python3爬虫(3)下载流媒体m3u8
现在很多视频网站采用流媒体技术进行播放音视频,一种常见的方案是m3u8文件+ts文件,虽然you-get库可以下载大部分主流视频网站里面的视频,那也只是主流的,并不是全部的,也不知道他是什么原理,流媒体下载要自己掌握里面的技术和原理才比较好,比如这个csdn学院里面的视频他就下载不了,虎牙直播直播的视频数据也下载不了。
基础知识
m3u8文件:
其实就是一个ts文件列表,一个简单m3u8文件示例:
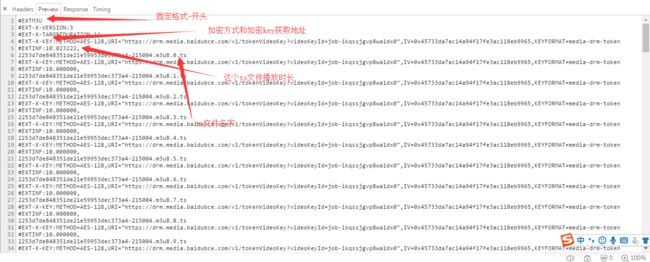
ts文件
ts是日本高清摄像机拍摄下进行的封装格式,全称为MPEG2-TS。ts即"Transport Stream"的缩写。MPEG2-TS格式的特点就是要求从视频流的任一片段开始都是可以独立解码的。
直白点来讲就是视频文件,如果没有经过加密是可以通过播放器直接播放的。
实战演练
csdn学院里面随便找了一个免费观看视频,视频链接:https://edu.csdn.net/course/play/10085/215004
打开浏览器,输入上面网址,F12打开抓包工具,地址栏回车打开该网址,经过一个短暂广告视频(随机广告)进入目的视频,暂停视频,停止抓包。点击xhr按钮,看看那里面有什么
(为什么点这个?答:all是指所有链接请求,有些链接是ajax动态加载的,开发者工具会放进xhr栏里,直接过来看看是因为音视频动态加载概率比较大,先在这里看,没有什收获再去all里面看)
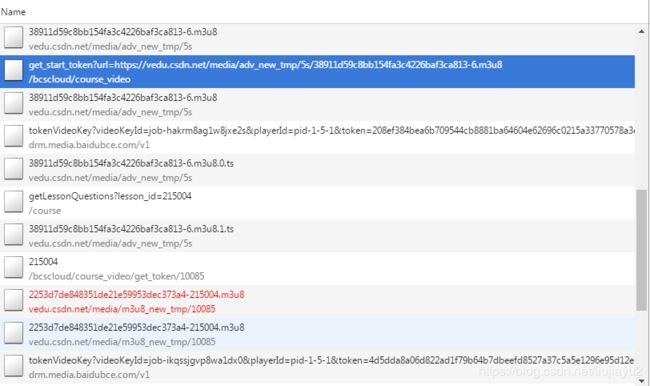
大致看下,有两个m3u8的地址请求,有若干个ts文件请求和一些其他请求
m3u8:
https://vedu.csdn.net/media/adv_new_tmp/5s/38911d59c8bb154fa3c4226baf3ca813-6.m3u8
https://vedu.csdn.net/media/m3u8_new_tmp/10085/2253d7de848351de21e59953dec373a4-215004.m3u8
ts:
https://vedu.csdn.net/media/adv_new_tmp/5s/38911d59c8bb154fa3c4226baf3ca813-6.m3u8.0.ts
https://vedu.csdn.net/media/m3u8_new_tmp/10085/2253d7de848351de21e59953dec373a4-215004.m3u8.0.ts
https://vedu.csdn.net/media/m3u8_new_tmp/10085/2253d7de848351de21e59953dec373a4-215004.m3u8.1.ts
https://vedu.csdn.net/media/m3u8_new_tmp/10085/2253d7de848351de21e59953dec373a4-215004.m3u8.2.ts
https://vedu.csdn.net/media/m3u8_new_tmp/10085/2253d7de848351de21e59953dec373a4-215004.m3u8.3.ts
大概猜测一下,一个m3u8请求代表一个视频,第一个是广告视频,第二个是正式视频,广告视频较短一个ts文件即可,正式文件较长,需要多个ts文件。经过查看m3u8请求返回信息,确定上面猜想。
用下面代码可以直接把所有ts文件下载下来。
import os
import requests
"""
下载M3U8文件里的所有片段
"""
def download(url):
download_path = os.getcwd() + "\download"
if not os.path.exists(download_path):
os.mkdir(download_path)
all_content = requests.get(url).text # 获取M3U8的文件内容
file_line = all_content.split("\n") # 读取文件里的每一行
# 通过判断文件头来确定是否是M3U8文件
if file_line[0] != "#EXTM3U":
raise BaseException(u"非M3U8的链接")
else:
unknow = True # 用来判断是否找到了下载的地址
for index, line in enumerate(file_line):
if "EXTINF" in line:
unknow = False
# 拼出ts片段的URL
pd_url = url.rsplit("/", 1)[0] + "/" + file_line[index + 1]
res = requests.get(pd_url)
c_fule_name = str(file_line[index + 1])
with open(download_path + "\\" + c_fule_name, 'ab') as f:
f.write(res.content)
f.flush()
if unknow:
raise BaseException("未找到对应的下载链接")
else:
print("下载完成")
if __name__ == '__main__':
download("https://vedu.csdn.net/media/m3u8_new_tmp/10085/2253d7de848351de21e59953dec373a4-215004.m3u8")
但是发现这些文件都不能正常播放,(用的VLC),猜测应该是加密了,期初猜测可能Js进行了简单的疑惑加密,播放的时候在进行简单解密。后来仔细看下m3u8文件,上面有注明加密方式和加密key地址:https://drm.media.baidubce.com/v1/tokenVideoKey?videoKeyId=job-ikqssjgvp8wa1dx0
把这个地址直接输入浏览器,看看有什么返回,返回了一个json: {"code":"BAD_REQUEST","message":"lack of token in query string"}意思是缺少token信息,我们再回头看看xhr请求,看下人家是怎么获取的这个key,找了一下,找到了,

请求:
https://drm.media.baidubce.com/v1/tokenVideoKey?videoKeyId=job-ikqssjgvp8wa1dx0&playerId=pid-1-5-1&token=4a61413a3c0718a4d7bb2c955061d862ae1bf6e6850151cecb12160a8dbc210f_7e1ad0afea1946f3ad16c83471dc0256_1546938572
我们直接把这个地址放进浏览器地址栏试一下,也返回了这个json ,这个json里面的encryptedVideoKey
就是我们想要的解密key,看下这个请求,别我们从m3u8里面获取到的多两个参数,一个pid,一个token,pid试了好几次都是这个值,可以当做定值看待,token从字面理解应该是浏览器和服务器回话的标识,也就是服务器给客户端返回的。找下请求,找到了两个如下:
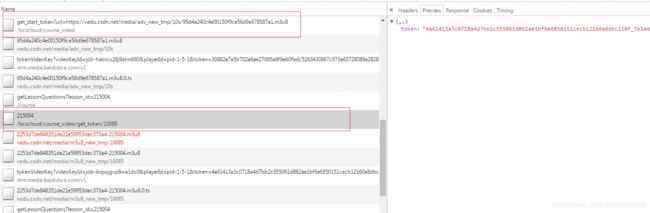
可以看到,看一个视频就会生成一次token,并且经过测试token和视频之间有绑定关系,这个视频的token不能拿到另一个视频的key
https://edu.csdn.net/bcscloud/course_video/get_start_token?url=https://vedu.csdn.net/media/adv_new_tmp/10s/95d4a240c4e00150f9ce56d9e678587a1.m3u8 (广告视频)
https://edu.csdn.net/bcscloud/course_video/get_token/10085/215004 (正式视频)
这样我们整理一下思路:

代码如下:
# -*- coding:utf-8 -*-
import os
import sys
import requests
import datetime
from Cryptodome.Cipher import AES
from Cryptodome import Random
import json
from binascii import b2a_hex, a2b_hex
#这个地址需要手工抓包获得
m3u8_url = 'https://vedu.csdn.net/media/m3u8_new_tmp/10085/2253d7de848351de21e59953dec373a4-215004.m3u8'
#每个视频播放前都会有个广告,这个也要手工抓取,获取token必须用广告地址
guanggao_url = 'https://vedu.csdn.net/media/adv_new_tmp/5s/38911d59c8bb154fa3c4226baf3ca813-6.m3u8'
def get_pid():
return 'pid-1-5-1'
def get_token():
# 这个是获取广告的token
# token_url = 'https://edu.csdn.net/bcscloud/course_video/get_start_token?url='+guanggao_url
# return json.loads(requests.get(token_url).text).get('token')
#后边的/10085/215004是在网页地址栏里,没办法,手工获取吧
token_url = 'https://edu.csdn.net/bcscloud/course_video/get_token/10085/215004'
return json.loads(requests.get(token_url).text).get('token')
def get_key(key_url):
key_url_all = key_url+'&playerId='+get_pid()+'&token='+get_token()
return json.loads(requests.get(key_url_all).text).get('encryptedVideoKey')
def download(url):
download_path = os.getcwd() + "\download"
if not os.path.exists(download_path):
os.mkdir(download_path)
# 新建日期文件夹
download_path = os.path.join(download_path, datetime.datetime.now().strftime('%Y%m%d_%H%M%S'))
download_path_encode = download_path + '_encode'
download_path_decode = download_path + '_decode'
os.mkdir(download_path_encode)
os.mkdir(download_path_decode)
all_content = requests.get(url).text # 获取第一层M3U8文件内容
if "#EXTM3U" not in all_content:
raise BaseException("非M3U8的链接")
if "EXT-X-STREAM-INF" in all_content: # 第一层
file_line = all_content.split("\n")
for line in file_line:
if '.m3u8' in line:
url = url.rsplit("/", 1)[0] + "/" + line # 拼出第二层m3u8的URL
all_content = requests.get(url).text
file_line = all_content.split("\n")
unknow = True
key = ""
for index, line in enumerate(file_line): # 第二层
if "#EXT-X-KEY" in line: # 找解密Key
method_pos = line.find("METHOD")
comma_pos = line.find(",")
method = line[method_pos:comma_pos].split('=')[1]
print("Decode Method:", method)
uri_pos = line.find("URI")
quotation_mark_pos = line.rfind('"')
key_path = line[uri_pos:quotation_mark_pos].split('"')[1]
key = get_key(key_path)
print("key:", key)
if "EXTINF" in line: # 找ts地址并下载
unknow = False
pd_url = url.rsplit("/", 1)[0] + "/" + file_line[index + 1] # 拼出ts片段的URL
# print pd_url
res = requests.get(pd_url)
c_fule_name = file_line[index + 1].rsplit("/", 1)[-1]
if len(key): # AES 解密
iv = Random.new().read(AES.block_size)
cryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC)
with open(os.path.join(download_path_decode, c_fule_name + ".mp4"), 'ab') as f:
f.write(cryptor.decrypt(res.content))
# else:
with open(os.path.join(download_path_encode, c_fule_name), 'ab') as f:
f.write(res.content)
f.flush()
if unknow:
raise BaseException("未找到对应的下载链接")
else:
print("下载完成")
merge_file(download_path_decode)
def merge_file(path):
os.chdir(path)
os.system("copy /b * new.tmp")
# os.system('del /Q *.ts')
# os.system('del /Q *.mp4')
os.rename("new.tmp", "new.mp4")
if __name__ == '__main__':
download(m3u8_url)可惜的是,这一切看上去很完美,视频依然无法播放。为什么不能播放,还得继续研究,待续吧,
技术参考:
1.python 下载M3U8文件对应的视频:
https://blog.csdn.net/m0_37932636/article/details/79650181
2.python爬取网站m3u8视频,将ts解密成mp4,合并成整体视频:
https://blog.csdn.net/a33445621/article/details/80377424