机器学习之随机森林
随机森林具体的构建方法是
(1)从原始样本集m个样本中使用bootstrap采样法选出m个样本;
(2)从所有n个属性中随机选择k个属性(若k=n则基决策树的构建与传统的决策树相同,若k=1则是随机选择一个属性用于划分),一般令k的值为log2n;
(3)选择最佳分割属性(ID3、C4.5、CART)作为节点创建决策树;
(4)每棵决策树都进行最大程度地生长,且不进行剪枝;
(5)重复以上4步S次,建立S棵决策树,即形成随机森林;
(6)在分类问题中通过多数投票法决定输出属于哪一分类;在回归问题中输出所有决策树输出的平均值。
随机森林的主要优点
(1)实现简单、准确率高;
(2)并行训练,计算开销小,能够高效地对大数据集进行训练;
(3)能够处理高维特征的输入样本,且不需要降维操作;
(4)能够评估各个特征在分类问题上的重要性;
(5)对部分特征的缺失不敏感;
(6)能够取到内部生成误差的一种无偏估计,不需要交叉验证或者用一个独立的测试集获得误差的无偏估计;
(7)由于存在随机抽样,训练出来的模型方差小,泛化能力强。
随机森林的主要缺点
(1)在某些噪音比较大的特征上,RF模型容易陷入过拟合;
(2)取值比较多的特征对RF的决策会产生更大的影响,有可能影响模型的效果;
(3)随机森林解释性不强,有点像黑盒模型。
RF袋外估计
随机森林分类效果与两个因素有关:
(1)RF中任意两棵树的相关性越大(即特征选择个数k增大),则整个森林的错误率就越高;
(2)RF中每棵树的分类能力越强(即特征选择个数k减小),则整个森林的错误率就越低。
因此关键问题在于如何选择最优的k值,这也是RF唯一的一个参数。
在构建每棵树时,原数据集中有36.8%的样本成为该树的oob样本,oob估计是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的k折交叉验证,计算方式为:
对每个样本,计算它作为oob样本的树对它的分类情况(约36.8%的树);
然后以简单多数投票作为该样本的分类结果;
最后用误分个数占样本总数的比率作为随机森林的oob误分率。
特征重要度
对于一个高维度数据集,如何在其中选择影响比较大的特征,以减少特征维度是我们比较关心的问题,降维的方法有很多,比如PCA、LDA、LASSO等。在这里可以用随机森林来对特征重要度进行考量。
作为单个的决策树模型,在模型建立时实际上是寻找到某个特征合适的分割点,这个信息可以作为衡量所有特征重要性的一个指标。基本思想是,如果一个特征被选为分割点的次数越多,那么这个特征的重要性就越强,推广到集成算法中,是将每棵树的特征重要性取均值。
评价指标一般为Gini index(或oob等),在sklearn中可直接调用封装好的方法:rf.feature_importances_
使用Gini指数对特征属性重要度进行排序时,会偏向于选择取值范围较大的特征;当存在相关特征时,一个特征被选择后,与其相关的特征的重要度会变得很低,因为它们可以减少的不纯度已经被前面的特征移除了。
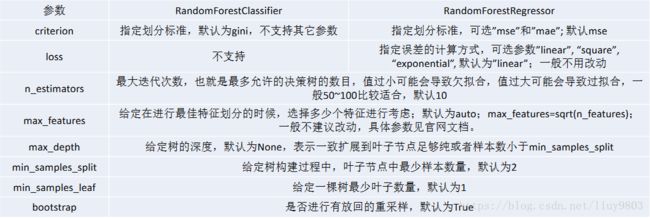
RF scikit-learn相关参数
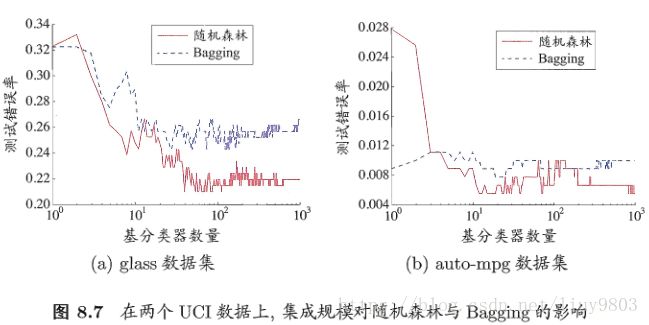
集成规模对随机森林与Bagging的影响(西瓜书)
RF的收敛性与Bagging相似,RF的起始性能往往相对较差,这是因为通过引入属性扰动,RF中个体学习器的性能往往有所降低。然而随着个体学习器数目的增加,RF通常会收敛到更低的泛化误差。
RF的推广算法
RF算法在实际应用中具有比较好的特性,应用也比较广泛,如:分类、回归、特征转换、异常点检测等。常见的RF变种算法有:Extra-Trees(ET)、Totally Random Trees Embedding(TRTE)、Isolation Forest
1、Extra-Trees(Extremely Randomized Trees)
ET原理类似RF,区别如下:
(1)RF会使用bootstrap采样来作为决策树的训练集。而ET每个子决策树采用整个原始数据集进行训练;
(2)RF选择划分特征时会和传统决策树一样,基于信息增益、信息增益率、基尼指数、均方差等原则来选择最优特征值。而ET则随机选择一个特征划分决策树,训练速度优于RF(寻找最优分割属性比较耗时)。
因为ET是随机选择特征的划分点,比RF多一层随机性,这样会再次增加偏差、减小方差,导致决策树的规模一般大于RF所生成的决策树,在某些情况下泛化能力更强。
构建好ET后,可以用全部的训练样本得到其预测误差,方法与RF相同。
2、TRTE(Totally Random Trees Embedding)
TRTE是一种非监督的数据转化方式,将低维的数据映射到高维稀疏表示,从而让映射到高维的数据更好的应用于分类回归模型。sklearn的文档描述的很清楚:
An unsupervised transformation of a data set to a high-dimensional sparse representation.A data point is coded according to which leaf of each tree it is sorted into. Using a one-hot encoding of the leaves, this leads to a binary coding with as many ones as there are trees in the forest.
The dimensionality of the resulting representation is n_out <= n_estimators * max_leaf_nodes. If max_leaf_nodes == None, the number of leaf nodes is at most n_estimators * 2 ** max_depth.
TRTE算法的转换过程类似RF,例如建立3个决策树来拟合数据,每个决策树有5个叶子节点。当决策树构建完成后,数据集里的每个数据在决策树中叶子节点的位置就定下来了:设某个数据特征x划分到第一棵决策树的第2个叶子节点、第二棵决策树的第3个叶子节点、第三棵决策树的第5个叶子节点,则x映射后的特征编码为(0,1,0,0,0, 0,0,1,0,0, 0,0,0,0,1),即15维的稀疏特征,完成了将位置信息转换为向量的特征转换操作。
3、Isolation Forest(IForest)
IForest(孤立森林)是一种异常点检测算法,使用类似RF的方式来检测异常点,IForest算法与RF算法的区别在于:
(1)在随机采样的过程中,一般只需要取得少量的数据即可;
(2)在进行决策树构建过程中,IForest算法会随机选择一个划分特征,并对划分特征随机选择一个划分阈值;
(3)IForest算法构建的决策树一般深度是比较小的。
区别原因:目的是异常检测,所以只要能够区分异常的数据即可,不需要大量的数据;在异常点的检测过程中,一般不需要构建太大规模的决策树(在前几个分支就可以判断出异常点)。
对于异常点的判断,则是将测试样本x拟合到T棵决策树上,计算在每棵树上该样本的叶子结点深度ht(x),从而计算出平均深度h(x);然后就可以使用下列公式计算样本点x的异常概率值,p(s,m)的取值范围为[0,1],越接近于1,则该点是异常点的概率就越大。
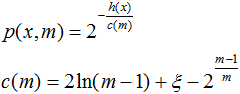 ;其中m为样本个数,ξ为欧拉常数
;其中m为样本个数,ξ为欧拉常数