JitterBuffer对POS机的影响
和同事一起处理现网POS机问题,最后发现JitterBuffer的设置对POS机业务的影响非常大,通过一段时间反复理解broadcom《AJC_Config.pdf》文档及上网查阅相关资料,把一些理解总结一下。
POS机问题分析:
POS机对信号的质量要求非常高,在从PSTN网络切换到分组交换网时,会因为分组交换网的多种弊端(延时、抖动、丢包),导致POS机
业务受到严重影响。其中延时、抖动可以通过设置 JitterBuffer进行解决。丢包分为两个方面,一种是网络环境问题导致数据包没有到达终
点(这种情况出现概率比较低)。一种是网络环境问题导致数据包经过很长一段时间才到达终点,经由DSP的JitterBuffer算法将该数据包
丢弃处理(通常丢包是因为这个原因引起),这个也可以通过设置JitterBuffer进行解决。
目前我们虽然有JitterBuffer功能,但由于代码对JitterBuffer使用不合理,导致JitterBuffer功能没有启到实际效果。
BCM JitterBuffer参数说明:
个人理解有限,有不正确的地方麻烦指证一下。
目前BCM驱动对JitterBuffer功能提供了五个设置参数(fixed、voiceMin、voiceMax、voiceTarget、dataTarget),其中前四个用于
语音模式,最后一个用于数据模式。
五个值大体意思为:
Fixed:设置语音模式下JitterBuffer功能是静态模式还是动态模式,如果用于POS机环境,该值一定要设置为静态模式,因为POS机可能
在语音模式下就有信号处理。如果是普通通话环境,一般设置为动态模式比较合理,DSP会根据实时网络抖动自动调整Activate Target阀值,
以保证在语音质量和通话延时之间找到一个合理的平衡点。
voiceMin:仅在语音模式为动态时生效,在本地时钟与远端时钟有差异时才需要调整该值,通常该值设置为0(即认为本地时钟与远端时间几
乎没有明显差异)。注意:这个值很多人都会误以为是动态调整的最小下限阀值,千万不要这样理解,待下面进行举例说明来加深理解该参数
值的作用。
voiceMax:仅在语音模式为动态时生效,该值比较好理解,就是JitterBuffer的最大上限,超过该上限则产生缓冲区上溢,DSP会丢弃多余
的数据。该值如果设置为0则表示使用DSP默认的最大值。该值主要用于在网络上产生异常大的延时,或者设备自身网络相关模块出现异常,
导致JitterBuffer缓冲区在指定时间点,被填充大量数据包,进行一个界限防范。
voiceTarget:该值在语音模式为动态或静态时有不同的作用。
在语音模式为静态时,voiceMin和voiceMax将不启作用,该值用于标识JitterBuffer缓冲区最大上限。
当接收的数据包数量超过上限时,则删除多余数据。
当到达DSP采样周期,但缓冲区没有数据可处理时,DSP自动发送静音数据给用户侧。
当到达DSP采样周期,缓冲区有数据时,则从缓冲区取出一个数据包给DSP处理。
在语音模式为动态时,因为初期还没有数据包处理,所以DSP的Activate Target取该值为初始值,后期DSP会根据实时网络抖动自动调整
Activate Target阀值,但Activate Target阀值自动调整范围为voiceTarget到voiceMax,注意这里是不是voiceTarget有点像缓冲区
最小下限的意思,可以这样理解。Activate Target最关键的作用是在DSP到达采样周期后,会根据当前缓冲区中的数据是否大于或等于
Activate Target值,而决定DSP如何处理,如果当前缓冲区中的数据还没有到达Activate Target阀值,则DSP自动发送静音数据给用
户侧或重发上一语音数据,如果当前缓冲区中的数据到达了Activate Target阀值,则DSP从缓冲区中取出一个数据进行处理。Bcm建议
初始target设置为0,好处是不需要我们分析网络实际抖动值来设置target,DSP可以根据当前网络抖动情况快速调整Target,但target
设置为0的坏处是很容易产生缓冲区下溢,就会造成数据包被丢弃;但target设置为非0的值虽然上面问题不会产生,但因为设置target
的值,将会造成在网络没有抖动的情况下,额外增加了点对点的媒体延时,即如果target设置为10,此时网络上没有抖动,但语音点对点
通话一定会有额外的10ms延时存在。
dataTaget:仅用于数据模式,即DSP切换到数据模式时,该值将启作用,注意数据模式没有动态模式,只有静态模式,机制和语音静态模式
相同,这里就不详细说明。
图例说明:
通过自己的理解,对《AJC_Config.pdf》文档图例进行说明,加深大家对这几个参数值的理解。
(下面图例都是基于5ms的编码速率进行说明)
1、语音动态模式,初始target设置为0,缓冲区下溢,造成晚来的媒体包被丢弃。

这里大家要理解缓冲区下溢的概念,缓冲区下溢是指要要取缓冲区数据,但缓冲区是空的,此时就说缓冲区出现下溢。
这里DSP每5ms进行一样网络包采样,但在第10ms时才收到第1、第2个包,第1个包的时间戳与实际到达时间相差
10ms,第2个包的时间戳与实际到达时间相差5ms,这两个包的差值都超过了当前Activate Target初始值0,所以
DSP将这两个包做丢弃处理。如果此时设置target为30,则晚来的包实际时间与理论时间差值不会超过Activate Target
初始值30,此时就不会被丢弃。
文档里不是提到Activate Target不是会自动增长吗?我的理解,因为初始通话,在没有数据包到达时,此时DSP
没办法算出网络抖动,因为网络抖动需要将两次包到达的实际时间与理论时间差值进行比较,所以此时DSP没办法
动态调整Activate Target。
2、语音动态模式,Activate Target自动调整。

在第0ms时,DSP收到了一个数据包,因为当前Activate Target为0,则将该包从缓冲区移到DSP处理队列进行处理。
在第5ms时,缓冲区产生下溢,重发第1个包到用户侧,同时根据之前的网络包到达时间,知道此时网络出现抖动,
DSP快速调整Activate Target值为20到30ms左右,与提高语音质量,之后如果网络没有抖动,则会慢慢地降低
Activate Target值,直到回退到target设置的值。
3、语音动态模式,初始target设置为20ms。
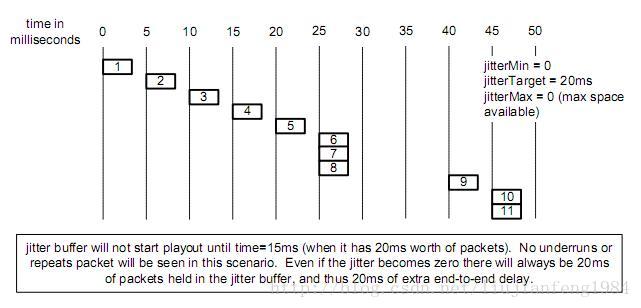
当前Activate Target初始值为20ms,则在缓冲区没有收集到20ms数据包之前,始终不将缓冲区数据移到DSP处理队列
进行处理,直接到15ms时,DSP进行网络采样,才把第1个包移到DSP处理队列去处理。这里第30、35ms都不会出现缓
冲区下溢,因为这期间缓冲区中一直有数据包存在。但这里有一点不足的就是,如果网络中没有抖动,则在两端会有额面
的20ms延时产生。
4、语音动态模式,初始target设置为20ms。
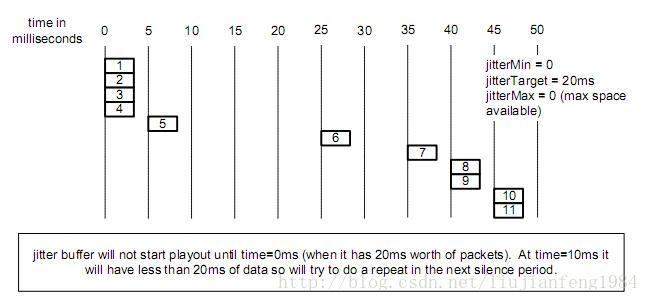
在第0ms时,缓冲区已经存储了20ms的数据,达到了Activate Target值的界线,此时在DSP采样处理时,会把第1个包
移到DSP处理队列,当在第5ms时,又来了一个数据包,此时又满足Activate Target值的界线,在DSP采样处理时,会
把第2个包移到DSP处理队列,当在第10ms时,缓冲区只有15ms的数据,没有到达Activate Target值的界线,此时DSP
采样处理时,将没有数据可供处理,则给用户侧发送静音包。
5、语音动态模式,设置了jitterMin,用于解决时钟抖动。

首先大家要清楚这里提到的时钟抖动概念,这里是说本端设备与网络侧远端设备的时钟差异,造成两端的时间有时候接近,有时候则不同。
例如,对端的时间是每分钟是60秒,但本端时间每分钟只相当于对端的59秒,这样本端每分钟就会比对端快1秒。
此时,缓冲区的数据会因为时钟抖动被本端快速处理完,导致产生缓冲区下溢。
我给大家用图例详细说一下这个问题原因,如下图,假如包速率为5ms,第1个包到达缓冲区,经过15ms后,第1个包需要交给DSP去处
理,此时第1个包在缓冲区停留的时间即为15ms,因为本端与远端时钟基乎相同,所以缓冲区始终维持4个包,并且每个包在进到缓冲区,
到离开缓冲区的时间都是15ms。

但当本端与远端产生时钟抖动时,本端侧的时钟比远端时钟快,将导致远端发包跟不上本端处理包,缓冲区队列包数量逐渐减少,最后引起
缓冲区下溢,这里注意3号包,从到达缓冲区到离开缓冲区只有10ms的时间了,正常都是平均15ms,这里jitterMin的作用,就是限制一
个包从到达缓冲区到离开缓冲的时间不能低于jitterMin值,如果低于jitterMin值,则DSP延缓该包在缓冲区停留时间,并向用户侧发
送一个静音包。
