Titanic 生存分析
参考:
- https://github.com/apachecn/kaggle/tree/master/competitions/getting-started/titanic
- https://www.kaggle.com/goldens/classification-81-3-with-simple-model-nested-cv
1. 问题描述
-
泰坦尼克号的沉没是历史上最臭名昭著的沉船事件之一。1912年4月15日,泰坦尼克号在处女航中撞上冰山沉没,2224名乘客和船员中1502人遇难。这一耸人听闻的悲剧震惊了国际社会,并导致了更好的船舶安全条例。
-
沉船造成如此巨大人员伤亡的原因之一是没有足够的救生艇来容纳乘客和船员。虽然在沉船事件中幸存下来也有一些运气的因素,但有些人比其他人更有可能幸存下来,比如妇女、儿童和上层阶级。
-
在这个挑战中,我们要求你完成对可能存活下来的人的分析。我们特别要求你们运用机器学习工具来预测哪些乘客在灾难中幸存下来。
【注】 -
数据来源:https://www.kaggle.com/c/titanic/data
-
问题定位:二分类问题
2. 主要分析过程
- 探索性数据分析
- 特征变量选取
- 模型选择
3. 探索性数据分析
3.1 变量说明
| 变量 | 含义 | 变量 | 含义 |
|---|---|---|---|
| Survival | 生存 | Pclass | 票类别 |
| Sex | 性别 | Age | 年龄 |
| Sibsp | 兄弟姐妹/配偶的数量 | Parch | 父母/孩子的数量 |
| Ticket | 票号 | Fare | 票价 |
| Cabin | 客舱号码 | Embarked | 登船港口 |
3.2 读取数据
# 加载包
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import warnings
# 读取数据
train_data = pd.read_csv('train_titanic.csv')
test_data = pd.read_csv('test_titanic.csv')
titanic = pd.concat([train_data, test_data], sort=False)
3.3 数据预览
# 数据探索
print(train_data.info())
print('-'*30)
print(train_data.head())
输出:
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
------------------------------
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
可以看到,数据中有缺失值, 为确定数据缺失的情况,输入如下:
print(titanic.isnull().sum()[titanic.isnull().sum() > 0])
输出:
Survived 418
Age 263
Fare 1
Cabin 1014
Embarked 2
dtype: int64
由于变量 Cabin 缺失较多,这里选择不做处理,直接放弃。对变量 Fare 的缺失值取其均值作为替换,对变量 Embarked 的缺失值取其众数作为替换,对变量 Age 的缺失值按照 Name 和 Sex 的分组 去均值作为替换。
# Fare
train_data['Fare'].fillna(train_data['Fare'].mean(), inplace=True)
test_data['Fare'].fillna(test_data['Fare'].mean(), inplace=True)
# Embarked 为登陆港口,有少量的缺失值,可以先观察 Embarked 的取值情况
print(train_data['Embarked'].value_counts())
# 发现S港口的人较多,因此将缺失值都设为'S'
train_data['Embarked'].fillna('S', inplace=True)
test_data['Embarked'].fillna('S', inplace=True)
# Cabin 为船舱,有大量的缺失值,无法补齐
# Age
train_data['title'] = train_data.Name.apply(
lambda x: x.split('.')[0].split(',')[1].strip())
test_data['title'] = test_data.Name.apply(
lambda x: x.split('.')[0].split(',')[1].strip())
newtitles = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir": "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess": "Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr": "Mr",
"Mrs": "Mrs",
"Miss": "Miss",
"Master": "Master",
"Lady": "Royalty"}
train_data['title'] = train_data.title.map(newtitles)
test_data['title'] = test_data.title.map(newtitles)
train_data.groupby(['title', 'Sex']).Age.mean()
def newage(cols):
title = cols[0]
Sex = cols[1]
Age = cols[2]
if pd.isnull(Age):
if title == 'Master' and Sex == "male":
return 4.57
elif title == 'Miss' and Sex == 'female':
return 21.8
elif title == 'Mr' and Sex == 'male':
return 32.37
elif title == 'Mrs' and Sex == 'female':
return 35.72
elif title == 'Officer' and Sex == 'female':
return 49
elif title == 'Officer' and Sex == 'male':
return 46.56
elif title == 'Royalty' and Sex == 'female':
return 40.50
else:
return 42.33
else:
return Age
train_data.Age = train_data[['title', 'Sex', 'Age']].apply(newage, axis=1)
test_data.Age = test_data[['title', 'Sex', 'Age']].apply(newage, axis=1)
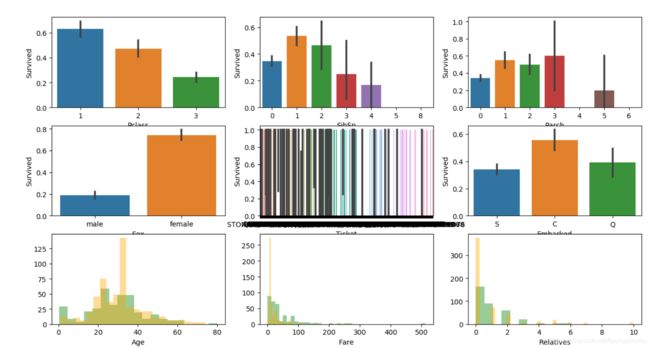
3.4 变量分析
# 变量相关分析
warnings.filterwarnings(action="ignore")
plt.figure(figsize=[10, 30])
plt.subplot(3, 3, 1)
sns.barplot('Pclass', 'Survived', data=train_data)
plt.subplot(3, 3, 2)
sns.barplot('SibSp', 'Survived', data=train_data)
plt.subplot(3, 3, 3)
sns.barplot('Parch', 'Survived', data=train_data)
plt.subplot(3, 3, 4)
sns.barplot('Sex', 'Survived', data=train_data)
plt.subplot(3, 3, 5)
sns.barplot('Ticket', 'Survived', data=train_data)
plt.subplot(3, 3, 6)
sns.barplot('Embarked', 'Survived', data=train_data)
plt.subplot(3, 3, 7)
sns.distplot(train_data[train_data.Survived == 1].Age,
color='green', kde=False)
sns.distplot(train_data[train_data.Survived == 0].Age,
color='orange', kde=False)
plt.subplot(3, 3, 8)
sns.distplot(train_data[train_data.Survived == 1].Fare,
color='green', kde=False)
sns.distplot(train_data[train_data.Survived == 0].Fare,
color='orange', kde=False)
# 由于变量 Sibsp 和变量 Parch 与 Survival 的相关性不明显,故考虑将这两个变量合并
train_data['Relatives'] = train_data.SibSp+train_data.Parch
test_data['Relatives'] = test_data.SibSp+test_data.Parch
plt.subplot(3, 3, 9)
sns.distplot(train_data[train_data.Survived ==
1].Relatives, color='green', kde=False)
sns.distplot(train_data[train_data.Survived ==
0].Relatives, color='orange', kde=False)
plt.show()
输出:
4. 特征选择
# 特征选择
features = ['Pclass', 'Sex', 'Age', 'Relatives', 'Fare', 'Embarked']
train_features = train_data[features]
train_labels = train_data['Survived']
test_features = test_data[features]
# 将分类变量转换成数值类型
dvec = DictVectorizer(sparse=False)
train_features = dvec.fit_transform(
train_features.to_dict(orient='record')) # 将特征向量转化为特征值矩阵
print(dvec.feature_names_)
test_features = dvec.transform(test_features.to_dict(orient='record'))
5. 模型选取
这里主要考虑两种方法:决策树和随机森林。
5.1 决策树
# 决策树模型
# 构造 ID3 决策树
clf = DecisionTreeClassifier(criterion='entropy')
# 决策树训练
clf.fit(train_features, train_labels)
# 用训练集的数据做评估
# 得到决策树准确率
acc_decision_tree = round(
clf.score(train_features, train_labels), 6)
print(u'score 准确率为 %.4lf' % acc_decision_tree) # %4lf为宽度为4的double型双精度
# 使用 K 折交叉验证决策树准确率
# 使用 K 折交叉验证 统计决策树准确率
print(u'cross_val_score 准确率为 %.4lf' %
np.mean(cross_val_score(clf, train_features, train_labels, cv=10)))
输出:
['Age', 'Embarked=C', 'Embarked=Q', 'Embarked=S', 'Fare', 'Pclass', 'Relatives', 'Sex=female', 'Sex=male']
score 准确率为 0.9820
cross_val_score 准确率为 0.7869
5.2 随机森林
# 随机森林
rf = RandomForestClassifier(
n_estimators=150, min_samples_leaf=2, max_depth=6, oob_score=True)
rf.fit(train_features, train_labels)
print(u'cross_val_score 准确率为 %.4lf' %
np.mean(cross_val_score(rf, train_features, train_labels, cv=10)))
输出:
cross_val_score 准确率为 0.833
经比较,随机森林的预测效果要优于决策树法。
# 预测
RF_lables = rf.predict(test_features)