深度学习典型卷积神经网络之GoogLeNet
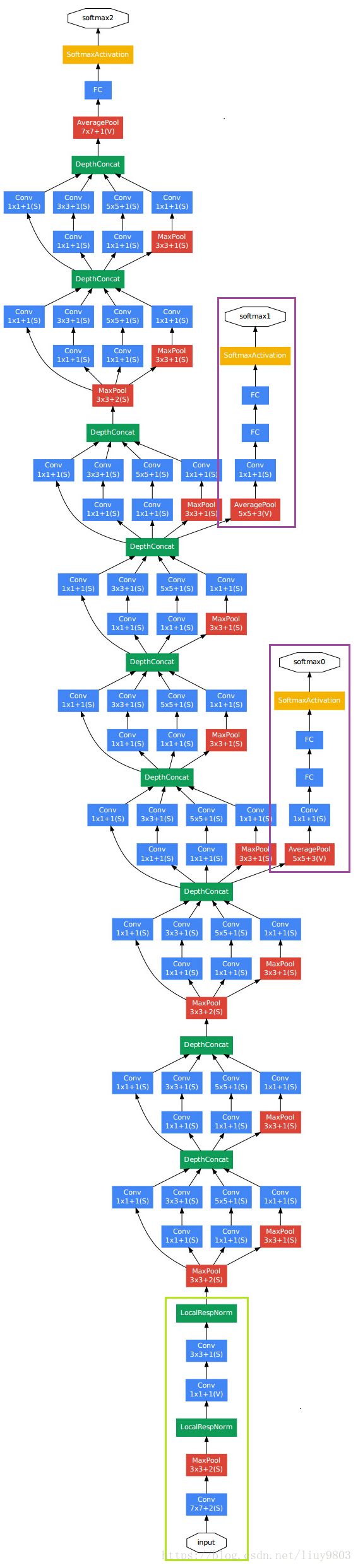
GoogLeNet是2014年ILSVRC的冠军,top5错误率为6.7%,深度达到22层(加上池化是27层),使用9个inception模块让网络变得更“宽”,改变CNN原有的串行结构;使用全局平均池化替代FC层,但实际上在最后还是加了一个全连接层,便于以后进行微调。总参数量仅为AlexNet(6000万)的1/12(500万);GoogLeNet的结构如下所示,其中绿色框内的是stem,包含一些初始卷积;紫色框内是辅助分类器auxiliary classifiers,将中间某一层的输出用作分类,并按一个较小的权重0.3加到最终分类结果中,便于传递梯度、提供额外的正则化,辅助分类器只在训练中使用,在测试时会去掉。
total_loss = real_loss + 0.3 * aux_loss_1 + 0.3 * aux_loss_2
一、Network-in-Network
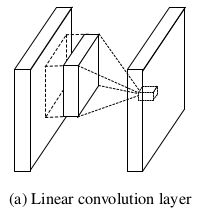
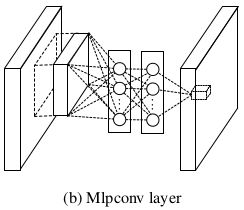
1、多层感知卷积层(MLPConv Layer):
卷积层是对低层的特征通过某种运算的组合——广义线性模型GLM(作者认为CNN有一个假设就是潜在的概念是线性可分的)。然而真实数据往往是非线性可分的,因此作者使用Conv+MLP代替线性卷积操作,增强网络提取抽象特征和泛化能力。MLPConv可看做是每个卷积的局部感受野中包含了一个微型的多层网络。级联的跨特征图整合过程,可以使网络学习到复杂和有用的特征,跨通道的参数化感知层等效于一个1*1的卷积。选择MLP的原因在于它是通用的近似函数,与CNN兼容,可以自行深度化(特征重用),而且可以使用BP算法进行训练。
2、全局平均池化层(Global Average Pooling):
Global pooling是池化filter的尺寸和feature map的尺寸相同,将3维的输入张量转换为1维的输出向量,分为GMP、GAP等。GAP使用特征图与类别一致性的思想,用每个特征图中的值总和求平均,再将这些数字作为属于某个类别的置信值,输入softmax中进行分类,代替传统的全连接层。这种方法的优点在于:
GAP更原生的支持卷积结构,特征映射可以很容易地解释为分类映射;
GAP没有需要优化的参数,可以加速训练并避免过拟合;
GAP汇总了空间信息,因此对于空间变换是稳定的。


GoogLeNet借鉴了NIN的特性,在原先的卷积过程中增加了1*1的卷积,不仅可以跨通道组织信息、增加网络深度、提高网络的表达能力,还可以对输出通道进行升维和降维、减少了参数更新量。
二、Inception系列
Inception的主要思想是找出如何让已有的稠密组件接近与覆盖卷积视觉网络中的最佳布局稀疏结构。Inception模块会并行计算不同卷积核以提取不同种类的信息,由模型下一层决定是否以及怎样使用各类信息;同时为了解决计算量过大的问题,使用1*1的卷积核进行降维。Inception可以将不同的层堆叠到一起,得到既深又宽(并行)的网络。
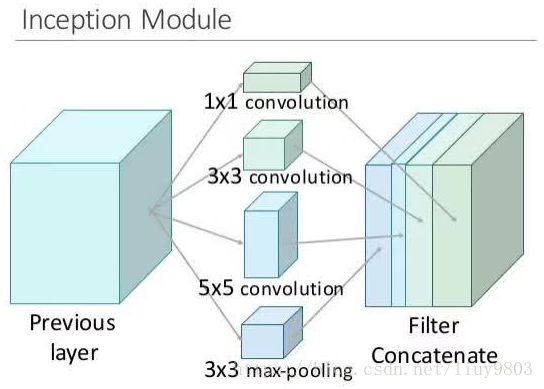
1、Inception-v1/GoogLeNet
原始版本是将1*1、3*3、5*5的Conv和3*3的Max pooling堆叠在一起,由于计算量很大,改进版本在3*3、5*5前面和pooling后面加上1*1的卷积用于限制输入信道数量(1*1的卷积相当于为每个像素施加全连接层,又称NIN)。

2、Inception-v2
加入BN层,减少了Internal Covariate Shift(内部神经元数据分布变化),使每一层的输出都规范化为N(0,1)的高斯分布。
使用2个3*3的卷积代替1个5*5的卷积,降低参数数量并加速训练。由于过多地减少维度可能会造成信息损失,为了减少特征的表征瓶颈,使用Factorization因式分解,将n*n的卷积分解为1*n和n*1的非对称卷积的串联,可以加速训练并减轻过拟合。这种非对称的卷积结构拆分的结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更丰富的空间特征,增加特征多样性。3种类型的inception:
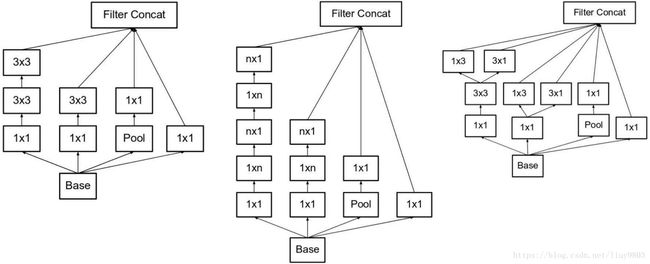
3、Inception-v3
作者注意到辅助分类器直到训练快结束时才有较多的贡献,那时的准确率接近饱和,作者认为辅助分类器的功能是正则化,尤其是它们具备BN或Dropout操作时。
Inception-v3整合了v2中提到的所有升级,还使用了RMSProp优化器、factorized 7*7卷积、辅助分类器BN和标签平滑LSR。
标签平滑(label smoothing regularization):
为了缓解由label不够soft而过拟合的正则方法,对于K分类问题,将类别one-hot后使用softmax预测:
![]()
![]() 为未被归一化的对数概率logits,q为ground-truth分布,则分类问题的损失函数用交叉熵及导数表示为:
为未被归一化的对数概率logits,q为ground-truth分布,则分类问题的损失函数用交叉熵及导数表示为:
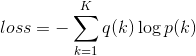
![]()
![]()
当ground-truth为one-hot即每个样本只有唯一的类别时:
![]()
泛化能力差,容易导致过拟合问题;鼓励所属类别和非所属类别之间的距离尽可能大,且梯度有界,降低模型的适应能力,这种情况源于模型过于相信预测的类别。
因此提出一种使模型less confident的标签平滑机制,令u(k)为一个与样本x无关的先验标签分布(根据经验使可以使用均匀分布u(k)=1/K),ε为平滑参数,将真实的q替换为q`:
![]()
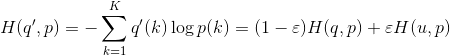
如果某个 ![]() 远大于其他值,则单独的q(k)将趋近于1,其他的趋近于0,且所有q`有正数的下界,那么会得到很大的交叉熵。LSR可以避免最大的
远大于其他值,则单独的q(k)将趋近于1,其他的趋近于0,且所有q`有正数的下界,那么会得到很大的交叉熵。LSR可以避免最大的 ![]() 远大于其他值,将一个交叉熵替换为两个损失函数,后者为预测类别p与先验分布u的惩罚项:
远大于其他值,将一个交叉熵替换为两个损失函数,后者为预测类别p与先验分布u的惩罚项:![]() 。论文中K=1000,u(k)=1/1000,ε=0.1,对分类性能有0.2%的提升。
。论文中K=1000,u(k)=1/1000,ε=0.1,对分类性能有0.2%的提升。
4、Inception-v4
Inception-v4比v3的结构更简洁,并拥有更多的inception模块,左图为v4的结构,右图为v4和Inception-ResNet-v2的stem部分,其中标V的卷积或池化层使用tf的valid padding(不进行填充),不标V的卷积使用same padding(输入输出空间维度相同,一般使用全零填充)。
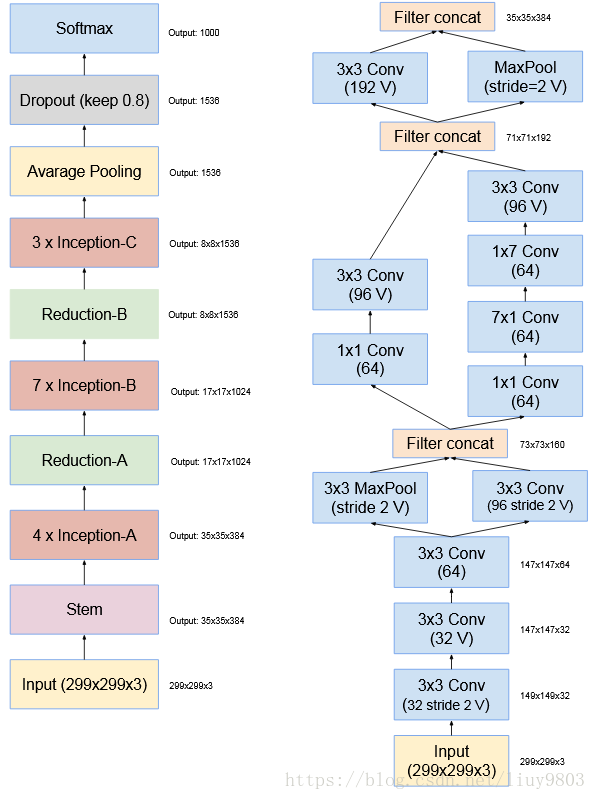
v4的其他部分结构如下,并引入缩减块(reduction module)改变网络的宽高:
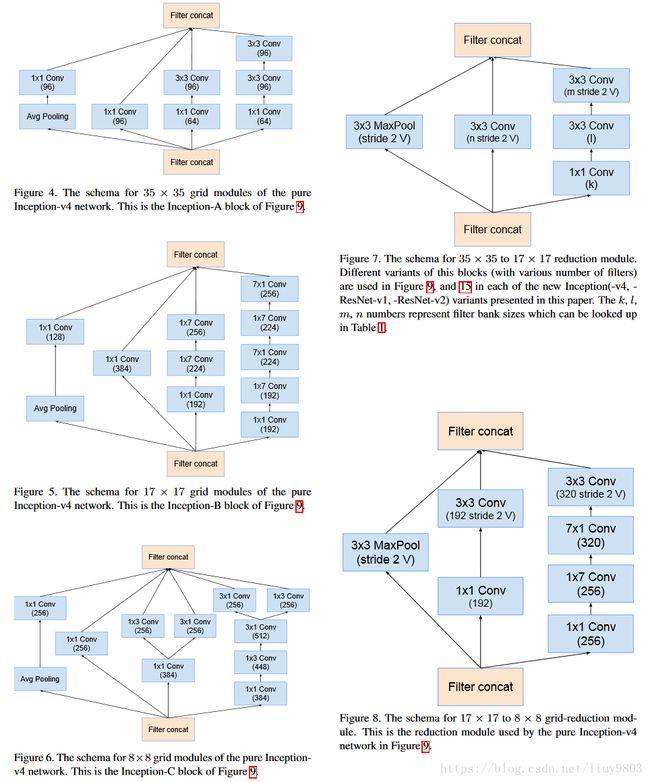
5、Inception-ResNet-v1、v2
受 ResNet优越性能的启发,作者将inception和残差模块组合,介绍了Inception-ResNet-v1 和 v2两个版本,其中Inception-ResNet-v1 的计算成本和 Inception-v3 接近;Inception-ResNet-v2 的计算成本和 Inception-v4 接近。左图v1、v2的结构,右图为v1的stem:
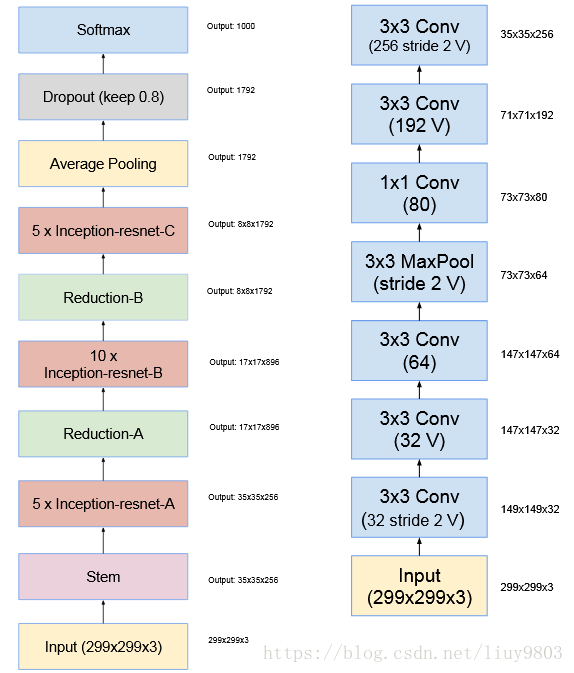
v1、v2有相同的模块 A、B、C 和缩减块结构。唯一的不同在于超参数设置。为了使残差加运算可行,卷积之后的输入和输出必须有相同的维度。因此在初始卷积之后使用 1x1 卷积来匹配深度(深度在卷积之后会增加)。注意池化层被残差连接所替代,并在残差加运算之前有额外的 1x1 卷积。
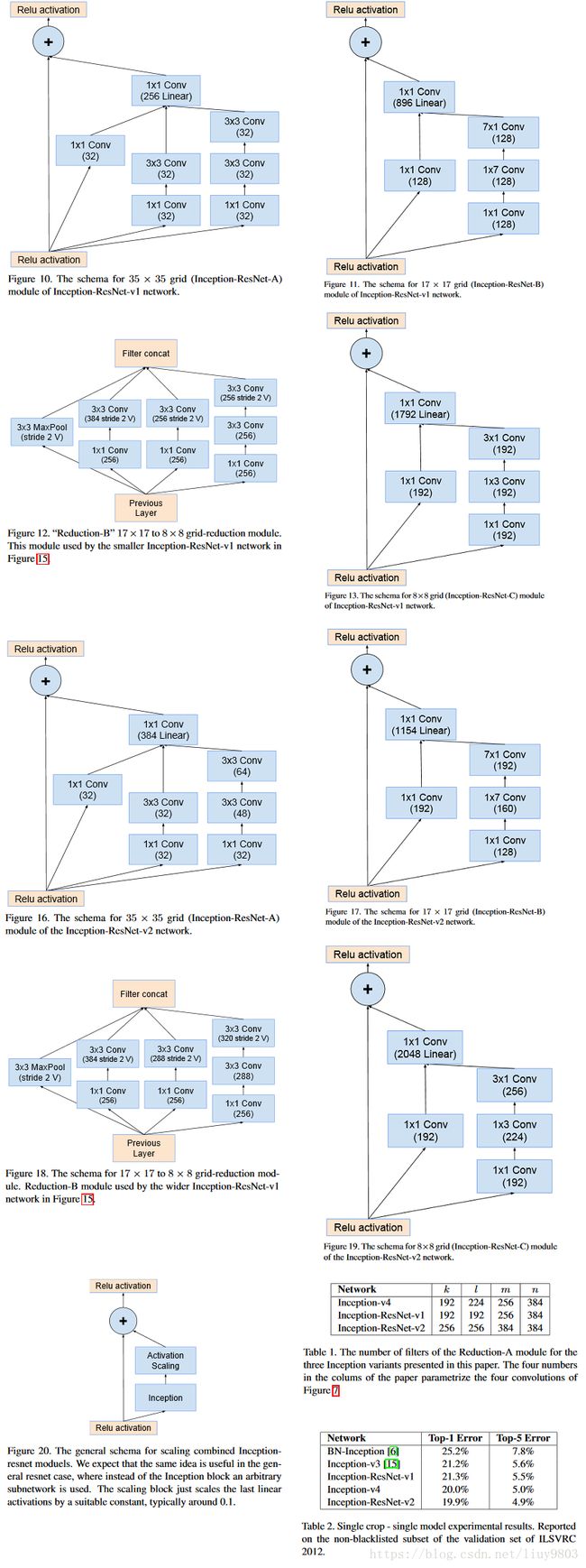
如果卷积核的数量超过 1000,则网络架构更深层的残差单元将导致网络崩溃。因此为了增加稳定性,作者通过 0.1 到 0.3 的比例缩放残差激活值。
论文中只在传统的前几层使用BN,而不在求和之后使用,是为了确保每个模型副本在单个GPU上是可训练的,It turned out that the memory footprint of layers with large activation size was consuming disproportionate amount of GPU-memory. 在更好地利用计算资源与加速训练之间进行权衡。
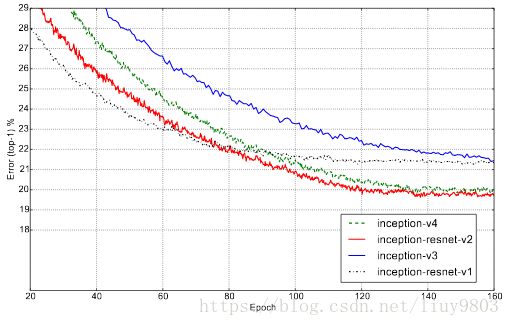
训练时使用RMSProp优化器,γ=0.9,ϵ=1.0,学习率=0.045,每两个epoch衰减指数0.94。通过集成3个Inception-ResNet-v2和一个Inception-v4的模型top-5错误率可以达到3.08%。
参考资料
http://baijiahao.baidu.com/s?id=1601882944953788623&wfr=spider&for=pc
https://arxiv.org/pdf/1512.00567.pdf
https://arxiv.org/pdf/1602.07261v1.pdf