Fast R-CNN文章详细解读
文章《Fast R-CNN》,是在SPP-net的基础上对R-CNN的再次改造。
关于R-CNN的细节请查看R-CNN文章详细解读,关于SPP-net的细节请查看SPP-net文章详细解读
先来回顾一下R-CNN和SPP-net的缺点:
1.R-CNN的缺点
训练分为多个阶段。首先要使用search selective算法从输入图像提取约2000个候选区域,其次要训练CNN网络,最后还要训练SVM进行分类、训练bbox回归器进行更为精确的位置定位。
训练需要花费大量的时间和空间。因为是分阶段的,CNN将候选区域的特征提取出来以后要都存入硬盘中,之后取出用于训练SVM和bbox回归器,存储特征需要耗费大量的硬盘空间,而且读写过程会造成时间的损耗。
检测阶段特别耗时。因为检测时也是对带检测图像中的候选区域进行检测,没个候选区域都要进行前向传播,所以检测一张图像特别耗时。
2.SPP-net的缺点
虽然SPP-net对R-CNN有所改进,即引入了SPP层,使得网络在检测时不需要对每个候选区域进行前向传播,但它也继承了R-CNN的缺点并引入了新的缺点。
类似于R-CNN
训练需要分多阶段进行
需要将特征存入硬盘
引入的新的缺点
- 在fune-tuning阶段不能对SPP层下面所有的卷积层进行后向传播(如下图所示)

这部分新引入的缺点的原因,作者也花了点时间解释,因为在fine-tuning的时候,R-CNN和SPP-net都是取mini-batch为128,其中32个正样本,96个负样本,而这些正负样本通常来自不同的图片。在这样的fine-tuning策略下,当训练样本不是同一个图片的时候,SPP层的更新效率会非常低,效率低的根本原因是每个RoI区域的感受野可能会非常大(对于这句话我的理解是,因为在SPP-net文章详细解读中计算感受野坐标时是一个约等的关系,在卷积后输出的特征图中对应的感受野的大小会比RoI的实际大小要大)。为什么感受野大效率就会低,我的理解是,因为如果样本不是来自一个图片,在一次mini-batch训练更新完样本后,下次还的重新计算整张图片的feature map,这样会增加很多计算量,这里仅是个人理解。
针对上述的缺点,Fast R-CNN就问世了,先看看Fast R-CNN的训练框架,如下图所示
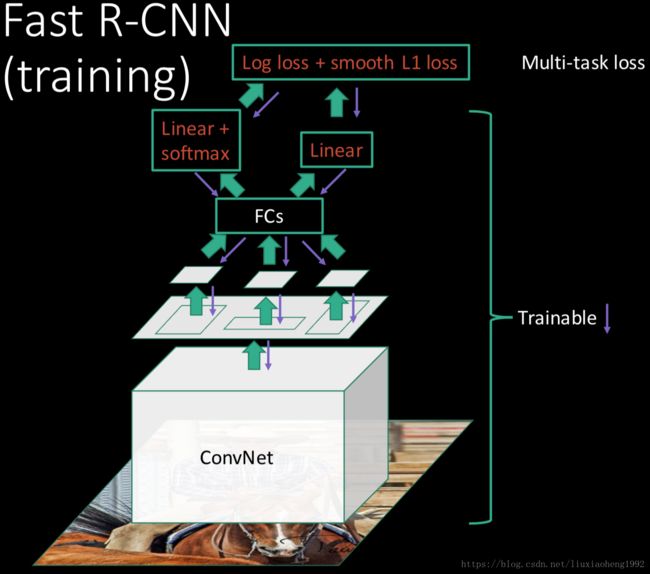
Fast-RCNN作了以下改动:
训练机制有所改变,不再类似于R-CNN那样使用均匀的随机采样128个训练样本,而是分层采样,先随机采样N张图片,然后从每张图片中采样R/N个RoIs,例如N=2,R=128,那么每次做SGD的时候,有64个样本来自同一张图像,这样正反向都会有加速。这里选取 IoU≥0.5 I o U ≥ 0.5 作为正样本, IoU在区间[0.1,0.5) I o U 在 区 间 [ 0.1 , 0.5 ) 之间的为负样本
网络结构作了改变,首先是采用了SPP-net中的SPP层,只不过不同于SPP层的是,没有多尺度的pooling,只有一个尺度的pooling(可以理解为特殊的SPP层),其次引入了多任务损失函数,用于同时计算bbox回归和分类的损失。
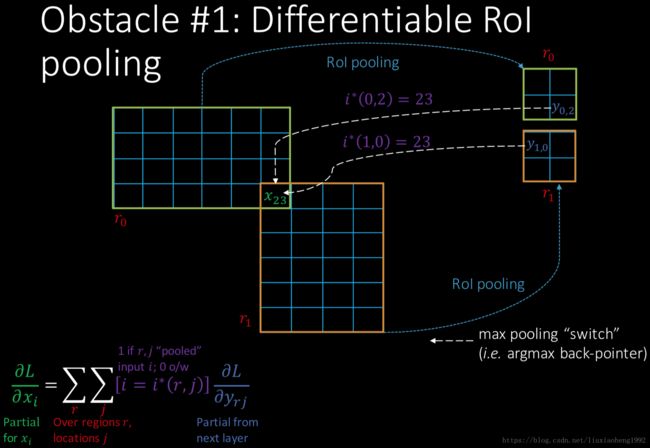
先来看一下RoI层的反响传播的计算方法,如下图所示
假设下图中大的绿色框和黄色框都是候选区域在feature map对应的区域,这里RoI pooling的大小为2*2的(如下图中小的绿色和黄色框)
反向传播的函数为:
∂L∂xi=∑r∑j[i=i∗(r,j)]∂L∂yrj ∂ L ∂ x i = ∑ r ∑ j [ i = i ∗ ( r , j ) ] ∂ L ∂ y r j
其中,r表示第几个候选区域,j表示输出的第几个节点, [i=i∗(r,j)] [ i = i ∗ ( r , j ) ] 表示i节点是否被候选区域r的第j个节点选为最大值输出。
再来看一下为便于训练而提出的多任务损失函数
在FC层后接入了两个分支,一个是softmax用于对每个RoI区域做分类,假如有K类待分(加上背景总共K+1类),输出结果为 p=(p0,…,pK) p = ( p 0 , … , p K ) ,另一个是bbox,用于更精确的定位RoI的区域,输出结果 tk=(tkx,tky,tkw,tkh) t k = ( t x k , t y k , t w k , t h k ) 。
多任务损失函数定义为:
L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v) L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v )
上式中, Lcls(p,u)=−logpu L c l s ( p , u ) = − l o g p u 是个log形式的损失函数, Lloc L l o c 中 v=vx,vy,vw,vh v = v x , v y , v w , v h 是类为 u u 的真实框的位置而 tu=(tux,tuy,tuw,tuh) t u = ( t x u , t y u , t w u , t h u ) 是类为 u u 的预测框位置。 [u≥1] [ u ≥ 1 ] 为1当 u≥1 u ≥ 1 ,反之为0。文中实验时 λ=1 λ = 1 。
上式中, Lloc L l o c 定义为:
Lloc(tu,v)=∑iϵ{x,y,w,h}smoothL1(tui−vi) L l o c ( t u , v ) = ∑ i ϵ { x , y , w , h } s m o o t h L 1 ( t i u − v i )
其中
smoothL1(x)={0.5x2|x|−0.5if|x|<1otherwise s m o o t h L 1 ( x ) = { 0.5 x 2 i f | x | < 1 | x | − 0.5 o t h e r w i s e
文中认为 L1 L 1 对于噪点相比于 L2 L 2 更不敏感,所以使用 L1 L 1 正则是的模型更为鲁棒。
到这里就讲完了Fast R-CNN,文章还有一些实验,以及通过SVD奇异值分解来多FC层提速,好像这样做的比较少,感兴趣的可以看一下原文。
参考
1.http://www.robots.ox.ac.uk/~tvg/publications/talks/fast-rcnn-slides.pdf
2.https://blog.csdn.net/shenxiaolu1984/article/details/51036677