目标检测系列——R-CNN
-
- 写在前面
- Abstract
- Introduction
- Object detection with R-CNN
-
- Module design
-
- Region proposals
- Feature extraction
-
- test-time detection
-
- Run-time analysis
-
- Training
-
- Supervised pre-training
- Domain-specific fine-tuning
- Object category classifiers
-
- Module design
-
- 解释分析
-
- 1,selective search选择性搜索是什么?
- 2,Bounding-box regression怎么做?
- 3,为什么要将建议框变形为227*227?怎么做?
- 4,CNN特征如何可视化?
- 5,为什么要进行非极大值抑制?怎么做?
- 6,为什么微调时和训练SVM时所采用的正负样本阈值不一致?(0.5,0.3)
- 7,CNN softmax层的输出也可以做分类,为什么还要使用SVM?
- 8,什么叫有监督预训练,为什么要进行有监督预训练?
- 9,可以不进行特定任务集下的微调吗?可以直接采用AlexNet CNN网络的特征进行SVM训练吗?
-
- R-CNN优缺点
-
- R-CNN创新点
- 可改进处
-
写在前面
这篇paper可以说是基于深度学习的目标检测方向的开山之作。很久前看了这篇论文,现准备把这一系列文章看一遍,并系统的做笔记于下。水平有限,多多批评指正。
论文:Rich feature hierarchies for accurate object detection and semantic segmentation
Abstract
近十年来以人工经验特征为主导的物体检测任务mAP提升缓慢。这其中表现最好的是将较低层次的图像特征和较高层次的语境相结合的集成系统。R-CNN在VOC2012上的mAP为53.3%,相较于传统的最优方法,有了30%的提升,可以看出,效果是非常好的。R-CNN有两个重要的贡献:
- 用CNN提取建议框的特征。避免了人工设计特征算法的盲目性。
- 任务数据不充足时,可在大容量的公共数据集上做有监督预训练,然后在任务数据上微调,效果也不差。
为什么被称作R-CNN呢?
这是因为论文将建议框(region Proposal)和CNN结合到了一起,R-CNN:Regions with CNN features。
Introduction
特征问题,近些年在各种视觉识别任务上用的最多的就是SIFT、HOG等特征。但是基于人工经验特征的集成系统的性能一直停滞不前。CNN在ImageNet识别任务竞赛中取得了极大的成功,那么能不能也将CNN用在目标检测任务中呢?要回答这个问题,首先就要比较图像分类和目标检测的差异点:
- 目标检测需要在图像中定位物体。解决定位问题的常用方法是回归,但是实际上这种框架效果并不理想。另外一种方法是采用滑动窗检测,在这种框架下,CNN在人脸、行人等检测任务上表现良好。为了保持较高的空间分辨率,这些CNNs通常只有2个卷积层和池化层。我们之所以没有采用滑动窗检测法的原因是我们网络层数较多,相应的感受野(192*192 pixels)和步长(32*32 pixels)较大,所以基于滑动窗的检测范式很难精确定位目标。我们解决CNN定位问题的方法是“借助区域框的识别”范式。这种范式在目标检测和语义分割方向表现极佳。在测试阶段,对每张图片首先生成~2000个候选建议框、用CNN对每个建议框生成定长的特征向量、用SVMs对每个建议框分类。为了使不同尺寸的建议框得到定长的特征向量,首先要对所有的建议框变形到同一尺寸,再用CNN提取特征。
- 目标检测任务的数据不充足。传统的解决方法是无监督的预训练和有监督的微调。我们的方法是先在较大的辅助数据集上做有监督的预训练、然后在具体任务集上做有监督的微调。
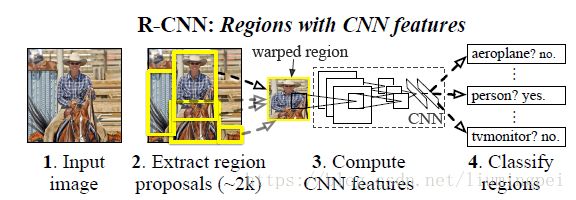
Object detection with R-CNN
我们的检测框架有3个模块:
- 生成建议框。这些建议框是后面进行检测的候选集合。
- 对每一个建议框使用CNN提取定长的特征。
对每一个建议框使用SVMs进行分类。
Module design
Region proposals
采用选择性搜索生成建议框
Feature extraction
arbitrary-shaped regions——–>fixed 227*227 RGB——–>5个conv layers——–>
2个fully connected layers——–>4096-dimensional feature vector.
test-time detection
测试过程
- 输入一张多目标图像,采用选择性搜索算法提取约2000个建议框。
- 先在每个建议框周围加上16个像素值为建议框像素平均值的边框,在直接变形为227*227的大小。
- 先将所有建议框减去该建议框像素平均值后,再依次将每个227*227的建议框输入至AlexNet CNN网络,获取4096维的特征【比以前的人工经验特征低两个数量级】,2000个建议框的CNN特征组合成2000*4096维特征矩阵。
- 将2000*4096维特征与20个SVM组成的权值矩阵4096*20相乘【20种分类,SVM是二分类器,则有20个SVM】,获得2000*20维矩阵表示每个建议框是某个物体类别的得分。
- 分别对上述2000*20维矩阵中每一列即每一类进行非极大值抑制,剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
- 分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
Run-time analysis
论文提到了两个特性提高了检测速度:
- CNN是参数共享的,同时这一点也能预防过拟合。
- 由CNN计算出的特征向量的维度远远低于人工经验特征的维度,可能会有两个至几个数量级的差别。
具体的时间开销,生成建议框和计算特征耗时情况(每张图片):
- 13s on GPU
- 53s on CPU
Training
Supervised pre-training
在ILSVR2012分类数据集上训练CNN。初始学习率为0.01。
Domain-specific fine-tuning
为了使我们预训练的CNN适用于检测任务和裁剪变换后的建议框,在预训练网络的基础上用SGD在变换后的建议框上训练CNN参数。训练之前我们要改变CNN的输出,将最后一层1000维的输出替换为N+1维的输出,目标的类别数是N,加上背景类。例如:VOC,N=20;ILSVRC2013,N=200;其中建议框与任一ground truth的IoU>0.5时,将此建议框归为正样本,其类别就是ground truth中物体的类别。其余的归为负样本,也就是背景类。初始学习率为0.001,每个mini-batch中32个正样本、96个负样本。
Object category classifiers
与微调时界定正负样本不同的是,在训练SVMs时,将ground truth作为正样本,将IoU<0.3的建议框作为负样本。
解释分析
1,selective search选择性搜索是什么?
我会在一篇文章中单独分析这个算法。
2,Bounding-box regression怎么做?
用SVM对每个建议框打分后(并经过非极大值抑制),就需要用Bounding-box regression将建议框回归到更合适的位置。所以我们要训练一个边界框回归器,输入是 N个点对
其中
前两个值是建议框中心点的坐标,后两个是宽度和高度。在不引起歧义的情况下,扔掉上标 i i ,那么每个ground-truth bounding box G具有同样的形式
我们的目标就是学到一种P—>G的变换。我们定义四个函数 dx(P),dy(P),dw(P),dh(P) d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) 来共同表示这个变换,所以每给定一个建议框,我么就可以用这四个变换函数得到predicted ground-truth box G^ G ^
每一个函数 d∗(P) d ∗ ( P ) 都被建模为线性函数,其中自变量为建议框经过CNN后pool5层得到的特征,为了方便,也可以表示为 ϕ5(P) ϕ 5 ( P ) 。因此我们有
其中 w∗ w ∗ 是可学习的模型参数,通过优化正则化后的最小二乘式来学习这些参数
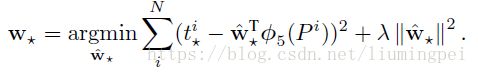
其中
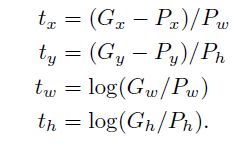
有几点值得注意:
- 正则化项蛮重要的。
- 如果建议框距离所有的ground-truth box都很远,那么这次变化就没有意思。
- 距离至少一个ground-truth box近的建议框才能作为训练数据,“近”如何度量呢?建议框和所有ground-truth box的IoU的最大值大于阈值0.6时,我们将该建议框标为训练数据。
3,为什么要将建议框变形为227*227?怎么做?
CNN必须提取定长的特征向量,不同尺寸的建议框送进CNN,得到的特征向量的维度是不同的,这显然不能送进同一组SVMs分类,所以要将建议框变形为227*227。SPP-Net、Fast-RCNN、Faster-RCNN对此都有改进,不需要变形也可以提取定长的特征向量。
将建议框变形为227*227时,采取的各向异性缩放warp,选取的padding为16。效果如下:上面的padding=0,下面的padding=16。

4,CNN特征如何可视化?
第一层filters能被直接可视化,并且很容易理解。可以认为他们捕获了基础的特征:
- 定向的边缘,oriented edgs;
对立的颜色,opponent colors。
理解随后的层就有些困难了。Zeiler和Fergus提出用反卷积的方法可视化,《Adaptive deconvolutional networks for midand high level feature learning》In CVPR,2011
论文中提出了一个简单的非参数化的方法,能直接展示网络学到了什么。论文采用了巧妙的方式将AlexNet CNN网络中Pool5层特征进行了可视化。该层的size是6*6*256,即有256种表示不同的特征,这就相当于原始227*227图片中有256种195*195的感受野,相当于对227*227的输入图像做卷积,卷积核大小为195*195,padding=4,stridding=8,输出大小为(227-195+2*4)/8+1=6*6。论文中将这些特征视为“物体检测器”,输入10million的region proposal集合,计算每种6*6特征即“物体检测器”的激活量,之后进行非极大值抑制,最后展示出每种6*6特征即“物体检测器”前几个得分最高的region proposal,从而给出了这个6*6的特征图表示了什么纹理、结构。
5,为什么要进行非极大值抑制?怎么做?
在测试过程完成到第四步之后,获得2000*20维矩阵,表示每个建议框是某个类别的得分情况,此时会遇到下图情况,同一个目标被多个建议框包围,这时需要非极大值抑制操作去除得分较低的候选框,以减少重叠框。
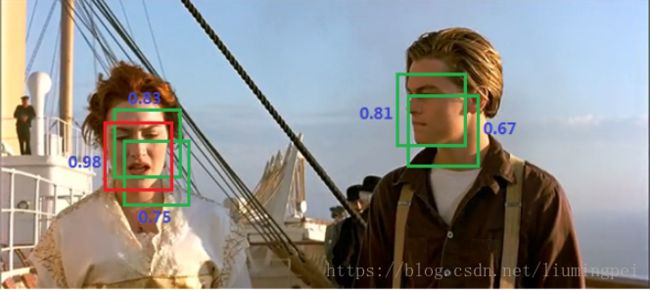
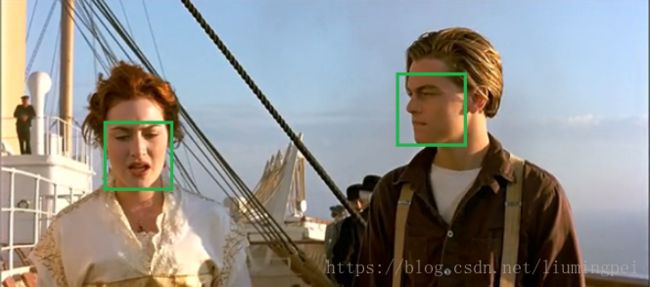
操作步骤:
- 对2000*20维矩阵中每列按从大到小排序。
- 从每列最大的得分建议框a开始,分别与该列后面的得分建议框b进行IoU计算,若IoU>阈值,则剔除得分建议框较小的,否则保留该建议框b,并认为图像中存在多个同一类物体。
- 从每列次大的得分建议框开始,重复2。
- 重复3,直到遍历完该列所有建议框。
- 遍历完20列,即所有物体种类都做一遍非极大值抑制。
- 最后剔除各个类别中剩余建议框得分少于该类别阈值的建议框。
6,为什么微调时和训练SVM时所采用的正负样本阈值不一致?(0.5,0.3)
- 微调阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IoU限制宽松:Ground Truth + 与Ground Truth 相交IoU>0。5的建议框为正样本,否则为负样本;
- SVM适用于小样本训练,故对样本IoU限制严格:与Ground Truth相交IoU<0.3的建议框为负样本,正样本是Ground Truth。
7,CNN softmax层的输出也可以做分类,为什么还要使用SVM?
作者先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于SVM训练。这个是因为SVM和CNN训练过程中的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用SVM精度还低。
- CNN在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练CNN,微调阶段正样本的定义并不强调精确的位置。
- 采用这种方法的主要原因在于CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对bounding box的位置限制的比较宽松,IoU>0.5都被标注为正样本。
- 然而训练SVM的时候,因为SVM适用于少样本训练,所以对于训练样本数据的IoU要求比较严格,只有当bounding box把整个物体都包含进去了,才把它标注为正样本。
- 在采用softmax会使PACAL VOC2007上mAP从54.2%下降到50.9%。
8,什么叫有监督预训练,为什么要进行有监督预训练?
有监督预训练也称为迁移学习,例如:若有大量标注信息的人脸年龄分类的正负样本图片,利用样本训练了CNN网络用于人脸年龄识别;现在要通过人脸进行性别识别,那么就可以去掉已经训练好的人脸年龄识别网络的最后一层或最后几层,换成所需要的分类层,前面层的网络参数直接用训练好的人脸年龄识别网络对应的参数。修改的最后几层的参数采用随机初始化,在利用人脸性别分类的正负样本图片进行训练,得到人脸性别识别网络,这种方法就叫做有监督预训练。
- 这种方式可以很好的解决小样本数据无法训练深层CNN网络的问题,小样本数据训练很容易造成网络过拟合,但是在大样本训练后利用其参数初始化网络可以很好的训练小样本,这解决了小样本训练的难题。
9,可以不进行特定任务集下的微调吗?可以直接采用AlexNet CNN网络的特征进行SVM训练吗?
文中设计了没有进行微调的对比试验,分别就AlexNet CNN网络中的pool5、fc6、fc7层进行特征提取,输入SVM进行训练,这相当于把AlexNet CNN网络当做万金油使用,类似HOG、SIFT等做特征提取一样,不针对特定任务。试验结果发现fc6层提取的特征比fc7层的mAP还高。因此得出结论:不针对特定任务进行微调,而将CNN当做特征提取器,pool5得到的特征是基础特征,类似于HOG、SIFT,类似于只学习到了人脸共性特征;从fc6和fc7等全连接层中所学到的特征是针对特定任务特定样本的特征,类似于学到了分类性别分类年龄的个性特征。
R-CNN优缺点
R-CNN创新点
- 采用CNN网络提取图像特征,从经验驱动的人造特征范式HOG、SIFT到数据驱动的表示学习范式,提高特征对样本的表示能力。学到的特征数量远少于人造特征。
- 采用大样本下有监督预训练+小样本微调的方式解决小样本难以训练甚至过拟合等问题。
可改进处
- R-CNN有些麻烦,不是端到端的系统。选择性搜索生成建议框、CNN提取特征、SVM分类、非极大值抑制筛选、回归器回归位置。
- R-CNN需要跑两次CNN模型,第一次得到分类的结果,第二次跑出来的pool5做回归。也可以用磁盘记录pool5的结果,但是十分吃内存。
- 在R-CNN的基础上提出了fast-rcnn,它解决了R-CNN跑两次CNN才分别得到classification和bounding-box,创新处在于ROI层的提出。