java集合框架分析-HashMap(加载因子及初始容量深入分析)
《java集合框架分析-HashMap》 一文对 Java 的 HashMap 进行了简单分析,本篇继续深入了解其中涉及到的一些重要内容。
源码环境
JDK1.6
加载因子 loadfactor
/**
* 默认的初始化的容量,必须是2的幂次数
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* 默认的加载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 阈值。等于容量乘以加载因子。
* 也就是说,一旦容量到了这个数值,HashMap将会扩容。
* The next size value at which to resize (capacity * load factor).
* @serial
*/
int threshold;以下图片来自于网上,这是关于 HashMap 底层的数据结构,也就是 散列表 。
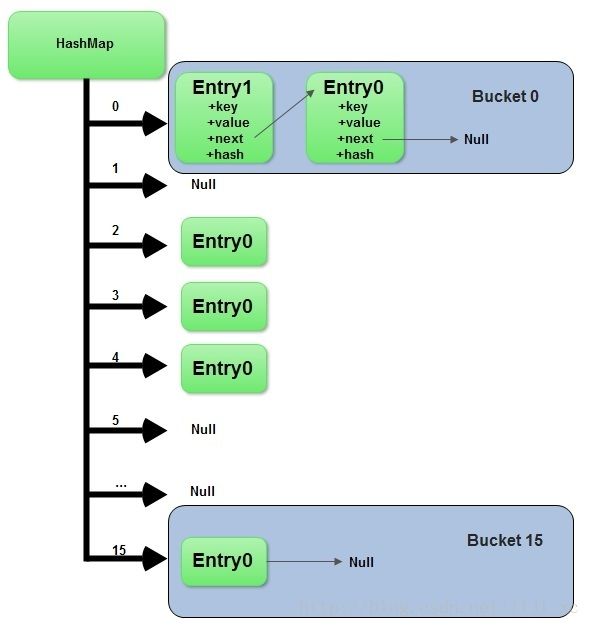
默认的容量是 16,而 threshold 是 16*0.75 = 12;
加载因子 loadfactor 是表示 Hsah 表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.
冲突的机会越大,则查找的成本越高.反之,查找的成本越小.因而,查找时间就越小.
因此,必须在 “冲突的机会”与”空间利用率”之间寻找一种平衡与折衷. 这种平衡与折衷本质上是数据结构中有名的”时-空”矛盾的平衡与折衷.
put 方法
public V put(K key, V value) {
// 省略部分代码...
// 这里增加了一个Entry
addEntry(hash, key, value, i);
return null;
}
//插入一条数据
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry(hash, key, value, e);
// 这里是关键,一旦大于等于threshold的数值
if (size++ >= threshold) {
// 将会引起容量2倍的扩大
resize(2 * table.length);
}
}
//扩容
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
// 重新计算threshold的值
threshold = (int)(newCapacity * loadFactor);
} 在 put 方法中,首先会判断容量是否够,如果一旦超过阈值的话,则就进行2倍扩容。
初始容量
初始容量 DEFAULT_INITIAL_CAPACITY 必须是2的幂次数,也就是说必须是正整数,为何要如此设计呢?
public HashMap(int initialCapacity, float loadFactor) {
// Find a power of 2 >= initialCapacity
// 重新查找不比指定数值大的最小的2的幂次数
int capacity = 1;
while (capacity < initialCapacity)
//左移一位,扩大两倍,获取最合适的初始容量值
capacity <<= 1;
// 其它的初始化代码 ...
}上面是 HashMap 进行初始化时的构造方法里面关于初始容量的内容,主要就是找到合适的初始容量。
为何是2的幂次数?这就涉及到哈希表中元素的均匀散列了。
//indexFor返回hash值和table数组长度减1的与运算结果。
public static int indexFor(int h, int length) {
return h & (length-1);
}对于查找 hash 表中的数据时需要用到以上的方法,我们一般对哈希表的散列很自然地会想到用hash值对length取模(即除法散列法),Hashtable 中也是这样实现的,这种方法基本能保证元素在哈希表中散列的比较均匀,但取模会用到除法运算,效率很低,HashMap 中则通过 h&(length-1) 的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是 HashMap 对 Hashtable 的一个改进。
接下来,我们分析下为什么哈希表的容量一定要是2的整数次幂。首先,length 为2的整数次幂的话,h&(length-1) 就相当于对 length 取模,这样便保证了散列的均匀,同时也提升了效率;其次,length 为2的整数次幂的话,为偶数,这样 length-1 为奇数,奇数的最后一位是1,这样便保证了 h&(length-1) 的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果 length 为奇数的话,很明显 length-1 为偶数,它的最后一位是0,这样 h&(length-1) 的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间,因此,length 取2的整数次幂,是为了使不同 hash 值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。