Hierarchical Attention Network for Document Classification--tensorflow实现篇
上周我们介绍了Hierarchical Attention Network for Document Classification这篇论文的模型架构,这周抽空用tensorflow实现了一下,接下来主要从代码的角度介绍如何实现用于文本分类的HAN模型。
数据集
首先介绍一下数据集,这篇论文中使用了几个比较大的数据集,包括IMDB电影评分,yelp餐馆评价等等。选定使用yelp2013之后,一开始找数据集的时候完全处于懵逼状态,所有相关的论文和资料里面出现的数据集下载链接都指向YELP官网,但是官网上怎么都找不到相关数据的下载,然后就各种搜感觉都搜不到==然后就好不容易在github上面找到了,MDZZ,我这都是在写什么,绝对不是在凑字数,单纯的吐槽数据不好找而已。链接如下:
https://github.com/rekiksab/Yelp/tree/master/yelp_challenge/yelp_phoenix_academic_dataset
这里面好像不止一个数据集,还有user,business等其他几个数据集,不过在这里用不到罢了。先来看一下数据集的格式,如下,每一行是一个评论的文本,是json格式保存的,主要有vote, user_id, review_id, stars, data, text, type, business_id几项,针对本任务,只需要使用stars评分和text评论内容即可。这里我选择先将相关的数据保存下来作为数据集。代码如下所示:
{"votes": {"funny": 0, "useful": 5, "cool": 2}, "user_id": "rLtl8ZkDX5vH5nAx9C3q5Q", "review_id": "fWKvX83p0-ka4JS3dc6E5A", "stars": 5, "date": "2011-01-26", "text": "My wife took me here on my birthday for breakfast and it was excellent. The weather was perfect which made sitting outside overlooking their grounds an absolute pleasure. Our waitress was excellent and our food arrived quickly on the semi-busy Saturday morning. It looked like the place fills up pretty quickly so the earlier you get here the better.\n\nDo yourself a favor and get their Bloody Mary. It was phenomenal and simply the best I've ever had. I'm pretty sure they only use ingredients from their garden and blend them fresh when you order it. It was amazing.\n\nWhile EVERYTHING on the menu looks excellent, I had the white truffle scrambled eggs vegetable skillet and it was tasty and delicious. It came with 2 pieces of their griddled bread with was amazing and it absolutely made the meal complete. It was the best \"toast\" I've ever had.\n\nAnyway, I can't wait to go back!", "type": "review", "business_id": "9yKzy9PApeiPPOUJEtnvkg"}数据集的预处理操作,这里我做了一定的简化,将每条评论数据都转化为30*30的矩阵,其实可以不用这么规划,只需要将大于30的截断即可,小鱼30的不需要补全操作,只是后续需要给每个batch选定最大长度,然后获取每个样本大小,这部分我还没有太搞清楚,等之后有时间再看一看,把这个功能加上就行了。先这样凑合用==
#coding=utf-8
import json
import pickle
import nltk
from nltk.tokenize import WordPunctTokenizer
from collections import defaultdict
#使用nltk分词分句器
sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
word_tokenizer = WordPunctTokenizer()
#记录每个单词及其出现的频率
word_freq = defaultdict(int)
# 读取数据集,并进行分词,统计每个单词出现次数,保存在word freq中
with open('yelp_academic_dataset_review.json', 'rb') as f:
for line in f:
review = json.loads(line)
words = word_tokenizer.tokenize(review['text'])
for word in words:
word_freq[word] += 1
print "load finished"
# 将词频表保存下来
with open('word_freq.pickle', 'wb') as g:
pickle.dump(word_freq, g)
print len(word_freq)#159654
print "word_freq save finished"
num_classes = 5
# 将词频排序,并去掉出现次数最小的3个
sort_words = list(sorted(word_freq.items(), key=lambda x:-x[1]))
print sort_words[:10], sort_words[-10:]
#构建vocablary,并将出现次数小于5的单词全部去除,视为UNKNOW
vocab = {}
i = 1
vocab['UNKNOW_TOKEN'] = 0
for word, freq in word_freq.items():
if freq > 5:
vocab[word] = i
i += 1
print i
UNKNOWN = 0
data_x = []
data_y = []
max_sent_in_doc = 30
max_word_in_sent = 30
#将所有的评论文件都转化为30*30的索引矩阵,也就是每篇都有30个句子,每个句子有30个单词
# 不够的补零,多余的删除,并保存到最终的数据集文件之中
with open('yelp_academic_dataset_review.json', 'rb') as f:
for line in f:
doc = []
review = json.loads(line)
sents = sent_tokenizer.tokenize(review['text'])
for i, sent in enumerate(sents):
if i < max_sent_in_doc:
word_to_index = []
for j, word in enumerate(word_tokenizer.tokenize(sent)):
if j < max_word_in_sent:
word_to_index.append(vocab.get(word, UNKNOWN))
doc.append(word_to_index)
label = int(review['stars'])
labels = [0] * num_classes
labels[label-1] = 1
data_y.append(labels)
data_x.append(doc)
pickle.dump((data_x, data_y), open('yelp_data', 'wb'))
print len(data_x) #229907
# length = len(data_x)
# train_x, dev_x = data_x[:int(length*0.9)], data_x[int(length*0.9)+1 :]
# train_y, dev_y = data_y[:int(length*0.9)], data_y[int(length*0.9)+1 :]在将数据预处理之后,我们就得到了一共229907篇文档,每篇都是30*30 的单词索引矩阵,这样在后续进行读取的时候直接根据嵌入矩阵E就可以将单词转化为词向量了。也就省去了很多麻烦。这样,我们还需要一个数据的读取的函数,将保存好的数据载入内存,其实很简单,就是一个pickle读取函数而已,然后将数据集按照9:1的比例分成训练集和测试集。其实这里我觉得9:1会使验证集样本过多(20000个),但是论文中就是这么操作的==暂且不管这个小细节,就按论文里面的设置做吧。代码如下所示:
def read_dataset():
with open('yelp_data', 'rb') as f:
data_x, data_y = pickle.load(f)
length = len(data_x)
train_x, dev_x = data_x[:int(length*0.9)], data_x[int(length*0.9)+1 :]
train_y, dev_y = data_y[:int(length*0.9)], data_y[int(length*0.9)+1 :]
return train_x, train_y, dev_x, dev_y有了这个函数,我们就可以在训练时一键读入数据集了。接下来我们看一下模型架构的实现部分。
模型实现
按照上篇博客中关于模型架构的介绍,结合下面两张图进行理解,我们应该很容易的得出模型的框架主要分为句子层面,文档层面两部分,然后每个内部有包含encoder和attention两部分。
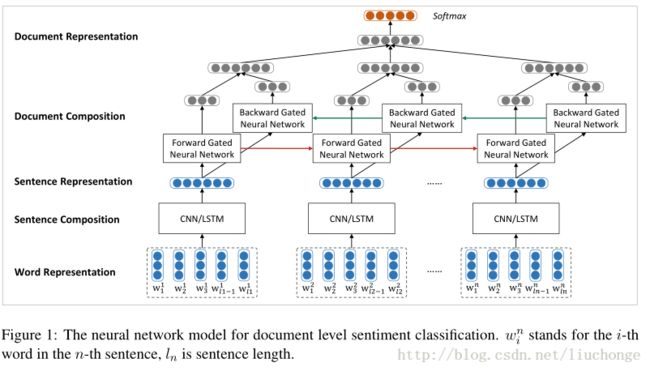
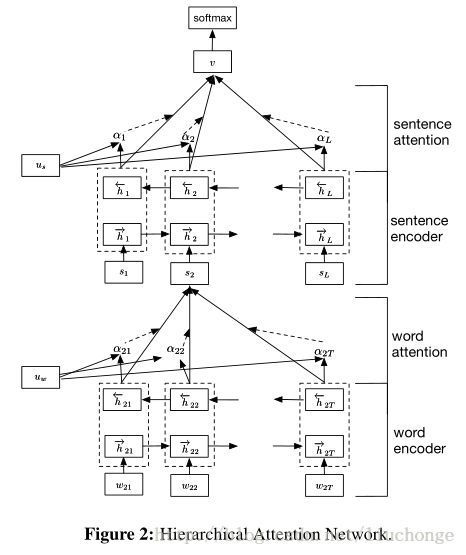
代码部分如下所示,主要是用tf.nn.bidirectional_dynamic_rnn()函数实现双向GRU的构造,然后Attention层就是一个MLP+softmax机制,yehe你容易理解。
#coding=utf8
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.contrib import layers
def length(sequences):
#返回一个序列中每个元素的长度
used = tf.sign(tf.reduce_max(tf.abs(sequences), reduction_indices=2))
seq_len = tf.reduce_sum(used, reduction_indices=1)
return tf.cast(seq_len, tf.int32)
class HAN():
def __init__(self, vocab_size, num_classes, embedding_size=200, hidden_size=50):
self.vocab_size = vocab_size
self.num_classes = num_classes
self.embedding_size = embedding_size
self.hidden_size = hidden_size
with tf.name_scope('placeholder'):
self.max_sentence_num = tf.placeholder(tf.int32, name='max_sentence_num')
self.max_sentence_length = tf.placeholder(tf.int32, name='max_sentence_length')
self.batch_size = tf.placeholder(tf.int32, name='batch_size')
#x的shape为[batch_size, 句子数, 句子长度(单词个数)],但是每个样本的数据都不一样,,所以这里指定为空
#y的shape为[batch_size, num_classes]
self.input_x = tf.placeholder(tf.int32, [None, None, None], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name='input_y')
#构建模型
word_embedded = self.word2vec()
sent_vec = self.sent2vec(word_embedded)
doc_vec = self.doc2vec(sent_vec)
out = self.classifer(doc_vec)
self.out = out
def word2vec(self):
#嵌入层
with tf.name_scope("embedding"):
embedding_mat = tf.Variable(tf.truncated_normal((self.vocab_size, self.embedding_size)))
#shape为[batch_size, sent_in_doc, word_in_sent, embedding_size]
word_embedded = tf.nn.embedding_lookup(embedding_mat, self.input_x)
return word_embedded
def sent2vec(self, word_embedded):
with tf.name_scope("sent2vec"):
#GRU的输入tensor是[batch_size, max_time, ...].在构造句子向量时max_time应该是每个句子的长度,所以这里将
#batch_size * sent_in_doc当做是batch_size.这样一来,每个GRU的cell处理的都是一个单词的词向量
#并最终将一句话中的所有单词的词向量融合(Attention)在一起形成句子向量
#shape为[batch_size*sent_in_doc, word_in_sent, embedding_size]
word_embedded = tf.reshape(word_embedded, [-1, self.max_sentence_length, self.embedding_size])
#shape为[batch_size*sent_in_doce, word_in_sent, hidden_size*2]
word_encoded = self.BidirectionalGRUEncoder(word_embedded, name='word_encoder')
#shape为[batch_size*sent_in_doc, hidden_size*2]
sent_vec = self.AttentionLayer(word_encoded, name='word_attention')
return sent_vec
def doc2vec(self, sent_vec):
#原理与sent2vec一样,根据文档中所有句子的向量构成一个文档向量
with tf.name_scope("doc2vec"):
sent_vec = tf.reshape(sent_vec, [-1, self.max_sentence_num, self.hidden_size*2])
#shape为[batch_size, sent_in_doc, hidden_size*2]
doc_encoded = self.BidirectionalGRUEncoder(sent_vec, name='sent_encoder')
#shape为[batch_szie, hidden_szie*2]
doc_vec = self.AttentionLayer(doc_encoded, name='sent_attention')
return doc_vec
def classifer(self, doc_vec):
#最终的输出层,是一个全连接层
with tf.name_scope('doc_classification'):
out = layers.fully_connected(inputs=doc_vec, num_outputs=self.num_classes, activation_fn=None)
return out
def BidirectionalGRUEncoder(self, inputs, name):
#双向GRU的编码层,将一句话中的所有单词或者一个文档中的所有句子向量进行编码得到一个 2×hidden_size的输出向量,然后在经过Attention层,将所有的单词或句子的输出向量加权得到一个最终的句子/文档向量。
#输入inputs的shape是[batch_size, max_time, voc_size]
with tf.variable_scope(name):
GRU_cell_fw = rnn.GRUCell(self.hidden_size)
GRU_cell_bw = rnn.GRUCell(self.hidden_size)
#fw_outputs和bw_outputs的size都是[batch_size, max_time, hidden_size]
((fw_outputs, bw_outputs), (_, _)) = tf.nn.bidirectional_dynamic_rnn(cell_fw=GRU_cell_fw,
cell_bw=GRU_cell_bw,
inputs=inputs,
sequence_length=length(inputs),
dtype=tf.float32)
#outputs的size是[batch_size, max_time, hidden_size*2]
outputs = tf.concat((fw_outputs, bw_outputs), 2)
return outputs
def AttentionLayer(self, inputs, name):
#inputs是GRU的输出,size是[batch_size, max_time, encoder_size(hidden_size * 2)]
with tf.variable_scope(name):
# u_context是上下文的重要性向量,用于区分不同单词/句子对于句子/文档的重要程度,
# 因为使用双向GRU,所以其长度为2×hidden_szie
u_context = tf.Variable(tf.truncated_normal([self.hidden_size * 2]), name='u_context')
#使用一个全连接层编码GRU的输出的到期隐层表示,输出u的size是[batch_size, max_time, hidden_size * 2]
h = layers.fully_connected(inputs, self.hidden_size * 2, activation_fn=tf.nn.tanh)
#shape为[batch_size, max_time, 1]
alpha = tf.nn.softmax(tf.reduce_sum(tf.multiply(h, u_context), axis=2, keep_dims=True), dim=1)
#reduce_sum之前shape为[batch_szie, max_time, hidden_szie*2],之后shape为[batch_size, hidden_size*2]
atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1)
return atten_output以上就是主要的模型架构部分,其实思路也是很简单的,主要目的是熟悉一下其中一些操作的使用方法。接下来就是模型的训练部分了。
模型训练
其实这部分里的数据读入部分我一开始打算使用上次博客中提到的TFRecords来做,但是实际用的时候发现貌似还有点不熟悉,尝试了好几次都有点小错误,虽然之前已经把别人的代码都看明白了,但是真正到自己写的时候还是存在一定的难度,还要抽空在学习学习==所以在最后还是回到了以前的老方法,分批次读入,恩,最起码简单易懂23333.。。。
由于这部分大都是重复性的代码,所以不再进行详细赘述,不懂的可以去看看我前面几篇博客里面关于模型训练部分代码的介绍。
这里重点说一下,关于梯度训练部分的梯度截断,由于RNN模型在训练过程中往往会出现梯度爆炸和梯度弥散等现象,所以在训练RNN模型时,往往会使用梯度截断的技术来防止梯度过大而引起无法正确求到的现象。然后就基本上都是使用的dennizy大神的CNN代码中的程序了。
#coding=utf-8
import tensorflow as tf
import model
import time
import os
from load_data import read_dataset, batch_iter
# Data loading params
tf.flags.DEFINE_string("data_dir", "data/data.dat", "data directory")
tf.flags.DEFINE_integer("vocab_size", 46960, "vocabulary size")
tf.flags.DEFINE_integer("num_classes", 5, "number of classes")
tf.flags.DEFINE_integer("embedding_size", 200, "Dimensionality of character embedding (default: 200)")
tf.flags.DEFINE_integer("hidden_size", 50, "Dimensionality of GRU hidden layer (default: 50)")
tf.flags.DEFINE_integer("batch_size", 32, "Batch Size (default: 64)")
tf.flags.DEFINE_integer("num_epochs", 10, "Number of training epochs (default: 50)")
tf.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)")
tf.flags.DEFINE_integer("num_checkpoints", 5, "Number of checkpoints to store (default: 5)")
tf.flags.DEFINE_integer("evaluate_every", 100, "evaluate every this many batches")
tf.flags.DEFINE_float("learning_rate", 0.01, "learning rate")
tf.flags.DEFINE_float("grad_clip", 5, "grad clip to prevent gradient explode")
FLAGS = tf.flags.FLAGS
train_x, train_y, dev_x, dev_y = read_dataset()
print "data load finished"
with tf.Session() as sess:
han = model.HAN(vocab_size=FLAGS.vocab_size,
num_classes=FLAGS.num_classes,
embedding_size=FLAGS.embedding_size,
hidden_size=FLAGS.hidden_size)
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=han.input_y,
logits=han.out,
name='loss'))
with tf.name_scope('accuracy'):
predict = tf.argmax(han.out, axis=1, name='predict')
label = tf.argmax(han.input_y, axis=1, name='label')
acc = tf.reduce_mean(tf.cast(tf.equal(predict, label), tf.float32))
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
global_step = tf.Variable(0, trainable=False)
optimizer = tf.train.AdamOptimizer(FLAGS.learning_rate)
# RNN中常用的梯度截断,防止出现梯度过大难以求导的现象
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, tvars), FLAGS.grad_clip)
grads_and_vars = tuple(zip(grads, tvars))
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
grad_summaries.append(grad_hist_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
loss_summary = tf.summary.scalar('loss', loss)
acc_summary = tf.summary.scalar('accuracy', acc)
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph)
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
feed_dict = {
han.input_x: x_batch,
han.input_y: y_batch,
han.max_sentence_num: 30,
han.max_sentence_length: 30,
han.batch_size: 64
}
_, step, summaries, cost, accuracy = sess.run([train_op, global_step, train_summary_op, loss, acc], feed_dict)
time_str = str(int(time.time()))
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, cost, accuracy))
train_summary_writer.add_summary(summaries, step)
return step
def dev_step(x_batch, y_batch, writer=None):
feed_dict = {
han.input_x: x_batch,
han.input_y: y_batch,
han.max_sentence_num: 30,
han.max_sentence_length: 30,
han.batch_size: 64
}
step, summaries, cost, accuracy = sess.run([global_step, dev_summary_op, loss, acc], feed_dict)
time_str = str(int(time.time()))
print("++++++++++++++++++dev++++++++++++++{}: step {}, loss {:g}, acc {:g}".format(time_str, step, cost, accuracy))
if writer:
writer.add_summary(summaries, step)
for epoch in range(FLAGS.num_epochs):
print('current epoch %s' % (epoch + 1))
for i in range(0, 200000, FLAGS.batch_size):
x = train_x[i:i + FLAGS.batch_size]
y = train_y[i:i + FLAGS.batch_size]
step = train_step(x, y)
if step % FLAGS.evaluate_every == 0:
dev_step(dev_x, dev_y, dev_summary_writer)
当模型训练好之后,我们就可以去tensorboard上面查看训练结果如何了。
训练结果
训练起来不算慢,但是也称不上快,在实验室服务器上做测试,64G内存,基本上2秒可以跑3个batch。然后我昨天晚上跑了之后就回宿舍了,回来之后发现忘了把dev的数据写到summary里面,而且现在每个epoch里面没加shuffle,也没跑很久,更没有调参,所以结果凑合能看出一种趋势,等过几天有时间在跑跑该该参数之类的看能不能有所提升,就简单上几个截图吧。
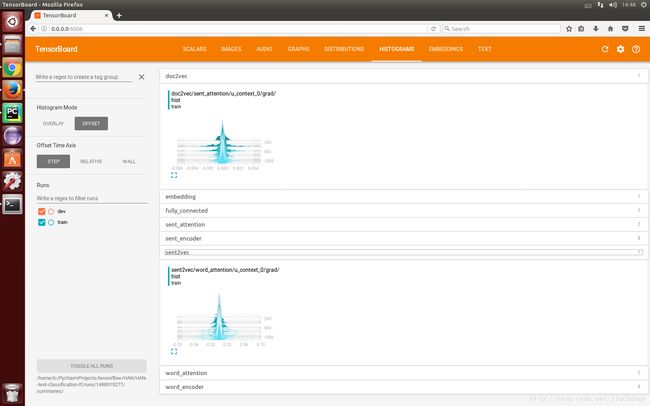
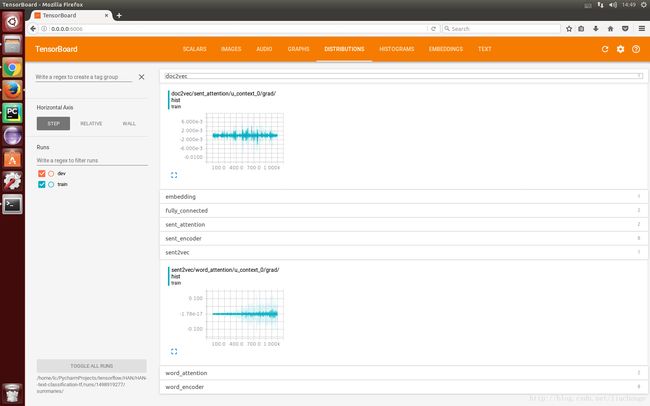
最后的最后再贴上几个链接,都是在学习和仿真这安论文的时候看到的一些感觉不错的博客之类的:
1,richliao,他关于这篇文章写了三篇博客,分别从CNN/RNN/HAN逐层递进进行介绍,写得很不错,可以加深理解。不过是使用keras实现的,博客和代码链接如下:
https://richliao.github.io/
https://github.com/richliao/textClassifier
2,yelp数据集下载链接:
https://github.com/rekiksab/Yelp/tree/master/yelp_challenge/yelp_phoenix_academic_dataset
3,EdGENetworks,这是一个使用pytorch实现的链接,其实代码我没怎么看,但是发现背后有一个屌屌的公司explosion.ai,博客里面还是写了很干货的,要好好学习下。
https://github.com/EdGENetworks/attention-networks-for-classification
https://explosion.ai/blog/deep-learning-formula-nlp
4,ematvey,这个博主使用tensorflow实现了一个版本,我也参考了他数据处理部分的代码,但是感觉程序有点不太容易读,给出链接,仁者见仁。
https://github.com/ematvey/deep-text-classifier