mysql分库分表
依据个人经验:数据库分表首先是进行预估数据量、数据的属性、以及维度的划分。分库分表中维度的选取是极为重要一个步骤,这个主要与所设计分表业务密切相关的。
数据量是基于目前数据的业务属性在未来的时间内递量,依次来评估数据所占的是硬盘大小。举个例子:股票期货交易的ticker数据,每天的行情变化数据量是一个不小的数字。
以A股为例:假设A股票每分钟变化10次,那么每天产生的行情数据为60*4*10 = 2400条数据,假设每年有250个交易日,那么股票A产生的数据量为2400*250 =600W条数据,假设A股市场有3000只股票,每年要存的数据量为600W*3000=180亿条数据。
面对这么大的一个数据量,第一层考虑将每只股票的行情放在一张表里,但是随时时间的推移,过个两三年那么每个股票的行情表的数据量量就达到千万了,而且数据量只会越来越大,只能事先把分库分表策略写好。所以,第二层考虑的是将每只股票的行情数据再进行分表。接下来考虑记录所有分表的位置的配置表的结构------设定每张表最大可以存的数据量,以时间的开始和结束作为每张行情表的范围标记,因为历史航行多用于数据分析和策略,所以准确性也是非常重要的;通常情况下会选多路数据进行对比,所以数据来源也是分表的重要标志;另外当每个库的表数以及数据库的数量达到一定时,这个时候就会考虑新增数据库服务器,所以用来记录每张份表的配置表可以设计成如下:
CREATE TABLE `server_config` (
`configId` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增长ID',
`serverHost` varchar(50) NOT NULL COMMENT '服务器Host',
`dbName` varchar(50) NOT NULL COMMENT 'db名称',
`tableName` varchar(30) NOT NULL COMMENT '表格名称',
`dbUser` varchar(50) NOT NULL COMMENT 'db访问的用户名',
`dbPwd` varchar(50) NOT NULL COMMENT 'db访问用户对应的密码',
`tableName` varchar(30) NOT NULL COMMENT '表格名称',
`symbol` varchar(10) NOT NULL COMMENT 'symbol',
`exchange` varchar(20) NOT NULL COMMENT '交易所',
`beginTime` datetime(3) DEFAULT NULL COMMENT '行情数据开始时间',
`endTime` datetime(3) DEFAULT NULL COMMENT '行情数据结束时间',
`totalCount` int(11) DEFAULT NULL COMMENT '目前总的数据量',
`countLimit` int(11) NOT NULL DEFAULT '5000000' COMMENT '每张表存的数量上线',
`state` tinyint(1) NOT NULL DEFAULT '1' COMMENT '0、无效 1、有效',
`createTime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`lastUpdateTime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`configId`),
UNIQUE KEY `host_db_name` (`serverHost`,`dbName`,`tableName`)
) ENGINE=InnoDB AUTO_INCREMENT=1842 DEFAULT CHARSET=utf8 COMMENT '分库分表配置表'
配置表字段详解:
serverHost、 dbName、dbUser、dbPwd、tableName: 这几个字段是数据连接的几个基本属性,而且分库分表要考虑到多台机器的情况,所以服务器的信息是一定要存储的;这里的tableName名称,当遇到同一个symbol多张表的时候,会有规律的去新建表,譬如tableName_1|2|3|.....;
symbol和exchange是差不多是根据分库分表的主元素;
beginTime和endTime记录的是每张表数据的时间其实和结束范围,因为是交易的数据,所以这个时间维度至关重要的。数据的查询也要用到这两个字段进行的。
totalCount和countLimit也是限制每张表中存储的条数的关键字段。前者是当前表中所存的字段,后者是开发者设定的每张表最多存储的记录数量。
因为此次分表是将原有的存在几张表中十亿以上的数据进行拆分的,十几亿有点坑,所以在分表的时候遇到的几个坑也是值得参考的,由于数据量较大,在选数据的时候每次取了1万条,但是很慢。经排查是服务器的内存和网络带宽不够使用了,适当的扩了下服务器内存,增加了带宽,硬件配置若往往是硬伤;
在sql语句上有数据量大的时候要避免使用limit语句,因为limit中的startPo和endPos不是表面的直接查找这一段的数据,它会首先把重头开始遍历知道startPos,只是startPos之前的都会丢掉,可以换种写法,譬如select column from table_test where id >startPos limit XXX,这个前提是表中的自增Id是连续的,只有连续的时候Id才能代表记录的逻辑顺序;
看慢查询日志,将对应的慢查询sql语句找出来,使用explain和set profiling查找问题:
SET profiling=1;
SHOW PROFILES;(找出查询语句对应的query_id)

SHOW PROFILE FOR QUERY 6;
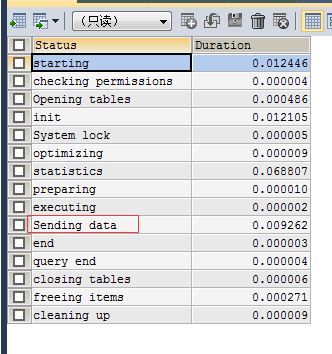
PS:使用limit不当的时候会当值sengding Data时间消耗特别多
代码层面的需要有的是批量读处理、批量写处理、建表相关(当某张表已满的时候需要新建表)、检查某张表是都达到设定的最多存储的数据量级别countLimit