SQL语句优化有哪些方法
1.如何定位慢查询?
mysql默认慢查询为10秒,如果超过10秒,没有数据返回则为慢查询.
当我们通过安全日志启动时,当超过超时时间时,会将超时的SQl存放在日志中,我们去分析这些sql然后进行调优.
2.数据库设计要合理
什么是数据库设计? 主要就是三范式
1p原子性:每列不可再分,比如姓名不可分,地址有可能会在分,山东可以分为济南或者聊城
2p保证唯一性: 比如主键
课外拓展:分布式系统如何解决并发生成订单号?
提前生成订单号,将订单号存放在redis里面,
3p不要有亢余数据:比如:学习的课程,可以单独创建一张表,每次主表存储的时候,存储课程的id就可以.
3.添加索引(普通索引,主键索引,唯一索引,全文索引)
索引:帮助快速高效查询数据的一种数据结构。
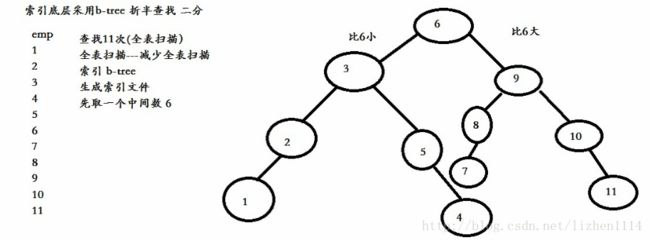
4.分表分库技术(取模分表=水平分割,垂直分割)
什么时候分库?
电商项目将一个项目进行分割,拆成多个小项目,每个小项目有自己单独的数据库,互不影响----垂直分割 会员数据库,订单数据库,支付数据库
什么时候分表?
水平分割(取模算法:如下图所示)用于均匀的分表...

分表之后有什么缺陷? 1.分页查询 2 查询受限制
解决方案:
1.提前创建一张视图,但是如果表有修改,那么相应的视图也要修改
2.现有主表,在有次表,主表存放所有的数据,次表根据业务存放在不同表内
比如我要查询性别为男的客户,那么就应该查询主表,我要查询id为2的客户就应该在次表里面查询.
3.mycar 也有分表的功能. 阿里云的RDS数据库不错,分表分库备份容灾都给你做好了
4.通过union on进行多表联合查询。
5.主从复制,读写分离
看下面两张图片,有详细讲解


6.MySQL事物的隔离级别
第1级别:Read Uncommitted(读取未提交内容)
(1)所有事务都可以看到其他未提交事务的执行结果
(2)该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据
第2级别:Read Committed(读取提交内容)
(1)一个事务只能看见已经提交事务所做的改变
(2)出现的问题是——不可重复读(Nonrepeatable Read):不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。(行级锁,不锁间隙)
第3级别:Repeatable Read(可重读)
(1)这是MySQL的默认事务隔离级别
(2)它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行,开启一个事务,读一个数据,而后再次读,这2次读的数据是一致的(行级锁且是锁间隙);
(3)可能出现的问题——幻读(Phantom Read):当用户读取数据时,另一个事务插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行
第4级别:Serializable(可串行化)
(1)这是最高的隔离级别
(2)它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
(3)在这个级别,可能导致大量的超时现象和锁竞争
脏读。假如,中午去食堂打饭吃,看到一个座位被同学小Q占上了,就认为这个座位被占去了,就转身去找其他的座位。不料,这个同学小Q起身走了。事实:该同学小Q只是临时坐了一小下,并未“提交”。
不重复读。假如,中午去食堂打饭吃,看到一个座位是空的,便屁颠屁颠的去打饭,回来后却发现这个座位却被同学小Q占去了。
幻读。假如,中午去食堂打饭吃,看到一个座位是空的,便屁颠屁颠的去打饭,回来后,发现这些座位都还是空的(重复读),窃喜。走到跟前刚准备坐下时,却惊现一个恐龙妹,严重影响食欲。仿佛之前看到的空座位是“幻影”一样。
7.查询量比较大的话,怎么办?
缓存,分页,分表.
8.SQl语句的调优
在索引使用NOT ,<>,会导致索引失效,比如a不等于0 a<>0可以修改为 a>0 or a<0 ,NOT修改为a>0或者a>"",避免全表扫描
2.尽量避免使用前导模糊查询,因为前导模糊查询由%,不能利用索引,影响查询效率.
.3.避免对查询列的操作
操作包含:数据库函数,计算机表达式,这样会导致全表扫描
4.避免不必要的类型转换
这里的类型转换是潜在的类型转换,比如将字符串与数字类型比较,这样会将字符串进行转换,导致全表扫描.
5.增加查询范围的限制
少使用*,
6.合理使用in与exists
exists是循环的方式,外表记录数代表循环的次数,外表的记录少,适合用它.
in先执行子查询,子查询去重之后,然后在执行主查询,子查询返回结果越少,越适合这种方式.
如果两张表数据一样大,那么用in和exists差别不大,但是如果不一样大,子查询小的用in,主查询小的用exists.
7.规范所有关键字的书写,select ,update,delete,要么全大写要不全小写
9.MySQL的数据库引擎有那几种?
mysisam innodb 这两个的底层采用的都是b+tree,mysisam 是使用的非聚集索引,而innodb 采用的是聚集索引。innodb支持外键事物性能低,mysisam不支持外键事物性能高这个在存储索引的方式和方法我们就可以推断出。因为innodb是存储了所有的数据,而mysisam是存储了一个地址,他响应的增删改,对于文件的变化和更换不大,但是innodb就需要很大的变化了。区别:
1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
2. InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
3. InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
4. InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
5. Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;
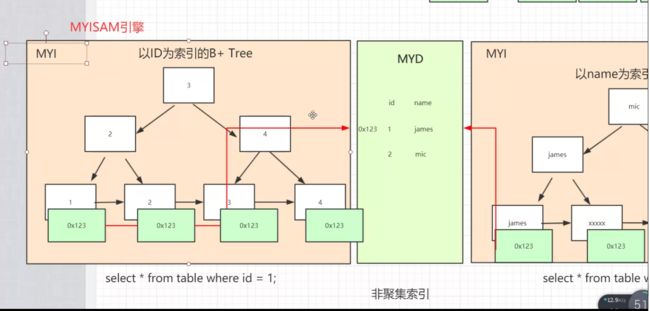
myisam中第一张图中所存储的是主键id的地址,是主键索引,而第二张图是以name为索引的存储,存储的也是主键的一个地址。0X开头说明是16进制的数字。他们根据存储的十六进制地址都能找到数据。这个就是非聚集索引。
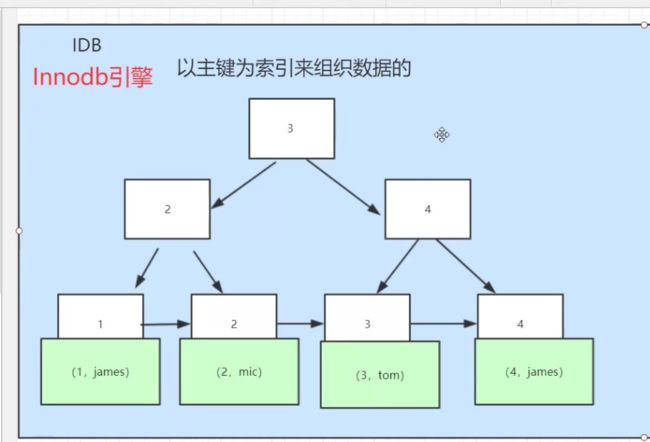
我们在看一下innodb中的索引,它存储的并不是一个地址,而是将id和name共同存储起来,此时如果我在增加一个类似于上面的图中的索引话,就是以name为索引的话,它的叶子节点存储的其实是主键,而不是主键的地址,根据主键进行查找数据。这个就是聚集索引,他的所有数据都会存放在叶子节点。
10.mysql的主键的生成方式?
1.mysql的主键自增:这个是效率最好,查询最快的方式,因为它的索引我每次的自增的时候,裂变和增加幅度都不是很大。因为他是有序的根据1,2,3,4.。。。。。这种顺序来的。
缺点:业务上,如果自增我响应的业务id就会暴露出来,别人容易根据id推断出我的业务数量
2.uuid:它有字符串,所以它的增加数据的时候,索引裂变幅度是最大的,根据字母abcd。。来进行排序和裂变的。
3.雪花算法:建议用做个,因为它的保证在同一世界空间内,保证唯一性,加了本机的机器码,同时的他生成的索引,其实是在内部维护了一个有序性,只不过转换成我们看到的时候看着是无序的而已。
11.MySQL如何防止死锁操作
所谓死锁表级锁不会产生死锁.所以解决死锁主要还是真对于最常用的InnoDB.
遇到死锁的处理方式
mysql -uxxx -pxxx -h服务器ip --port=服务器端口;(如果服务器设置了ip和端口访问的话,一定要带ip和端口)
mysql> show processlist; #查看正在执行的sql (show full processlist;查看全部sql)
mysql> kill id #杀死sql进程;
如果进程太多找不到,就重启mysql吧
/ect/init.d/mysql restart 或/ect/init.d/mysql stop(如果关不掉就直接kill -9 进程id) 再/ect/init.d/mysql start
去看看mysql日志文件是否保存死锁日志:
常用目录:/var/log/mysqld.log;(该目录还有其它相关日志文件就都看看)