web爬虫学习(六)——CSS反爬加密彻底破解
笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据助跑每一个人,欢迎直筒们关注我的公众号,大家一起讨论数据中的那些有趣的事情。
我的公众号为:livandata

0 惯性嘚瑟
刚开始搞爬虫的时候听到有人说爬虫是一场攻坚战,听的时候也没感觉到特别,但是经过了一段时间的练习之后,深以为然,每个网站不一样,每次爬取都是重新开始,所以,爬之前谁都不敢说会有什么结果。

前两天,应几个小朋友的邀请,动心思玩了一下大众点评的数据爬虫,早就听说大众点评的反爬方式不一般,貌似是难倒了一片英雄好汉,当然也成就了网上的一众文章,专门讲解如何爬取大众点评的数据,笔者一边阅读这些文章寻找大众点评的破解思路,一边为大众点评的程序员小哥哥们鸣不平,辛辛苦苦写好的加密方式,你们这些爬虫写手们这是闹哪样?破解也就算了,还发到网上去,还发这么多~

笔者在阅读完这些文章之后,自信心瞬间爆棚,有如此多的老师,还有爬不了的网站,于是,笔者信誓旦旦的开始了爬大众点评之旅,结果,一上手就被收拾了,各个大佬们给出的爬虫方案中竟然有手动构建对照表的过程,拜托,如果我想手动,还要爬虫做什么?别说手动,半自动都不行。
大家看到这里或许头上有些雾水了,什么手动?什么半自动?还对照表?大佬,你这是什么梗?再不解释一些我就要弃剧了,葛优都拉不回来~

大家先不要着急,静一静~,对照表后面会讲,这里只需要知道我遇到困难了,就可以了,不过咨询了几个大佬之后,好在解决了,革命的路上虽有羁绊,终归还是有同志的~
好,现在开始入正题,点评的程序员哥哥请不要寄刀片:
1 基础环节
大众点评的数据爬虫开始还是很正常的,各个题目、菜单基本上都可以搞下来:
代码如下:
#!/usr/bin/env python
# _*_ UTF-8 _*_
# 个人公众号:livandata
import requests
from lxml import etree
header = {"Accept":"application/json, text/javascript",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
"Cookie":"cy=1; cye=shanghai; _lxsdk_cuid=16ca41d3344c8-050eb4ac8f1741-4d045769-1fa400-16ca41d3345c8; _lxsdk=16ca41d3344c8-050eb4ac8f1741-4d045769-1fa400-16ca41d3345c8; _hc.v=38ae2e43-608f-1198-11ff-38a36dc160a4.1566121473; _lxsdk_s=16ce7f63e0d-91a-867-5a%7C%7C20; s_ViewType=10"
}
url = 'http://www.dianping.com/beijing/ch10/g34060o2'
response = requests.get(url, headers=header)
data = etree.HTML(response.text)
title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[1]/a/@title')
print(title)
爬取的结果为:

按照常规的套路,爬虫可以说是写成了。但是,现在的网站大多使用了反爬,一方面担心自己的服务器会被爬虫搞的超负荷,另一方面也为了保护自己的数据不被其他人获取。

大众点评就是众多带反爬的网站中的佼佼者,使用了比较高级的反爬手法,他们把页面上的关键数字隐藏了起来,增加了爬虫难度,不信~你看:
2 CSS加密
我们用如下字段爬取商店的评论数:
data = etree.HTML(response.text)
title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[2]/a[1]/b/svgmtsi[1]/text()')
print(title)
结果得到的却是如下字段:
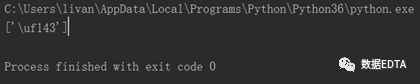
一看傻了,这是什么鬼?
我们紧接着审查了网站数据,看到的内容却是:

这是什么鬼?评论数呢?

查看了网站的源代码:

发现原来显示点评数的字段显示成了:
这是为什么呢?
好在网上的大神们给出了解答,这就是CSS加密。
接下来我们就介绍如何破解CSS加密:
我们把源代码上加密的部分取下来观察一下:
我们发现了网上一直在讨论的svgmtsi标签,这个标签是矢量图的标签,基本上意思就是显示在这里的文字是一个矢量图,解析这个矢量图需要到另外一个地方找一个对照表,通过对照表将编码内容翻译成人类可以识别的数字。

那么,对照表在哪里呢?
我们先记录下标签中的class值:shopNum(为什么记录,先不要着急,后面会讲到),然后在源代码中查找svg,我们发现了如下内容: 
大宝藏被挖掘了。
这好像是个链接,我们点击一下,发现页面跳转到了一个全新的水月洞天:
![]()
这真是个伟大的发现,他预示着我们的爬虫找到了门路,我们在这个页面上查找刚才class中的值shopNum,然后,我们看到了如下内容:
url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/bc2c52b3.woff");}
.shopNum{font-family: 'PingFangSC-Regular-shopNum';}@font-face{font-family:
"PingFangSC-Regular-reviewTag";
src:url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/07758223.eot");
在这段代码中距离shopNum最近的地方,我们找到一个woff文件。
你没有猜错,这个woff文件就是我们的对照表。
同样的思路,这是一个网址,我们可以把他下载下来,把这个网址复制到浏览器的地址栏中,点回车,会跳出如下快乐的界面。
下载完成后,我们在浏览器中打开woff的翻译工具:
http://fontstore.baidu.com/static/editor/index.html
我们把前面的&#x去掉并替换成uni,后面的;去掉,得到字段为:unif784。
秘密揭晓了:

是不是很眼熟?
是不是很惊喜?
是不是很意外?
恭喜你,第一步成功了~
这个编码在woff文件中对应的值为7。
就是我们要找的亲人~

3 woff文件处理
事情到这里其实就可以画个句号了,因为接下来的思路就变的非常简单了,我们用上面的通用爬虫下载下网站上所有编码和对应的class值,然后根据class值找到对应的woff文件,再在woff文件中确定编码对应的数字或汉字就可以。

但是,当我们扩充这一思路的时候却遇到了两个问题:
1)如何读取出woff文件中的数字,大众点评有多个woff文件,怎么对照读取呢?难不成要一个个写出来?根据前面网站里的文章来讲,对的,你猜的很准,这就是我文章一开始写的半自动,崩溃了吧,好在笔者找到了新的方法,取代了半自动的问题,这个新的方法就是OCR识别,后面我会仔细讲解。
2)页面的编码是变动的,你没有看错,这个值是会变的,好在这个事件没有发生在大众点评中,但是汽车之家、猫眼等网站使用的CSS加密会随页面的刷新发生变动,有没有惊到你?
如果你只需要大众点评,第二个问题几乎可以不用考虑了,但是笔者认为要做一个有理想的爬虫,尽量多的获取知识点才是正确的,所以,笔者研究了汽车之家、猫眼、天眼等几个用CSS加密的网站,找到了一个通用的方法,下面我们来介绍一下这个通用方法。
先看一下猫眼网站上编码的动态效果:
如图:
我们先找到一个加密编码,把他复制出来,看到的编码如下:
然后我们刷新一下页面,再看源码:

不管你惊不惊,反正我是惊到了~
针对这一变化,笔者心中产生了一个疑惑,如果说编码会变,那浏览器是怎么获取到准确的值的呢?说明一定存在一个统一的方法供浏览器调用,于是,笔者重新研究了编码的调用方式,惊奇的发现了其中的秘密:
我们以如下两个编码来揭露这个今天大幂幂:
-->unif0d5
-->unie765
这两个字段都是表示数字中的1,那他们有什么规律呢?
我们首先解码woff文件成xml格式:
from fontTools.ttLib import TTFont
font = TTFont('e765.woff')
font.saveXML('e765.xml')
在pycharm中我们打开xml文件:

找到unie765所在的位置:

这一串代码是字形坐标,浏览器就是根据这个字形坐标翻译出我们能够识别的汉字:1。
同样的思路,我们再去解析unif0d5的值,得到如下图:
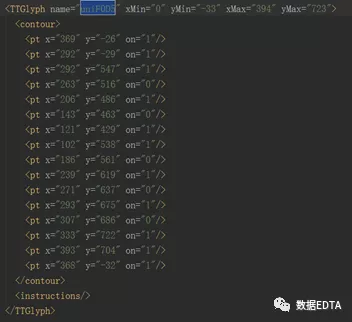
我们惊奇的发现,这两个竟然一样,是不是所有的值对应的字形坐标都是唯一的呢,答案是肯定的,变化的只是上图name中的编码,坐标与数字之间是一对一的,所以,我们的思路来了,我们只需要找到编码所对应的字形坐标,然后想办法解析出这个字形坐标所对应的数字就可以了。
4 完整思路
问题展示基本上清楚了,我们接下来看一下怎么自动化解决上面两个问题:
首先展示一下思路:
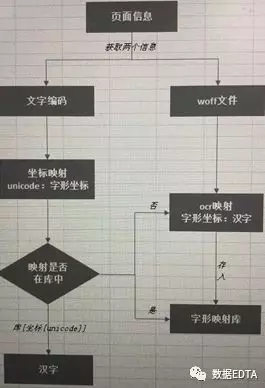
这是在excel里面画的,大家可以只关注内容,忽略掉背景线。
解释一下上面的思路:
首先:我们从页面上获取到文字编码和woff文件,注意,这里的字形编码和woff文件一定要一起获取,因为每个编码对应一个woff文件,一旦刷新页面,编码在woff文件中的对应关系就会变化,找不到对应的字形坐标。
data = etree.HTML(response.text)
title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[2]/a[1]/b/svgmtsi[1]/text()')
print(title)
其次:我们把字形编码转化成uni开头的编码,并获取到woff文件中的字形坐标。
from fontTools.ttLib import TTFont
font = TTFont('f0d5.woff')
coordinate = font['glyf']['uniF0D5'].coordinates
print(coordinate)
第三:用matplotlib解析这一坐标,并保存成图片。
#!/usr/bin/env python
# _*_ UTF-8 _*_
# 个人公众号:livandata
from fontTools.ttLib import TTFont
import matplotlib.pyplot as plt
font = TTFont('f0d5.woff')
coordinate = font['glyf']['uniF0D5'].coordinates
coordinate = list(coordinate)
fig, ax = plt.subplots()
x = [i[0] for i in coordinate]
y = [i[1] for i in coordinate]
plt.fill(x, y, color="k", alpha=1)
# 取消边框
for key, spine in ax.spines.items():
if key == 'right' or key == 'top' or key == 'bottom' or key == 'left':
spine.set_visible(False)
plt.plot(x, y)
# 取消坐标:
plt.axis('off')
plt.savefig('uniF0D5.png')
plt.show()
通过上面的解析,我们可以得到1的图片:

这个1好难看,不过好在解析出来了~
第四:使用OCR解析这个数字:
# 图片转化成string: try: from PIL import Image except ImportError: import Image import pytesseract captcha = Image.open(r'uniF0D5.png') print(captcha) result = pytesseract.image_to_string(captcha, lang='eng', config='--psm 6 --oem 3 -c tessedit_char_whitelist=0123456789').strip() print(result)
自此,我们的文字就可以直接识别出来了,我们就再也不需要用半自动的小米加步枪了,我们可以直接使用冲锋枪了

不过需要注意的是使用OCR解码文字需要一定的时间,耗时还是比较长的,如果经常使用这一思路,建议可以构建一个“字形坐标:文字”的数据库表,下次使用时解析出字形坐标,直接到数据库里匹配对应的文字就可以了。
介绍一篇OCR的文章吧,可以了解一下如何解析文字:
http://www.inimei.cn/archives/770.html
赞美时间
每一位看到这篇文章的帅哥美女都是天上的星星,而且是最亮的一颗~
看都看到这里了,加个关注再走呗~
笔者坚持数据的力量,让大数据赋能每个人~
