生成对抗网络学习笔记1----论文Generative Adversarial Nets
转自:http://blog.csdn.net/liuxiao214/article/details/72764099
1、阅读论文:
Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]// International Conference on Neural Information Processing Systems. MIT Press, 2014:2672-2680.
论文地址:GANs
2、翻译论文
摘要
我们提出一个新的框架,通过对抗过程来估计生成网络,这里我们同时训练了两个模型:一个生成模型G,用来捕捉数据分布,一个判别模型D,用来估计来自训练数据而不是模型G中的样本的可能性。关于模型G的训练程序是最大化模型D犯错的可能性。这个框架与极大极小双方博弈相关。在任意函数G和D的距离内,存在一个唯一的解决方法,G恢复训练数据的分布,D在任何地方都等于1/2。在这种情况下,G和D被定义为多层感知器,整个系统可以用反向传播来训练。在整个训练和样本生成阶段,这不需要任何的马尔科夫链或者展开的近似推理网络。通过定性和定量的生成样本的验证,这个实验证明此框架的潜力。
1、介绍
深度学习的愿景是发现丰富的层级模型,这个模型可以表示出在人工智能领域中,例如自然图像、语音声波和自然语言集中的符号,不同种类数据分布的可能性。迄今为止,深度学习上最显著的成功已经涉及到判别模型,通常这种模型将高维的、丰富的感觉输入映射到一个标签类中。这种显著的成功主要是基于后向传播算法和dropout算法,使用有着功能尤为良好的梯度的分段线性单元。深度生成网络则有较少的影响,一是由于许多棘手的逼近概率计算的困难,比如最大似然估计和相关策略,而是由于借助分段线性单元在生成文本上的优势的困难。我们提出了一个新的生成模型评估程序,它可以回避这些困难。
在提到的对抗网络框架中,生成模型与一个对手作竞争:一个判别式模型学习如何判断一个样本是来自模型生成的分布中,还是来自于训练数据的分布中。生成模型可以被看做类似于一个货币伪造者的团队,他们试图制造假币,使用模型时不加检测,而判别模型则类似于试图检测假币的警察。这个游戏中的竞争同时驱使着两个团队提高他们的模型,直到在真实的物品中,伪造品不会被区分出来。
这个框架可以对于很多不同种类的模型产出特定的训练算法和优化算法。在这篇文章中,我们考察这种特殊的案例,生成模型通过一个多层感知器产生带有噪音的样本,而且判别模型也是一个多层感知器。我们将这种特殊的案例适用于对抗模型中。在这种情况下,我们可以使用高度成功的后向传播算法和dropout算法,使用前向传播的生成模型产生的样本,同时训练这两个模型。这不需要任何近似推理和马尔科夫链。
2、相关工作
直到最近,大部分深度生成模型的注意力都放在一个模型如何提供一个概率分布函数的参数说明书上。这个模型接着被最大似然日志训练。在这个模型家族中,或许最成功的就是深度Boltzmann模型。这些模型通常有棘手的似然函数,因此对似然梯度要求大量的近似。这些困难激励了生成机器模型的发展,这些模型不需要明确的表示似然,但是能够从所需的分布中生成样本。生成随机模型就是生成机器的一个例子,他们可以使用明确的后向传播算法,而不是Boltzmann机器要求的许多近似值来训练。这个工作继承了生成机器通过消除在生成随机网络中使用的马尔科夫链的想法。
我们的工作是,在生成过程中,通过使用观察(如下)来后向传播衍生物:
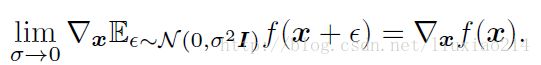
那时我们无意中发现,我们开发的这个工作,Kingma 、 Welling 和Rezende等人已经开发了更为普通的随机后向传播规则,允许通过带有有限方差的高斯分布的后向传播,同样也允许后向传播协方差参数和均值。这些后向传播规则可以允许学习生产者有条件的方差,在这项工作中,我们称之为超参数。Kingma 、 Welling 和Rezende等人使用随机后向传播算法来训练变化的自编码器(VAEs)。像生成对抗网络一样,变化自编码器将可微的生产者网络和第二个神经网络组成一对。与生成对抗网络不同,VAE中的第二层神经网络是一个识别模型,可以进行近似推理。GANs要求可见单元之间要有区别,因此不能模仿离散型数据,而VAEs要求隐藏单元之间要有区别,不能有离散的潜在变量。其他类似VAE的处理方法也存在,但与我们的工作少有联系。
先前的工作也有使用有区别标准的方法来训练生成模型。这些方法使用对于处理深度生成模型很棘手的标准。这些方法对于深度模型来说是难以近似计算的,因为它们包含了使用降低可能性界限的变分近似法而不能求出近似值的可能性的比值。噪音对比估计(NCE)涉及到,通过学习权重训练一个生成模型,这使得这个模型从固定噪音分布中辨别数据很有用。先前已训练的模型作为噪音分布的使用允许提高质量的模型序列的训练。这可以看成是一个非正式的竞争机制,在精神上,与使用在对抗网络游戏中的正式竞争很相似。NCE关键的限制是由噪音分布和模型分布的概率密度比定义的鉴别器,并且因此要求验证和后向传播这两种密度的能力。
一些先前的工作已经使用了两个神经网络竞争的一般概念。最相关的工作是可预测性最小化。在可预测性最小化中,在一个神经网络中的每一个隐藏单元都被训练以不同于第二层网络的输出,这可以预测出给定隐藏单元和其他所有隐藏单元的值。我们这项工作不同于可预测性最小化主要有三个重要方面:1)在这项工作中,网络之间的竞争是唯一的训练标准,并且足够在自己网络上面训练。可预测性最小化仅仅是一个正则化矩阵,激励神经网络的隐藏单元当他们完成一些其他工作时独立地统计;这不是一个主要的训练标准。2)竞争的本质是不同的。在可预测性最小化中,两个网络的输出是被比较的,一个网络试图使得输出相似,另一个试图使得输出不同。输出上的问题只是一个单一的标量。在GANs中,一个网络产生大量、高维度的向量,这些向量被用来输入到另一个网络中,并且试图选择一个其他网络并不知道怎么处理的输入。3)学习过程的说明是不同的。可预测性最小化被描述为一个有着可最小化的客观函数的最优化问题,并且学习最小化这个客观函数的方法。GANs是基于一个极大极小化博弈游戏而不是一个最优化问题,并且有一个价值函数,一个代理试图最大化而另一个代理试图最小化这个函数。这个游戏结束于一个鞍点,对于一个游戏者的策略来说,这是最小的,而对于另一个游戏者的策略来说,这是最大的。
生成对抗网络有时会有一些“对抗例子”的相关概念发生混淆。举例说明,对抗例子是这样的,对于一个分类网络,直接使用基于梯度最优化处理输入,使得发现一些与已经分错类的数据相似的例子。这与现在的这个工作是不同的,因为对抗例子对于训练一个生成模型不是一个机理。相反,对抗例子主要的分析工具是展示一个神经网络在一些有趣方式上的行为,经常高度自信的分类两个图像机试他们之间的不同是人类观察者感觉不到的。这种对抗例子的存在表明了生成对抗网络的训练是无效的,因为他们展示了使得一个现代的识别网络自信的识别一个类别,而不需要效仿任何人类对于那个类别的观察属性,这是可能的。
3、对抗网络
当所有的模型都是多层感知器的时候, 竞争模型框架都是直接应用。为了学习生产者对于数据x的分布![]() ,我们预先定义了一个输入噪音变量
,我们预先定义了一个输入噪音变量![]() ,接着提出一个到数据空间的映射
,接着提出一个到数据空间的映射![]() ,其中G是一个可微函数,参数
,其中G是一个可微函数,参数![]() 代表多层感知器。我们也定义了一个第二层感知器
代表多层感知器。我们也定义了一个第二层感知器![]() ,输出单一的标量。
,输出单一的标量。![]() 表示x来自于数据而不是生成的分布
表示x来自于数据而不是生成的分布![]() 的可能性,我们训练D,以最大化分配给训练例子和来自G的样本的正确标签的可能性。我们同时地也训练G,以最小化
的可能性,我们训练D,以最大化分配给训练例子和来自G的样本的正确标签的可能性。我们同时地也训练G,以最小化![]() 。换句话说,D和G使用价值函数
。换句话说,D和G使用价值函数![]() ,扮演极大极小博弈游戏中的两个游戏者:
,扮演极大极小博弈游戏中的两个游戏者:
![]()
在下一部分,我们提出一个关于竞争网络的理论分析,本质上展示出了,训练标准允许一个去恢复数据生成分布,如G和足够能力提供的、也就是没有参数限制的D。在图一中可以看到关于其少量正式、大多是教育方式的方法解释。在实践中,我们必须使用一个迭代的、用数字表示的方法来实现这个博弈游戏。在训练的内部循环中完成最优化D从计算方面来讲是过于高难度的,在有限的数据集上做这件事会导致过拟合。相反,我们在k步优化D和1步优化G交替进行。只要G改变的最够慢,D的结果就能维持其最近的最优解。这个程序正式出现与算法I中。
在实践中,上面的等式(1)可能不会提供足够的梯度使得G学的很好。在学习的早期,当G比较贫瘠时,D可以高度自信的拒绝样本,因为他们很明显的不同于训练数据。在这种情况下,![]() 饱和。相反,我们训练G最小化
饱和。相反,我们训练G最小化![]() ,而训练D最大化
,而训练D最大化![]() 。这个目标函数导致G和D同一个定点,但是在学习早起提供更强壮的梯度。
。这个目标函数导致G和D同一个定点,但是在学习早起提供更强壮的梯度。
4、理论成果
生产者G暗中定义一个可能性分布![]() ,作为G(z)(
,作为G(z)(![]() )获取的样本可能性。因此,如果给予足够的能力和训练时间,我们使用算法1汇聚关于
)获取的样本可能性。因此,如果给予足够的能力和训练时间,我们使用算法1汇聚关于![]() 的好的估计函数。这一部分的结果是在没有参数设置下完成的,例如,我们表示一个模型,这个模型在概率密度分布函数的空间上,有着学习收敛的无限能力。
的好的估计函数。这一部分的结果是在没有参数设置下完成的,例如,我们表示一个模型,这个模型在概率密度分布函数的空间上,有着学习收敛的无限能力。
我们将会在4.1节中展示,这个极大极小博弈游戏有一个全局最优值![]() 。我们将在4.2节中展示,算法1优化等式(1)来获取想要的结果。
。我们将在4.2节中展示,算法1优化等式(1)来获取想要的结果。

图一:(黑色虚线是真实数据的高斯分布,绿色的线是生成网络学习到的伪造分布,蓝色的线是判别网络判定为真实图片的概率,标x的横线代表服从高斯分布x的采样空间,标z的横线代表服从均匀分布z的采样空间。)
生成对抗模型通过同时更新有识别能力的分布(D,蓝色虚线)来训练,因此它可以区分来自数据生成分布(黑色点线)![]() 的样本和来自生成分布
的样本和来自生成分布![]() (绿色实线)的样本。下面的水平线是哪一个z被抽样的领域是均匀的。上面的水平线是x领域的一部分。向上的箭头表示映射
(绿色实线)的样本。下面的水平线是哪一个z被抽样的领域是均匀的。上面的水平线是x领域的一部分。向上的箭头表示映射![]() 是如何强加到在转换样本上的不均匀分布
是如何强加到在转换样本上的不均匀分布![]() 的。G缩小高密度的区域,并且扩大
的。G缩小高密度的区域,并且扩大![]() 低密度的区域。(a)考虑一个接近于收敛的对抗对:
低密度的区域。(a)考虑一个接近于收敛的对抗对:![]() 相似于
相似于![]() ,并且D部分正确的分类。(b)在算法的内部循环中,D被训练以区分来自数据的样本,聚集于
,并且D部分正确的分类。(b)在算法的内部循环中,D被训练以区分来自数据的样本,聚集于![]()
![]() 。(c)在G更新完后,D的梯度指导
。(c)在G更新完后,D的梯度指导![]() 流向更为分类为数据的方向。(d)在训练的几步之后,如果G和D有足够的能力,他们将会达到一个点,两者都无法提高,因为
流向更为分类为数据的方向。(d)在训练的几步之后,如果G和D有足够的能力,他们将会达到一个点,两者都无法提高,因为![]() 。鉴别者没有能力区分这两个分布,也就是说
。鉴别者没有能力区分这两个分布,也就是说![]() 。
。
算法1:生成对抗模型的minibatch随机梯度下降训练。应用于鉴别者的步数k是一个超参数。我们使用k=1,在我们的实验中至少是最昂贵的花费。
—for 训练的一次迭代 do:
———for k steps do:
——————在噪音咸先验分布为![]() 的m个噪音样本
的m个噪音样本![]() 中采一个minibatch。
中采一个minibatch。
——————从数据产生分布![]() 中的m个例子
中的m个例子![]() 采一个minibatch。
采一个minibatch。
——————通过随机梯度上升,更新判别器: 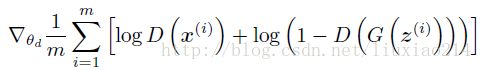
———end for:
———从噪音先验分布为![]() 中的m个噪音样本
中的m个噪音样本![]() 采一个minibatch。
采一个minibatch。
———通过随机梯度下降,更新判别器: 
—end for
—基于梯度的更新可以使用任何标准的基于梯度的学习规则。在我们的实验中我们使用的是动量准则。
4.1全局最优: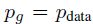
我们首先考虑对于任何给定生产者G的最优鉴别者D。
命题1.对于固定的G,最优鉴别者D是:

证明.对于鉴别者D的训练标准,给定任意生产者G,最大化V(G,D)的量:
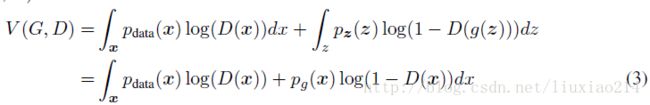
对于任意的![]() ,函数
,函数![]() 在
在![]() 在[0,1]时实现其最大化。鉴别者不需要在
在[0,1]时实现其最大化。鉴别者不需要在![]() 定义。证明结束。
定义。证明结束。
注意,对D的训练目标可以理解成最大化评估条件概率的![]() 对数似然函数,其中Y表明,x来自于
对数似然函数,其中Y表明,x来自于![]() (y=1)还是来自于
(y=1)还是来自于![]() (y=0)。在公式(1)的极大极小博弈游戏中,可以再次阐述为:
(y=0)。在公式(1)的极大极小博弈游戏中,可以再次阐述为:
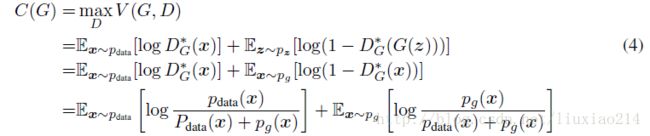
**定理1.**C(G)达到全局最小值,当且仅当![]() 。在这一点时,C(G)实现值为log4。
。在这一点时,C(G)实现值为log4。
证明.对于![]() ,
,![]() (考虑公式(2))。因此,通过检查公式(4),在
(考虑公式(2))。因此,通过检查公式(4),在![]() 时,我们发现,
时,我们发现,![]() ,为了知道当
,为了知道当![]() 时,这个是否是C(G)可能达到的最好的值,观察:
时,这个是否是C(G)可能达到的最好的值,观察:
![]()
并且通过减掉![]() 的表达式,我们得到:
的表达式,我们得到:

其中,KL是相对熵。
这里插播解释一下相对熵。在概率论或信息论中,KL散度(Kullback–Leibler divergence),又称相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。它是非对称的,这意味着D(P||Q) ≠ D(Q||P)。特别的,在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
有人将KL散度称为KL距离,但事实上,KL散度并不满足距离的概念,因为:1)KL散度不是对称的;2)KL散度不满足三角不等式。
我们考虑到在先前的表达中,模型分布和数据生成过程之间的JSD距离:
![]()
**这里插播解释一下JSD距离。**JSD距离是一种基于KL距离(KLdivergence,KLD)的距离度量,它解决了KL距离的不对称性问题,但比KL距离平滑一些,也要小一些。若已知两个概率分布f和g,分布p由它们混合而成,则f和g之间的JSD距离是f到p的KL距离与g到p的KL距离之和。
由于两个分布之间的JSD距离总是非负的,当他们相等的时候是0,我们展示了,C(G)的的全局最小值是![]() ,并且唯一解是
,并且唯一解是![]() ,也就是说,生成模型完美的复制了数据分布。
,也就是说,生成模型完美的复制了数据分布。
4.2算法1的收敛
命题2.如果G和D有足够的能力,在算法1的每一步,对于给定G,并且![]() 是更新的,通过提高标准,鉴别者允许达到其最佳条件,
是更新的,通过提高标准,鉴别者允许达到其最佳条件,
![]()
然后![]() 收敛于
收敛于![]()
证明.考虑在上面的标准中,![]() 作为
作为![]() 的函数已经定下来了。注意,
的函数已经定下来了。注意,![]() 在
在![]() 中是凸的。凸函数的上确界的的次导数包括这个函数的导数,并且在这一点最大值可以取到。换句话说,如果
中是凸的。凸函数的上确界的的次导数包括这个函数的导数,并且在这一点最大值可以取到。换句话说,如果![]()
![]() ,并且
,并且![]() 对于每一个 α,在x上都是凸的,则
对于每一个 α,在x上都是凸的,则![]() 。这就相当于,给定与之相关联的G,计算梯度下降更新
。这就相当于,给定与之相关联的G,计算梯度下降更新![]() 来最优化D。在定理1中已经证明,
来最优化D。在定理1中已经证明,![]() 在
在![]() 中是凸的,并具有全局最优状态,因此,只要有对
中是凸的,并具有全局最优状态,因此,只要有对![]() 足够的小更新,
足够的小更新,![]() 就能收敛到
就能收敛到![]() ,证明结束。
,证明结束。
在实践中,通过函数![]() ,对抗网络代表了
,对抗网络代表了![]() 分布的有限家族,并且我们优化
分布的有限家族,并且我们优化![]() 而不是
而不是![]() 本身,因此证明并不适用。然而,在实际中,多层感知器的的优越性能说明了尽管他们缺乏理论的保证,但他们是合适的模型。
本身,因此证明并不适用。然而,在实际中,多层感知器的的优越性能说明了尽管他们缺乏理论的保证,但他们是合适的模型。

表1:基于对数似然函数评估的帕尔森窗。在MNIST上的报告编号是测试集上的样本的平均对数似然函数,由交叉例子计算的标准平均误差。在TFD上,我们计算折叠数据集的标准误差,通过每一个折叠的验证集来选择不同的σ。在TFD中,在每一个折叠上,σ被交叉验证,并且对数似然函数也被计算。对于MNIST,我们与数据集是实值(而不是二进制)版本的模型相比较。
5、实验
我们在一定范围的数据集内训练对抗网络,包括MNIST,Toronto人脸数据集(TFD)和CIFAR-10。生成器网络使用整流器线性激活函数和sigmoid激活函数的混合,而辨别器网络使用maxout激活函数。Dropout应用于训练辨别器网络中。尽管我们的理论框架允许dropout和生产器中间层的其他噪音的使用,我们使用噪音仅仅是作为生产者网络最底层的输入。
我们通过将高斯帕尔森窗口应用于G产生的样本中,并且在这个分布下报告对数似然函数,来评估![]() 之下的测试数据集的可能性。高斯函数中的σ参数由交叉数据集上的交叉验证获取。这个程序已经由Breuleux等人介绍,并且使用于各种不同的、难以处理似然函数的生成网络。结果如表一中所示,这种评估似然函数的方法方差有点大,并且在高维空间中表现不是特别好,但是据我们所知,这是可用的最好的方法了。可以取样但是不能评估似然的生成网络的提高直接进一步地激励了如果评估这种模型的研究。在图2和图3中,我们展示了在训练之后从生成器获得的样本,尽管我们没有要求这些样本比已有的方法产生的样本要好,但我们相信,这些样本至少与文献中那些比较好的生成模型的样本相比是有可竞争性的,并且强调对抗框架是有潜力的。
之下的测试数据集的可能性。高斯函数中的σ参数由交叉数据集上的交叉验证获取。这个程序已经由Breuleux等人介绍,并且使用于各种不同的、难以处理似然函数的生成网络。结果如表一中所示,这种评估似然函数的方法方差有点大,并且在高维空间中表现不是特别好,但是据我们所知,这是可用的最好的方法了。可以取样但是不能评估似然的生成网络的提高直接进一步地激励了如果评估这种模型的研究。在图2和图3中,我们展示了在训练之后从生成器获得的样本,尽管我们没有要求这些样本比已有的方法产生的样本要好,但我们相信,这些样本至少与文献中那些比较好的生成模型的样本相比是有可竞争性的,并且强调对抗框架是有潜力的。
6、利与弊
这个新的框架有缺点也有优点,涉及到先前的模型框架。缺点主要是没有![]() 的显性表示,并且在训练过程中,D必须是与G同步的(特别的,如果没有更新D,G不应训练过多,为了避免“the Helvetica scenario”情况,G折叠了太多z的值到同一个x的值,以至于模型
的显性表示,并且在训练过程中,D必须是与G同步的(特别的,如果没有更新D,G不应训练过多,为了避免“the Helvetica scenario”情况,G折叠了太多z的值到同一个x的值,以至于模型![]() 没有足够的多样性),尽管Boltzmann机器的负链必须保持学习步数之间的约定。优点就是马尔科夫链不再需要,只是用后向传播来获取梯度,在学习期间不再需要推理,并且更多样性的函数可以成为模型的一部分。表二中总结了生成对抗网络与其他生成模型方法的对比。
没有足够的多样性),尽管Boltzmann机器的负链必须保持学习步数之间的约定。优点就是马尔科夫链不再需要,只是用后向传播来获取梯度,在学习期间不再需要推理,并且更多样性的函数可以成为模型的一部分。表二中总结了生成对抗网络与其他生成模型方法的对比。
上面提到的优点主要是计算方面的,对抗网络不仅从生成器网络中,利用数据例子直接更新,获得了很多统计上的优点,也从辨别器中获得了梯度。这意味着输入的成分不会直接复制到生产器的参数中。对抗网络的另一个优点是,即使是退化分布,他们表现地也非常敏捷,尽管基于马尔科夫链的方法要求,对于链,分布必须是有些模糊的,以至于有能力混合模型。

图2:来自模型的样本验证。最右边一列展示了临近样本最近的训练例子,为了表明模型并没有记住训练集。样本是公平随机的绘制,而不是择优挑选。不想大多数其他深度生成网络,这些图像展示了实际的来自模型分布的样本,而不是隐藏层条件平均给定的样本。此外,这些样本是不相关的,因为抽样过程不依赖于马尔科夫链的混合。a)MNIST b)TFD c)CIFAR-10(全连接模型) d)CIFAR-10(卷积辨别器和非卷积生成器)

图3:在全模型的z空间中,由坐标之间的线性插值获取数字。
7、结论与未来工作
这个框架允许很多直接的扩展:
-
1:一个条件神经网络
 可以通过向G和D同时添加c作为输入获得。
可以通过向G和D同时添加c作为输入获得。 -
2:学习近似推理可以通过给定x,训练一个辅助网络来预测z来实现。
-
3:可以通过训练共享参数的模型族来近似的对所有条件
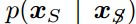 来建模。其实S是x的索引的一个子集。本质上,可以使用对抗网络来实现确定性MP-DBM的随机扩展。
来建模。其实S是x的索引的一个子集。本质上,可以使用对抗网络来实现确定性MP-DBM的随机扩展。 -
4:半监督学习:当只有有限的标签数据可用时,来自鉴别器或者 推理网络的特征可以提高分类器的性能。
-
5:效率改善:通过设计更好地方法来协调G和D,或者决定在训练时对于样本z更好的分布可以显著提高训练性能大大加快训练。
这篇文章表明了对抗模型框架的可行性,表明,这些研究方向是可以证明有用的。

表2:生成模型上的挑战:涉及到模型每个主要操作的深度生成模型不同方法所遇到的困难的总结。