else {
// 老状态直接插入subscribedPartitionsToStartOffsets
subscribedPartitionsToStartOffsets.put(restoredStateEntry.getKey(), restoredStateEntry.getValue());
}
}
//过滤不匹配的分区
if (filterRestoredPartitionsWithCurrentTopicsDescriptor) {
subscribedPartitionsToStartOffsets.entrySet().removeIf(entry -> {
if (!topicsDescriptor.isMatchingTopic(entry.getKey().getTopic())) {
//log
return true;
}
return false;
});
}
//log
} else { // 不从状态恢复
switch (startupMode) {
//特殊offset恢复
case SPECIFIC_OFFSETS:
if (specificStartupOffsets == null) {
// throw IllegalStateException
}
for (KafkaTopicPartition seedPartition : allPartitions) {
Long specificOffset = specificStartupOffsets.get(seedPartition);
if (specificOffset != null) {
//从specificStartupOffsets中获取分区对应的offset并不为空,并插入subscribedPartitionsToStartOffsets,用于从此位置订阅分区。
subscribedPartitionsToStartOffsets.put(seedPartition, specificOffset - 1);
} else {
//从specificStartupOffsets中获取分区对应的offset为空,默认以GROUP_OFFSET方式订阅
subscribedPartitionsToStartOffsets.put(seedPartition, KafkaTopicPartitionStateSentinel.GROUP_OFFSET);
}
}
break;
//指定时间戳对应的offset恢复,适用于0.10.2+版本的kafka
case TIMESTAMP:
if (startupOffsetsTimestamp == null) {
//throw IllegalStateException
}
//查找时间戳对应的partition-offset,如果对应的offset为空,默认以LATEST_OFFSET方式订阅
for (Map.Entry<KafkaTopicPartition, Long> partitionToOffset
: fetchOffsetsWithTimestamp(allPartitions, startupOffsetsTimestamp).entrySet()) {
subscribedPartitionsToStartOffsets.put(
partitionToOffset.getKey(),
(partitionToOffset.getValue() == null)
? KafkaTopicPartitionStateSentinel.LATEST_OFFSET
: partitionToOffset.getValue() - 1);
}
break;
//否则以GROUP_OFFSET方式订阅
default:
for (KafkaTopicPartition seedPartition : allPartitions) {
subscribedPartitionsToStartOffsets.put(seedPartition, startupMode.getStateSentinel());
}
}
//log
}
}
初始化完成后,接下来就到了核心的run方法了,这才是实际的执行逻辑,下面来看看run方法做了些什么:
(1) 初始化metric,初始化offsetCommitCallback,创建kafkaFetcher
(2) 如果开启了PARTITION_DISCOVERY,启动partition discovery线程和fetch loop,否则仅启动fetch loop
//FlinkKafkaConsumerBase
public void run(SourceContext<T> sourceContext) throws Exception {
if (subscribedPartitionsToStartOffsets == null) {
//throw Exception
}
// 初始化successfulCommits和failedCommits这两个metric,省略
//获取当前subtask的index
final int subtaskIndex = this.getRuntimeContext().getIndexOfThisSubtask();
//初始化offsetCommitCallback,提交offset的回调函数,省略
// 如果subscribedPartitionsToStartOffsets为空,发送一个IDLE标记
if (subscribedPartitionsToStartOffsets.isEmpty()) {
sourceContext.markAsTemporarilyIdle();
}
//log
//创建Fetcher
this.kafkaFetcher = createFetcher(
sourceContext,
subscribedPartitionsToStartOffsets,
periodicWatermarkAssigner,
punctuatedWatermarkAssigner,
(StreamingRuntimeContext) getRuntimeContext(),
offsetCommitMode,
getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP),
useMetrics);
if (!running) {
return;
}
//如果PARTITION_DISCOVERY_DISABLED开启,执行kafkaFetcher的runFetchLoop,否则执行runWithPartitionDiscovery
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
kafkaFetcher.runFetchLoop();
} else {
runWithPartitionDiscovery();
}
}
//FlinkKafkaConsumerBase
private void runWithPartitionDiscovery() throws Exception {
final AtomicReference<Exception> discoveryLoopErrorRef = new AtomicReference<>();
// 创建并启动discorvery线程
createAndStartDiscoveryLoop(discoveryLoopErrorRef);
// 启动拉取数据的线程
kafkaFetcher.runFetchLoop();
// 将AbstractPartitionDiscoverer的wakeup置为true,并唤醒kafkaConsumer
partitionDiscoverer.wakeup();
// join discorvery线程
joinDiscoveryLoopThread();
// 如果discovery线程遇到错误,重新抛出RuntimeException
final Exception discoveryLoopError = discoveryLoopErrorRef.get();
if (discoveryLoopError != null) {
throw new RuntimeException(discoveryLoopError);
}
}
//FlinkKafkaConsumerBase
private void createAndStartDiscoveryLoop(AtomicReference<Exception> discoveryLoopErrorRef) {
discoveryLoopThread = new Thread(() -> {
try {
while (running) {
//log
final List<KafkaTopicPartition> discoveredPartitions;
try {
//寻找将要订阅的topic的分区,具体分析见AbstractPartitionDiscoverer
discoveredPartitions = partitionDiscoverer.discoverPartitions();
} catch (AbstractPartitionDiscoverer.WakeupException | AbstractPartitionDiscoverer.ClosedException e) {
break;
}
//添加到subscribedPartitionStates列表和unassignedPartitionsQueue队列中,具体分析见AbstractFetcher
if (running && !discoveredPartitions.isEmpty()) {
kafkaFetcher.addDiscoveredPartitions(discoveredPartitions);
}
if (running && discoveryIntervalMillis != 0) {
try {
Thread.sleep(discoveryIntervalMillis);
} catch (InterruptedException iex) {
break;
}
}
}
} catch (Exception e) {
discoveryLoopErrorRef.set(e);
} finally {
if (running) {
cancel();
}
}
}, "Kafka Partition Discovery for " + getRuntimeContext().getTaskNameWithSubtasks());
discoveryLoopThread.start();
}
run方法的整体流程图如下:

下面来看看执行快照的方法snapshotState,每次checkpoint的时候会调用:
// FlinkKafkaConsumerBase
public final void snapshotState(FunctionSnapshotContext context) throws Exception {
if (!running) {
//log
} else {
// 清空unionOffsetStates
unionOffsetStates.clear();
final AbstractFetcher<?, ?> fetcher = this.kafkaFetcher;
// 正常情况fetcher不为null,如果为null,就将subscribedPartitionsToStartOffsets保存到unionOffsetStates
if (fetcher == null) {
// 用subscribedPartitionsToStartOffsets更新unionOffsetStates,并将restoredState加入待提交map中
for (Map.Entry<KafkaTopicPartition, Long> subscribedPartition : subscribedPartitionsToStartOffsets.entrySet()) {
unionOffsetStates.add(Tuple2.of(subscribedPartition.getKey(), subscribedPartition.getValue()));
}
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
pendingOffsetsToCommit.put(context.getCheckpointId(), restoredState);
}
} else {
HashMap<KafkaTopicPartition, Long> currentOffsets = fetcher.snapshotCurrentState();
// 用subscribedPartitionStates更新unionOffsetStates,并将subscribedPartitionStates加入待提交map中
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets);
}
for (Map.Entry<KafkaTopicPartition, Long> kafkaTopicPartitionLongEntry : currentOffsets.entrySet()) {
unionOffsetStates.add(
Tuple2.of(kafkaTopicPartitionLongEntry.getKey(), kafkaTopicPartitionLongEntry.getValue()));
}
}
// pendingOffsetsToCommit如果超过100个,删除最老的一个,防止OOM
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
while (pendingOffsetsToCommit.size() > MAX_NUM_PENDING_CHECKPOINTS) {
pendingOffsetsToCommit.remove(0);
}
}
}
}
当全局checkpoint完成后,会调用notifyCheckpointComplete方法,这就是两阶段提交中的Pre-Commit
// FlinkKafkaConsumerBase
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
if (!running) {
// log
return;
}
final AbstractFetcher<?, ?> fetcher = this.kafkaFetcher;
if (fetcher == null) {
// log debug
return;
}
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
// log debug
try {
// 查找checkpointId在pendingOffsetsToCommit中的位置
final int posInMap = pendingOffsetsToCommit.indexOf(checkpointId);
if (posInMap == -1) {
// log
return;
}
@SuppressWarnings("unchecked")
// 根据checkpointId查找pendingOffsetsToCommit中的partition-offset,也就是待提交的offset,记录到offsets中,并从pendingOffsetsToCommit中删除
Map<KafkaTopicPartition, Long> offsets =
(Map<KafkaTopicPartition, Long>) pendingOffsetsToCommit.remove(posInMap);
// remove older checkpoints in map
for (int i = 0; i < posInMap; i++) {
pendingOffsetsToCommit.remove(0);
}
if (offsets == null || offsets.size() == 0) {
// log debug
return;
}
// 将offsets提交至kafka,完成Pre-Commit
fetcher.commitInternalOffsetsToKafka(offsets, offsetCommitCallback);
} catch (Exception e) {
if (running) {
throw e;
}
// else ignore exception if we are no longer running
}
}
}
// AbstractFetcher
public final void commitInternalOffsetsToKafka(
Map<KafkaTopicPartition, Long> offsets,
@Nonnull KafkaCommitCallback commitCallback) throws Exception {
// 通过filterOutSentinels过滤小于0的offset,执行doCommit
doCommitInternalOffsetsToKafka(filterOutSentinels(offsets), commitCallback);
}
// Kafka09Fetcher
protected void doCommitInternalOffsetsToKafka(
Map<KafkaTopicPartition, Long> offsets,
@Nonnull KafkaCommitCallback commitCallback) throws Exception {
@SuppressWarnings("unchecked")
// 获取partitions state,即subscribedPartitionStates,在AbstractFetcher的属性中有解释
List<KafkaTopicPartitionState<TopicPartition>> partitions = subscribedPartitionStates();
Map<TopicPartition, OffsetAndMetadata> offsetsToCommit = new HashMap<>(partitions.size());
// 遍历partitions,提取上次最后处理的offset并插入offsetsToCommit,并将offsetsToCommit保存到state中
for (KafkaTopicPartitionState<TopicPartition> partition : partitions) {
Long lastProcessedOffset = offsets.get(partition.getKafkaTopicPartition());
if (lastProcessedOffset != null) {
checkState(lastProcessedOffset >= 0, "Illegal offset value to commit");
long offsetToCommit = lastProcessedOffset + 1;
offsetsToCommit.put(partition.getKafkaPartitionHandle(), new OffsetAndMetadata(offsetToCommit));
partition.setCommittedOffset(offsetToCommit);
}
}
// 将offsetsToCommit插入nextOffsetsToCommit中等待异步提交
consumerThread.setOffsetsToCommit(offsetsToCommit, commitCallback);
}
// KafkaConsumerThread
void setOffsetsToCommit(
Map<TopicPartition, OffsetAndMetadata> offsetsToCommit,
@Nonnull KafkaCommitCallback commitCallback) {
// 将offsetsToCommit插入nextOffsetsToCommit中
if (nextOffsetsToCommit.getAndSet(Tuple2.of(offsetsToCommit, commitCallback)) != null) {
// log warn
}
handover.wakeupProducer();
synchronized (consumerReassignmentLock) {
if (consumer != null) {
// 调用consumer的wakeup
consumer.wakeup();
} else {
// 设置hasBufferedWakeup为true
hasBufferedWakeup = true;
}
}
}
在open方法中通过partitionDiscoverer.discoverPartitions()来获取topic的所有分区,其中partitionDiscoverer就是AbstractPartitionDiscoverer。同时上面提到了kafkaFetcher,其抽象类是AbstractFetcher,作用是去拉取kafka数据,下面我们依次详细分析下AbstractPartitionDiscoverer和AbstractFetcher这两个核心类。
1.2 AbstractPartitionDiscoverer
AbstractPartitionDiscoverer是抽象类,作用是去寻找topic的分区,下面我们结合源码来看看具体实现:

首先还是来看看AbstractPartitionDiscoverer的属性
//AbstractPartitionDiscoverer
// topic描述,即:topic名称
private final KafkaTopicsDescriptor topicsDescriptor;
// 当前subtask的index
private final int indexOfThisSubtask;
// 总的subtask个数,即:并行度
private final int numParallelSubtasks;
// closed标志
private volatile boolean closed = true;
// wakeup标志
private volatile boolean wakeup;
// 该subtask分配的分区集合,即:该subtask将要订阅的分区
private Set<KafkaTopicPartition> discoveredPartitions;
AbstractPartitionDiscoverer最核心的方法是discoverPartitions,作用是发现分区:
(1) 获取topic对应的所有分区
(2) 通过KafkaTopicPartitionAssigner定义的算法来决定当前subtask需要订阅的分区集合newDiscoveredPartitions,算法原理是分区对应topic的hash和并行度取余的结果加上分区编号再和并行度取余的结果如果和当前subtask编号相同,则该分区被该subtask订阅。
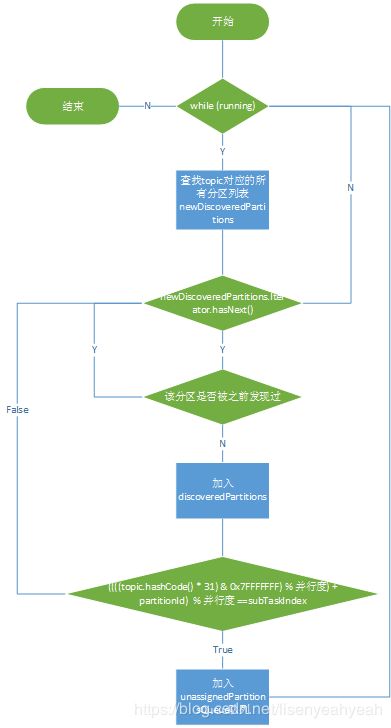
//AbstractPartitionDiscoverer
public List<KafkaTopicPartition> discoverPartitions() throws WakeupException, ClosedException {
// 非closed并且非wakeup
if (!closed && !wakeup) {
try {
List<KafkaTopicPartition> newDiscoveredPartitions;
// topic为具体的全称而非正则匹配,直接调用getAllPartitionsForTopics来获取所有分区
if (topicsDescriptor.isFixedTopics()) {
newDiscoveredPartitions = getAllPartitionsForTopics(topicsDescriptor.getFixedTopics());
} else {
// topic为正则匹配的表达式,先匹配出所有符合条件的topic列表,然后调用getAllPartitionsForTopics来获取所有分区
List<String> matchedTopics = getAllTopics();
Iterator<String> iter = matchedTopics.iterator();
while (iter.hasNext()) {
if (!topicsDescriptor.isMatchingTopic(iter.next())) {
iter.remove();
}
}
if (matchedTopics.size() != 0) {
newDiscoveredPartitions = getAllPartitionsForTopics(matchedTopics);
} else {
newDiscoveredPartitions = null;
}
}
if (newDiscoveredPartitions == null || newDiscoveredPartitions.isEmpty()) {
//throw RuntimeException
} else {
Iterator<KafkaTopicPartition> iter = newDiscoveredPartitions.iterator();
KafkaTopicPartition nextPartition;
while (iter.hasNext()) {
nextPartition = iter.next();
// 检查新发现的分区,不符合要求的过滤掉
if (!setAndCheckDiscoveredPartition(nextPartition)) {
iter.remove();
}
}
}
// 返回符合该subtask的分区,用来订阅。
return newDiscoveredPartitions;
} catch (WakeupException e) {
wakeup = false;
throw e;
}
} else if (!closed && wakeup) {
wakeup = false;
throw new WakeupException();
} else {
throw new ClosedException();
}
}
注意:下面调用partitionsFor方法之前或期间如果调用了kafkaConsumer的wakeup方法,会抛出WakeupException
// Kafka09PartitionDiscoverer
protected List<KafkaTopicPartition> getAllPartitionsForTopics(List<String> topics) throws WakeupException {
List<KafkaTopicPartition> partitions = new LinkedList<>();
try {
// 直接调用kafkaConsumer的partitionsFor方法获取topic的所有分区
for (String topic : topics) {
for (PartitionInfo partitionInfo : kafkaConsumer.partitionsFor(topic)) {
partitions.add(new KafkaTopicPartition(partitionInfo.topic(), partitionInfo.partition()));
}
}
} catch (org.apache.kafka.common.errors.WakeupException e) {
// throw WakeupException();
}
return partitions;
}
// AbstractPartitionDiscoverer
public boolean setAndCheckDiscoveredPartition(KafkaTopicPartition partition) {
if (isUndiscoveredPartition(partition)) {
discoveredPartitions.add(partition);
//通过KafkaTopicPartitionAssigner来分配该subtask应该订阅的topic-partition
return KafkaTopicPartitionAssigner.assign(partition, numParallelSubtasks) == indexOfThisSubtask;
}
return false;
}
//是否是之前未发现的分区,之前发现的会存到discoveredPartitions中
private boolean isUndiscoveredPartition(KafkaTopicPartition partition) {
return !discoveredPartitions.contains(partition);
}
// KafkaTopicPartitionAssigner
public static int assign(KafkaTopicPartition partition, int numParallelSubtasks) {
// partition对应topic的hash值和并行度取余得到startIndex
int startIndex = ((partition.getTopic().hashCode() * 31) & 0x7FFFFFFF) % numParallelSubtasks;
// startIndex加分区编号和并行度取余的结果决定当前分区应该被哪个subtask订阅
return (startIndex + partition.getPartition()) % numParallelSubtasks;
}
1.3 AbstractFetcher
AbstractFetcher也是kafka connector非常核心的类,作用是从kafka中poll数据并发送给下游,首先上它的继承关系图:

接下来看看它的属性:
// AbstractFetcher
// source上下文
protected final SourceContext<T> sourceContext;
// checkpoint锁
private final Object checkpointLock;
// 订阅分区的状态,包括分区、消费到的offset、成功提交的offset等
private final List<KafkaTopicPartitionState<KPH>> subscribedPartitionStates;
// 未分配的分区队列,上面discoverPartitions方法的返回值会插入该队列
protected final ClosableBlockingQueue<KafkaTopicPartitionState<KPH>> unassignedPartitionsQueue;
// watermark模式:NO_TIMESTAMPS_WATERMARKS/PERIODIC_WATERMARKS/PUNCTUATED_WATERMARKS
private final int timestampWatermarkMode;
// 周期性watermark分配器
private final SerializedValue<AssignerWithPeriodicWatermarks<T>> watermarksPeriodic;
// 间隙性watermark分配器
private final SerializedValue<AssignerWithPunctuatedWatermarks<T>> watermarksPunctuated;
// 用户代码类加载器
private final ClassLoader userCodeClassLoader;
// 间隙性watermark阈值
private volatile long maxWatermarkSoFar = Long.MIN_VALUE;
// Metrics
private final boolean useMetrics;
private final MetricGroup consumerMetricGroup;
private final MetricGroup legacyCurrentOffsetsMetricGroup;
private final MetricGroup legacyCommittedOffsetsMetricGroup;
AbstractFetcher的构造方法做了很多初始化的工作,包括watermark、metric以及状态相关,我们主要看看subscribedPartitionStates和unassignedPartitionsQueue的初始化
protected AbstractFetcher(
SourceContext<T> sourceContext,
Map<KafkaTopicPartition, Long> seedPartitionsWithInitialOffsets,//即FlinkKafkaConsumerBase中的subscribedPartitionsToStartOffsets,初始化partition-offset对应关系
SerializedValue<AssignerWithPeriodicWatermarks<T>> watermarksPeriodic,
SerializedValue<AssignerWithPunctuatedWatermarks<T>> watermarksPunctuated,
ProcessingTimeService processingTimeProvider,
long autoWatermarkInterval,
ClassLoader userCodeClassLoader,
MetricGroup consumerMetricGroup,
boolean useMetrics) throws Exception {
//创建分区状态的句柄
this.subscribedPartitionStates = createPartitionStateHolders(
seedPartitionsWithInitialOffsets,
timestampWatermarkMode,
watermarksPeriodic,
watermarksPunctuated,
userCodeClassLoader);
//将subscribedPartitionStates插入unassignedPartitionsQueue中
for (KafkaTopicPartitionState<KPH> partition : subscribedPartitionStates) {
unassignedPartitionsQueue.add(partition);
}
}
//AbstractFetcher
private List<KafkaTopicPartitionState<KPH>> createPartitionStateHolders(
Map<KafkaTopicPartition, Long> partitionsToInitialOffsets,
int timestampWatermarkMode,
SerializedValue<AssignerWithPeriodicWatermarks<T>> watermarksPeriodic,
SerializedValue<AssignerWithPunctuatedWatermarks<T>> watermarksPunctuated,
ClassLoader userCodeClassLoader) throws IOException, ClassNotFoundException {
List<KafkaTopicPartitionState<KPH>> partitionStates = new CopyOnWriteArrayList<>();
switch (timestampWatermarkMode) {
case NO_TIMESTAMPS_WATERMARKS: {
for (Map.Entry<KafkaTopicPartition, Long> partitionEntry : partitionsToInitialOffsets.entrySet()) {
// handle:topic-partition
KPH kafkaHandle = createKafkaPartitionHandle(partitionEntry.getKey());
// partitionEntry.getKey()和kafkaHandle不是一样的吗?不明白为啥都封装到partitionState 里
KafkaTopicPartitionState<KPH> partitionState =
new KafkaTopicPartitionState<>(partitionEntry.getKey(), kafkaHandle);
// 设置订阅的起始offset
partitionState.setOffset(partitionEntry.getValue());
partitionStates.add(partitionState);
}
return partitionStates;
}
case PERIODIC_WATERMARKS: {
for (Map.Entry<KafkaTopicPartition, Long> partitionEntry : partitionsToInitialOffsets.entrySet()) {
KPH kafkaHandle = createKafkaPartitionHandle(partitionEntry.getKey());
AssignerWithPeriodicWatermarks<T> assignerInstance =
watermarksPeriodic.deserializeValue(userCodeClassLoader);
// partitionState: topic-partition、watermark assigner、offset
KafkaTopicPartitionStateWithPeriodicWatermarks<T, KPH> partitionState =
new KafkaTopicPartitionStateWithPeriodicWatermarks<>(
partitionEntry.getKey(),
kafkaHandle,
assignerInstance);
partitionState.setOffset(partitionEntry.getValue());
partitionStates.add(partitionState);
}
return partitionStates;
}
case PUNCTUATED_WATERMARKS: {
for (Map.Entry<KafkaTopicPartition, Long> partitionEntry : partitionsToInitialOffsets.entrySet()) {
KPH kafkaHandle = createKafkaPartitionHandle(partitionEntry.getKey());
AssignerWithPunctuatedWatermarks<T> assignerInstance =
watermarksPunctuated.deserializeValue(userCodeClassLoader);
// partitionState: topic-partition、watermark assigner、offset
KafkaTopicPartitionStateWithPunctuatedWatermarks<T, KPH> partitionState =
new KafkaTopicPartitionStateWithPunctuatedWatermarks<>(
partitionEntry.getKey(),
kafkaHandle,
assignerInstance);
partitionState.setOffset(partitionEntry.getValue());
partitionStates.add(partitionState);
}
return partitionStates;
}
default:
throw new RuntimeException();
}
}
addDiscoveredPartitions方法是将新发现的partition加入到subscribedPartitionStates列表和unassignedPartitionsQueue队列中
public void addDiscoveredPartitions(List<KafkaTopicPartition> newPartitions) throws IOException, ClassNotFoundException {
List<KafkaTopicPartitionState<KPH>> newPartitionStates = createPartitionStateHolders(
newPartitions,
KafkaTopicPartitionStateSentinel.EARLIEST_OFFSET,
timestampWatermarkMode,
watermarksPeriodic,
watermarksPunctuated,
userCodeClassLoader);
if (useMetrics) {
registerOffsetMetrics(consumerMetricGroup, newPartitionStates);
}
for (KafkaTopicPartitionState<KPH> newPartitionState : newPartitionStates) {
subscribedPartitionStates.add(newPartitionState);
unassignedPartitionsQueue.add(newPartitionState);
}
}
在FlinkKafkaConsumerBase中会调用Fetcher的runFetchLoop方法,runFetchLoop在AbstractFetcher是一个抽象方法,具体由子类去实现,我们关心的是Kafka09Fetcher的runFetchLoop实现,Kafka10Fetcher用的也是Kafka09Fetcher的runFetchLoop,它自己没有实现该方法,接下来我们看看这个方法做了什么?
// 反序列化数据的schema
private final KafkaDeserializationSchema<T> deserializer;
// 在consumer thread和task thread之间进行数据和异常交换
private final Handover handover;
// consumer thread
private final KafkaConsumerThread consumerThread;
// 运行标志
private volatile boolean running = true;
(1) 启动consumerThread线程
(2) 从handover拉取一批数据并发往下游
// Kafka09Fetcher
public void runFetchLoop() throws Exception {
try {
final Handover handover = this.handover;
// 启动consumer thread
consumerThread.start();
while (running) {
// poll一批数据
final ConsumerRecords<byte[], byte[]> records = handover.pollNext();
// 遍历subscribedPartitionStates中的所有分区
for (KafkaTopicPartitionState<TopicPartition> partition : subscribedPartitionStates()) {
// 获取partition 对应的records并转为ConsumerRecord列表
List<ConsumerRecord<byte[], byte[]>> partitionRecords =
records.records(partition.getKafkaPartitionHandle());
// 遍历partitionRecords
for (ConsumerRecord<byte[], byte[]> record : partitionRecords) {
// 反序列化
final T value = deserializer.deserialize(record);
// 流的isEndOfStream默认为false,批的我们暂不关心
if (deserializer.isEndOfStream(value)) {
running = false;
break;
}
// 发送到下游,最终调用sourceContext.collectWithTimestamp(T element, long timestamp)方法,对于无watermark/周期性watermark/间隙性watermark有点区别,区别在于传的timestamp不一样。
emitRecord(value, partition, record.offset(), record);
}
}
}
}
finally {
//shutdown
consumerThread.shutdown();
}
try {
// 等待consumerThread运行结束
consumerThread.join();
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
// Kafka010Fetcher
protected void emitRecord(
T record,
KafkaTopicPartitionState<TopicPartition> partition,
long offset,
ConsumerRecord<?, ?> consumerRecord) throws Exception {
emitRecordWithTimestamp(record, partition, offset, consumerRecord.timestamp());
}
//AbstractFetcher
protected void emitRecordWithTimestamp(
T record, KafkaTopicPartitionState<KPH> partitionState, long offset, long timestamp) throws Exception {
if (record != null) {
if (timestampWatermarkMode == NO_TIMESTAMPS_WATERMARKS) {
synchronized (checkpointLock) {
// 发往下游
sourceContext.collectWithTimestamp(record, timestamp);
// 更新partitionState中对应分区的offset
partitionState.setOffset(offset);
}
} else if (timestampWatermarkMode == PERIODIC_WATERMARKS) {
emitRecordWithTimestampAndPeriodicWatermark(record, partitionState, offset, timestamp);
} else {
emitRecordWithTimestampAndPunctuatedWatermark(record, partitionState, offset, timestamp);
}
} else {
synchronized (checkpointLock) {
partitionState.setOffset(offset);
}
}
}
接下来看看consumerThread线程干了些啥?
1.4 KafkaConsumerThread

//KafkaConsumerThread
// 在consumer thread和task thread之间进行数据和异常交换
private final Handover handover;
// 下一次待提交的offsets
private final AtomicReference<Tuple2<Map<TopicPartition, OffsetAndMetadata>, KafkaCommitCallback>> nextOffsetsToCommit;
// kafka消费者配置
private final Properties kafkaProperties;
// 未分配的partition队列
private final ClosableBlockingQueue<KafkaTopicPartitionState<TopicPartition>> unassignedPartitionsQueue;
// bridge,定义了订阅分区assign方法,以及seekToBeginning和seekToEnd方法
private final KafkaConsumerCallBridge09 consumerCallBridge;
// poll超时时间,超过这个时间拉取不到数据将返回
private final long pollTimeout;
// kafka consumer
private volatile KafkaConsumer<byte[], byte[]> consumer;
// consumer锁,kafka consumer是线程不安全的
private final Object consumerReassignmentLock;
// 存在待分配的分区
private boolean hasAssignedPartitions;
// wakeup标志
private volatile boolean hasBufferedWakeup;
// 运行标志
private volatile boolean running;
// offset提交中的标志
private volatile boolean commitInProgress;
//?
private FlinkConnectorRateLimiter rateLimiter;
//metrics
private final boolean useMetrics;
private final MetricGroup subtaskMetricGroup;
private final MetricGroup consumerMetricGroup;
它的构造方法主要用于初始化部分属性,接下来我们看看run方法
(1) 初始化kafka consumer
(2) 设置kafka metric等信息
(3) 如果开启了checkpoint并且没有正在进行offset提交,则异步提交offset到kafka
(4) 从unassignedPartitionsQueue拉取待订阅的分区,订阅拉取到的分区并将初始位点重置到指定位置
(5) 调用consumer.poll拉取一批消息发送到handover
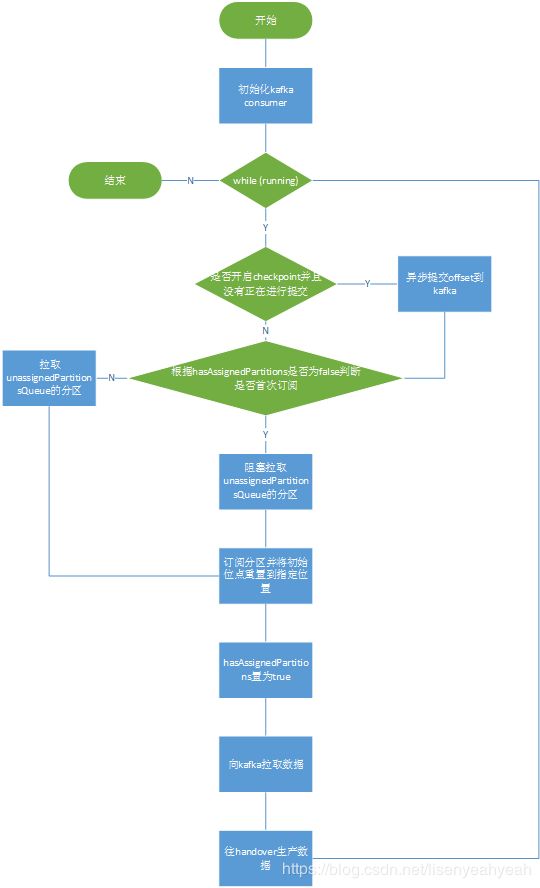
public void run() {
// 运行标志不为true,直接返回,running初始化为true,shutdown会将running置为false。
if (!running) {
return;
}
final Handover handover = this.handover;
try {
// 初始化kafka consumer
this.consumer = getConsumer(kafkaProperties);
}
catch (Throwable t) {
// 遇到异常汇报错误并返回
handover.reportError(t);
return;
}
try {
if (useMetrics) {
//metrics
}
// 再次检查running标志
if (!running) {
return;
}
ConsumerRecords<byte[], byte[]> records = null;
List<KafkaTopicPartitionState<TopicPartition>> newPartitions;
// 死循环,遇到异常或正常shutdown才退出
while (running) {
// 没有进行offset commit的时候进入
if (!commitInProgress) {
// 只有开启checkpoint的时候nextOffsetsToCommit才能get到值
final Tuple2<Map<TopicPartition, OffsetAndMetadata>, KafkaCommitCallback> commitOffsetsAndCallback =
nextOffsetsToCommit.getAndSet(null);
// 开启checkpoint才会进入
if (commitOffsetsAndCallback != null) {
commitInProgress = true;
// 异步提交offset
consumer.commitAsync(commitOffsetsAndCallback.f0, new CommitCallback(commitOffsetsAndCallback.f1));
}
}
try {
// caseB 后面发现分区,比如新增了分区,不阻塞拉取分区
if (hasAssignedPartitions) {
newPartitions = unassignedPartitionsQueue.pollBatch();
}
// caseA 首次订阅,会获取所有分区,阻塞拉取分区
else {
newPartitions = unassignedPartitionsQueue.getBatchBlocking();
}
if (newPartitions != null) {
// 分配并订阅分区
reassignPartitions(newPartitions);
}
} catch (AbortedReassignmentException e) {
continue;
}
if (!hasAssignedPartitions) {
continue;
}
if (records == null) {
try {
// 拉取数据
records = getRecordsFromKafka();
}
catch (WakeupException we) {
continue;
}
}
try {
// 将records插入handover中
handover.produce(records);
records = null;
}
catch (Handover.WakeupException e) {
// fall through the loop
}
}
// end main fetch loop
}
catch (Throwable t) {
handover.reportError(t);
}
finally {
handover.close();
if (rateLimiter != null) {
rateLimiter.close();
}
try {
consumer.close();
}
catch (Throwable t) {
// log
}
}
}
reassignPartitions的作用是在之前订阅的分区基础上再增加订阅newPartitions
// KafkaConsumerThread
void reassignPartitions(List<KafkaTopicPartitionState<TopicPartition>> newPartitions) throws Exception {
// 如果newPartitions大小为0,直接返回
if (newPartitions.size() == 0) {
return;
}
// 设置hasAssignedPartitions为true,标记不是首次reassign
hasAssignedPartitions = true;
boolean reassignmentStarted = false;
// 临时consumer
final KafkaConsumer<byte[], byte[]> consumerTmp;
synchronized (consumerReassignmentLock) {
// 将consumer赋给consumerTmp,将consumer置为null,这里为什么要用tmp来交换呢?
consumerTmp = this.consumer;
this.consumer = null;
}
//获取已经订阅过的partition,一开始应该为空
final Map<TopicPartition, Long> oldPartitionAssignmentsToPosition = new HashMap<>();
try {
for (TopicPartition oldPartition : consumerTmp.assignment()) {
oldPartitionAssignmentsToPosition.put(oldPartition, consumerTmp.position(oldPartition));
}
final List<TopicPartition> newPartitionAssignments =
new ArrayList<>(newPartitions.size() + oldPartitionAssignmentsToPosition.size());
newPartitionAssignments.addAll(oldPartitionAssignmentsToPosition.keySet());
// 添加新发现的partition,一开始应该是所有partition
newPartitionAssignments.addAll(convertKafkaPartitions(newPartitions));
// 订阅老的partition和新发现的partition
consumerCallBridge.assignPartitions(consumerTmp, newPartitionAssignments);
// 标记订阅已经开始
reassignmentStarted = true;
for (Map.Entry<TopicPartition, Long> oldPartitionToPosition : oldPartitionAssignmentsToPosition.entrySet()) {
// 对于之前已经订阅过的partition,还是恢复到上次的offset
consumerTmp.seek(oldPartitionToPosition.getKey(), oldPartitionToPosition.getValue());
}
//对于新的partition,根据待消费的offset来定位到起始消费位置
for (KafkaTopicPartitionState<TopicPartition> newPartitionState : newPartitions) {
if (newPartitionState.getOffset() == KafkaTopicPartitionStateSentinel.EARLIEST_OFFSET) {
consumerCallBridge.seekPartitionToBeginning(consumerTmp, newPartitionState.getKafkaPartitionHandle());
newPartitionState.setOffset(consumerTmp.position(newPartitionState.getKafkaPartitionHandle()) - 1);
} else if (newPartitionState.getOffset() == KafkaTopicPartitionStateSentinel.LATEST_OFFSET) {
consumerCallBridge.seekPartitionToEnd(consumerTmp, newPartitionState.getKafkaPartitionHandle());
newPartitionState.setOffset(consumerTmp.position(newPartitionState.getKafkaPartitionHandle()) - 1);
} else if (newPartitionState.getOffset() == KafkaTopicPartitionStateSentinel.GROUP_OFFSET) {
newPartitionState.setOffset(consumerTmp.position(newPartitionState.getKafkaPartitionHandle()) - 1);
} else {
consumerTmp.seek(newPartitionState.getKafkaPartitionHandle(), newPartitionState.getOffset() + 1);
}
}
} catch (WakeupException e) {
// 遇到异常就回滚,还是消费之前老的分区并定位到上次的位置,新的分区等待下一次再订阅。
synchronized (consumerReassignmentLock) {
this.consumer = consumerTmp;
if (reassignmentStarted) {
consumerCallBridge.assignPartitions(
this.consumer, new ArrayList<>(oldPartitionAssignmentsToPosition.keySet()));
for (Map.Entry<TopicPartition, Long> oldPartitionToPosition : oldPartitionAssignmentsToPosition.entrySet()) {
this.consumer.seek(oldPartitionToPosition.getKey(), oldPartitionToPosition.getValue());
}
}
hasBufferedWakeup = false;
for (KafkaTopicPartitionState<TopicPartition> newPartition : newPartitions) {
unassignedPartitionsQueue.add(newPartition);
}
throw new AbortedReassignmentException();
}
}
//将consumerTmp赋给consumer
synchronized (consumerReassignmentLock) {
this.consumer = consumerTmp;
if (hasBufferedWakeup) {
this.consumer.wakeup();
hasBufferedWakeup = false;
}
}
}
// KafkaConsumerThread
protected ConsumerRecords<byte[], byte[]> getRecordsFromKafka() {
// 拉取一批数据
ConsumerRecords<byte[], byte[]> records = consumer.poll(pollTimeout);
// rateLimiter 是用来限流的,目前还未启用,rateLimiter为null
if (rateLimiter != null) {
int bytesRead = getRecordBatchSize(records);
rateLimiter.acquire(bytesRead);
}
return records;
}
private int getRecordBatchSize(ConsumerRecords<byte[], byte[]> records) {
int recordBatchSizeBytes = 0;
for (ConsumerRecord<byte[], byte[]> record: records) {
if (record.key() != null) {
recordBatchSizeBytes += record.key().length;
}
recordBatchSizeBytes += record.value().length;
}
return recordBatchSizeBytes;
}
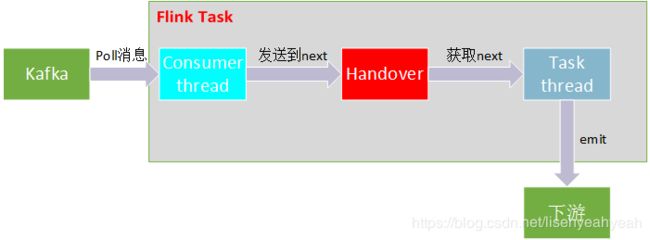
上面多次用到Handover,比如从kafka拉取一批数据后,是直接发到Handover中,Kafka09Fetcher中拉取数据也是从Handover中拉取。KafkaConsumerThread线程中遇到异常也是通过向Handover汇报。下面就来分析下Handover。
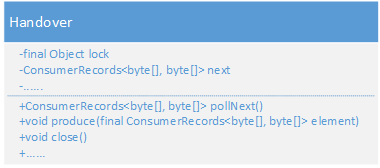
1.5 Handover
Handover的作用是对consumer thread和task thread之间进行数据和异常交换
//Handover
// 对象锁
private final Object lock = new Object();
// 一批数据
private ConsumerRecords<byte[], byte[]> next;
// 异常
private Throwable error;
// wakeup标志
private boolean wakeupProducer;
核心的方法是produce和pollNext,分别用来生产数据和消费数据,中间通过next来保存数据,其中KafkaConsumerThread会调用produce,Kafka09Fetcher的runFetchLoop方法会调用pollNext,也就是task线程,这样Handover就成了两个线程之间的桥梁。
//Handover
public void produce(final ConsumerRecords<byte[], byte[]> element)
throws InterruptedException, WakeupException, ClosedException {
//判空
checkNotNull(element);
synchronized (lock) {
// 如果next为空并且没有wakeup,锁等待
while (next != null && !wakeupProducer) {
lock.wait();
}
wakeupProducer = false;
if (next != null) {
throw new WakeupException();
}
// next为null,将element赋给next
else if (error == null) {
next = element;
lock.notifyAll();
}
else {
throw new ClosedException();
}
}
}
public ConsumerRecords<byte[], byte[]> pollNext() throws Exception {
synchronized (lock) {
while (next == null && error == null) {
lock.wait();
}
ConsumerRecords<byte[], byte[]> n = next;
if (n != null) {
// 拉取到数据,将next置为null,并返回拉取到的数据
next = null;
lock.notifyAll();
return n;
}
else {
ExceptionUtils.rethrowException(error, error.getMessage());
return ConsumerRecords.empty();
}
}
}
1.6 总结
本章主要介绍了FlinkKafkaConsumerBase是如何从kafka拉取消息并发往下游的,其run方法是执行在Task线程中的,同时会启动两个子线程,分别是consumer thread和discovery thread,启动discovery thread需要通过设置flink.partition-discovery.interval-millis参数来开启,作用是周期检测是否有新的分区需要订阅。consumer thread的作用是从kafka拉取数据。线程之间的交互图如下所示:

2 FlinkKafkaProducer
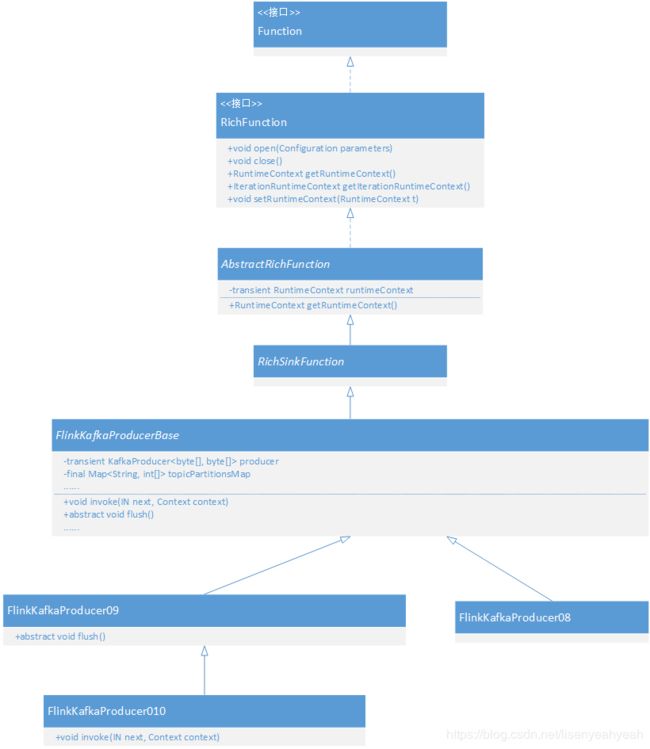
FlinkKafkaProducer010相对FlinkKafkaConsumer010从实现上来说简单很多,主要方法是invoke,FlinkKafkaProducer011相对复杂一些,因为支持了事务提交,可以保证EXACTLY-ONCE语义。下面我们先来看看FlinkKafkaProducer010的继承关系:
//FlinkKafkaProducer010
//是否需要写入时间到kafka
private boolean writeTimestampToKafka = false;
public void invoke(T value, Context context) throws Exception {
//检查错误
checkErroneous();
byte[] serializedKey = schema.serializeKey(value);
byte[] serializedValue = schema.serializeValue(value);
String targetTopic = schema.getTargetTopic(value);
if (targetTopic == null) {
targetTopic = defaultTopicId;
}
Long timestamp = null;
if (this.writeTimestampToKafka) {
timestamp = context.timestamp();
}
ProducerRecord<byte[], byte[]> record;
int[] partitions = topicPartitionsMap.get(targetTopic);
if (null == partitions) {
partitions = getPartitionsByTopic(targetTopic, producer);
topicPartitionsMap.put(targetTopic, partitions);
}
// 构造record
if (flinkKafkaPartitioner == null) {
record = new ProducerRecord<>(targetTopic, null, timestamp, serializedKey, serializedValue);
} else {
record = new ProducerRecord<>(targetTopic, flinkKafkaPartitioner.partition(value, serializedKey, serializedValue, targetTopic, partitions), timestamp, serializedKey, serializedValue);
}
if (flushOnCheckpoint) {
synchronized (pendingRecordsLock) {
pendingRecords++;
}
}
// 发送消息
producer.send(record, callback);
}
其中FlinkKafkaProducerBase的initializeState方法说明也没做,snapshotState实现也比较简单:
pendingRecords记录了正在发送的记录数,当成功发送一条后会减1
//FlinkKafkaProducerBase
public void snapshotState(FunctionSnapshotContext ctx) throws Exception {
//检查错误
checkErroneous();
if (flushOnCheckpoint) {
flush();
synchronized (pendingRecordsLock) {
if (pendingRecords != 0) {
//throw IllegalStateException
}
//检查错误
checkErroneous();
}
}
}