Python爬虫系列:爬取小说并写入txt文件
Python爬虫系列
——爬取小说并写入txt文件
文章介绍了如何从网站中爬取小说并写入txt文件中,实现了单章节写取,整本写取,多线程多本写取。爬虫使用的python版本为python3,有些系统使用python指令运行本脚本,可能出现错误,此时可以试一试使用python3运行本脚本。
本文是一个教程,一步步介绍了如何爬取批量小说内容以及存储这是txt文件中,以下是项目源码地址。
爬虫源码地址:https://git.oschina.net/XPSWorld/get_txt.git
| 1.使用到库文件 |
- requests:用于get请求
- threading:多线程
- bs4:网页解析
- re:正则表达式
- os:系统相关操作
- time:获取时间
以下是整个爬虫所用的库文件,如若没有对应库文件,可以使用pip获取,例如获取threading库文件:pip install threading
import requests
import threading
from bs4 import BeautifulSoup
import re
import os
import time- 1
- 2
- 3
- 4
- 5
- 6
| 2.对网页文件结构进行分析(PS:浏览器使用的是谷歌浏览器) |
通过对 http://www.qu.la/ 的文件结构进行分析,知道了每一本小说的目录地址为该地址加上book/,再加上对应的小说编号,如编号为1的小说地址为http://www.qu.la/book/1/,在浏览器打开该网址,就可以看到如下类似的界面 
以此类推就可以知道每一本的小说地址。
| 3.获取网页的请求头文件 |
我们以编号为1的小说地址为例(http://www.qu.la/book/1/),打开谷歌的开发者工具,选择Network,会出现如下界面,如果没有对应的列表信息,刷新一下网页即可。 
然后点击1/,出现以下信息: 
我们需要的是第二个方框中的内容(Request Headers),将该目录下的信息取出,存放到字典中,其中每一个项所代表的意义如果感兴趣可自行网上搜索(HTTP Header 详解)。
#请求头字典
req_header={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cookie':'__cfduid=d577ccecf4016421b5e2375c5b446d74c1499765327; UM_distinctid=15d30fac6beb80-0bdcc291c89c17-9383666-13c680-15d30fac6bfa28; CNZZDATA1261736110=1277741675-1499763139-null%7C1499763139; tanwanhf_9821=1; Hm_lvt_5ee23c2731c7127c7ad800272fdd85ba=1499612614,1499672399,1499761334,1499765328; Hm_lpvt_5ee23c2731c7127c7ad800272fdd85ba=1499765328; tanwanpf_9817=1; bdshare_firstime=1499765328088',
'Host':'www.qu.la',
'Proxy-Connection':'keep-alive',
'Referer':'http://www.qu.la/book/1265/765108.html',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36'
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
| 4.分析每章小说网页结构 |
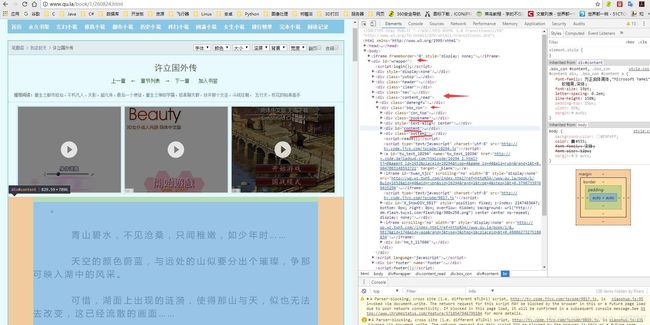
每一本小说多有对应的章节网页,也就说每一张都有对应的网页,我们以编号为1的小说中任意章节为例,其地址信息为http://www.qu.la/book/1/260824.html,其中“260824.html”就是该章节的网页名称,点击开发者工具中的 Element 选项,以下是对应的截图信息,通过分析,小说章节信息的路径为:#wrapper .content_read .box_con (PS:其中“#wrapper”号表示id为wrapper的项,“.content_read”表示class为content_read的项,按照此顺序放在一起就表示id为wrapper的项中的class为content_read的项中的class为con_box的相关信息,三者为树形关系。)
在该路径下,我们需要的信息主要有三项,以下是对应的class内容以及对应的说明:
- bookname:可获取章节名称
- content:可获取章节内容
- bottom2:可获取下一章节地址
| 5.获取单独一章内容 |
对于BeautifulSoup不是特别了解的,可以先阅读以下几篇文章:
- Beautiful Soup 的用法
- Beautiful Soup 4.2.0 文档
- Beautiful Soup 中文文档
以下是获取单章章节内容的部分代码,需将文章上所述的库文件以及请求头文件粘贴方可运行以下代码(PS【重要】:python想要使用汉字,需要在脚本最前面添加 #coding:utf-8,汉字使用的编码为utf-8,否则会出现错误):
req_url_base='http://www.qu.la/book/' #小说主地址
req_url=req_url_base+"1/" #单独一本小说地址
txt_section='260824.html' #某一章页面地址
#请求当前章节页面 params为请求参数
r=requests.get(req_url+str(txt_section),params=req_header)
#soup转换
soup=BeautifulSoup(r.text,"html.parser")
#获取章节名称
section_name=soup.select('#wrapper .content_read .box_con .bookname h1')[0]
#获取章节文本
section_text=soup.select('#wrapper .content_read .box_con #content')[0].text
for ss in section_text.select("script"): #删除无用项
ss.decompose()
#按照指定格式替换章节内容,运用正则表达式
section_text=re.sub( '\s+', '\r\n\t', section_text.text).strip('\r\n')
print('章节名:'+section_name)
print("章节内容:\n"+section_text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行效果截图: 
| 6.将获取的文本信息写入txt文件中 |
在实际操作之前,如果大家对于文件操作以及编码转换不是很了解的,可以先看看以下两篇文章:
- python encode和decode函数说明
- Python 文件I/O
以下是相关源码以及注释(PS:在原有代码的基础上添加即可):
fo = open('1.txt', "ab+") #打开小说文件
# 以二进制写入章节题目 需要转换为utf-8编码,否则会出现乱码
fo.write(('\r' + section_name + '\r\n').encode('UTF-8'))
# 以二进制写入章节内容
fo.write((section_text).encode('UTF-8'))
fo.close() #关闭小说文件- 1
- 2
- 3
- 4
- 5
- 6
| 7.获取整本小说 |
通过前面几个步骤,我们知道了如何获取单章小说相关信息写入txt中,接下来获取整本小说内容就是在其基础上进行改进的,我们将通过一个函数来实现获取整本内容,以下是函数代码:
#小说下载函数
#id:小说编号
#txt字典项介绍
# title:小说题目
# first_page:第一章页面
# txt_section:章节地址
# section_name:章节名称
# section_text:章节正文
# section_ct:章节页数
def get_txt(txt_id):
txt={}
txt['title']=''
txt['id']=str(txt_id)
try:
print("请输入需要下载的小说编号:")
txt['id']=input()
req_url=req_url_base+ txt['id']+'/' #根据小说编号获取小说URL
print("小说编号:"+txt['id'])
res=requests.get(req_url,params=req_header) #获取小说目录界面
soups=BeautifulSoup(res.text,"html.parser") #soup转化
#获取小说题目
txt['title']=soups.select('#wrapper .box_con #maininfo #info h1')[0].text
txt['author']=soups.select('#wrapper .box_con #maininfo #info p')
#获取小说最近更新时间
txt['update']=txt['author'][2].text
#获取最近更新章节名称
txt['lately'] = txt['author'][3].text
#获取小说作者
txt['author']=txt['author'][0].text
#获取小说简介
txt['intro']=soups.select('#wrapper .box_con #maininfo #intro')[0].text.strip()
print("编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 开始下载。")
print("正在寻找第一章页面。。。")
#获取小说所有章节信息
first_page=soups.select('#wrapper .box_con #list dl dd a')
#获取小说总章页面数
section_ct=len(first_page)
#获取小说第一章页面地址
first_page = first_page[0]['href'].split('/')[3]
print("小说章节页数:"+str(section_ct))
print("第一章地址寻找成功:"+ first_page)
#设置现在下载小说章节页面
txt_section=first_page
#打开小说文件写入小说相关信息
fo = open('{0:0>8}-{1}.txt.download'.format(txt['id'],txt['title']), "ab+")
fo.write((txt['title']+"\r\n").encode('UTF-8'))
fo.write((txt['author'] + "\r\n").encode('UTF-8'))
fo.write((txt['update'] + "\r\n").encode('UTF-8'))
fo.write((txt['lately'] + "\r\n").encode('UTF-8'))
fo.write(("*******简介*******\r\n").encode('UTF-8'))
fo.write(("\t"+txt['intro'] + "\r\n").encode('UTF-8'))
fo.write(("******************\r\n").encode('UTF-8'))
#进入循环,写入每章内容
while(1):
try:
#请求当前章节页面
r=requests.get(req_url+str(txt_section),params=req_header)
#soup转换
soup=BeautifulSoup(r.text,"html.parser")
#获取章节名称
section_name=soup.select('#wrapper .content_read .box_con .bookname h1')[0]
section_text=soup.select('#wrapper .content_read .box_con #content')[0]
for ss in section_text.select("script"): #删除无用项
ss.decompose()
#获取章节文本
section_text=re.sub( '\s+', '\r\n\t', section_text.text).strip('\r\n')#
#获取下一章地址
txt_section=soup.select('#wrapper .content_read .box_con .bottem2 #A3')[0]['href']
#判断是否最后一章,当为最后一章时,会跳转至目录地址,最后一章则跳出循环
if(txt_section=='./'):
print("编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 下载完成")
break
#以二进制写入章节题目
fo.write(('\r'+section_name.text+'\r\n').encode('UTF-8'))
#以二进制写入章节内容
fo.write((section_text).encode('UTF-8'))
print(txt['title']+' 章节:'+section_name.text+' 已下载')
#print(section_text.text.encode('UTF-8'))
except:
print("编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 章节下载失败,正在重新下载。")
fo.close()
os.rename('{0:0>8}-{1}.txt.download'.format(txt['id'],txt['title']), '{0:0>8}-{1}.txt'.format(txt['id'],txt['title']))
except: #出现错误会将错误信息写入dowload.log文件,同时答应出来
fo_err = open('dowload.log', "ab+")
try:
fo_err.write(('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:" + '{0:0>8} '.format(txt['id']) + "小说名:《" + txt['title'] + "》 下载失败。\r\n").encode('UTF-8'))
print('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 下载失败。")
os.rename('{0:0>8}'.format(txt['id']) + '-' + txt['title'] + '.txt.download',
'{0:0>8}'.format(txt['id']) + '-' + txt['title'] + '.txt.error')
except:
fo_err.write(('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:"+'{0:0>8} '.format(txt['id'])+"下载失败。\r\n").encode('UTF-8'))
print('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:"+'{0:0>8} '.format(txt['id'])+"下载失败。")
finally: #关闭文件
fo_err.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
如果有需要爬取的相关小说,只需要在该网站找到小说编号,然后调用该函数就可以将小说下载至本电脑,如需下载编号为6666的小说,则调用get_txt(6666)即可,在下载过程中,文件后缀为“.txt.download”,下载完成后会将文件后缀变为“.txt”。
运行效果 
| 8.多线程爬取多本小说 |
同样的,在此之前如果对于python线程不了解的可以阅读以下文章:
- Python 多线程
关于多线程的代码就不过多介绍了,在项目源码中会有相关的使用方法。(PS:通过实验,每次同步下载100本小说最好,太多的话进程可能会被杀死)
| 9.最终效果 |
最终的源码实现如下效果:
- 每次同步爬取100本小说
- 会生成一个关于小说的介绍文档,文档介绍了每次爬取的100本小说
- 显示对应进度信息
- 小说还未下载完文件后缀为“.txt.download”,下载完成后会将文件后缀变为“.txt”
以下是运行效果图: 

在运行结果图中,标号为1的部分是已经爬取完成的小说;编号为2的为还在下载的小说;编号为3的文件是下载错误日志,当不存在相关编号小说,则会记录在该文件中,下图为文件内容;编号为4的为每100本小说的简介,在我们通过该脚本,就可以知道所爬取的小说有哪些,通过然后通过编号就可以找到对应小说,下图同样展示其相关内容。
download.log文件内容: 
小说简介文件内容: 
| 10.其他(教程源码) |
鉴于有朋友说提供的项目源码(多线程多本)与教程(单线程单本)不符,所将以上教程中单本小说下载的源码贴上,大家可以直接复制运行。
#coding:utf-8
import requests
import threading
from bs4 import BeautifulSoup
import re
import os
import time
import sys
req_header={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cookie':'__cfduid=d577ccecf4016421b5e2375c5b446d74c1499765327; UM_distinctid=15d30fac6beb80-0bdcc291c89c17-9383666-13c680-15d30fac6bfa28; CNZZDATA1261736110=1277741675-1499763139-null%7C1499763139; tanwanhf_9821=1; Hm_lvt_5ee23c2731c7127c7ad800272fdd85ba=1499612614,1499672399,1499761334,1499765328; Hm_lpvt_5ee23c2731c7127c7ad800272fdd85ba=1499765328; tanwanpf_9817=1; bdshare_firstime=1499765328088',
'Host':'www.qu.la',
'Proxy-Connection':'keep-alive',
'Referer':'http://www.qu.la/book/',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36'
}
req_url_base='http://www.qu.la/book/' #小说主地址
#小说下载函数
#txt_id:小说编号
#txt字典项介绍
#id:小说编号
# title:小说题目
# first_page:第一章页面
# txt_section:章节地址
# section_name:章节名称
# section_text:章节正文
# section_ct:章节页数
def get_txt(txt_id):
txt={}
txt['title']=''
txt['id']=str(txt_id)
try:
#print("请输入需要下载的小说编号:")
#txt['id']=input()
req_url=req_url_base+ txt['id']+'/' #根据小说编号获取小说URL
print("小说编号:"+txt['id'])
res=requests.get(req_url,params=req_header) #获取小说目录界面
soups=BeautifulSoup(res.text,"html.parser") #soup转化
#获取小说题目
txt['title']=soups.select('#wrapper .box_con #maininfo #info h1')[0].text
txt['author']=soups.select('#wrapper .box_con #maininfo #info p')
#获取小说最近更新时间
txt['update']=txt['author'][2].text
#获取最近更新章节名称
txt['lately'] = txt['author'][3].text
#获取小说作者
txt['author']=txt['author'][0].text
#获取小说简介
txt['intro']=soups.select('#wrapper .box_con #maininfo #intro')[0].text.strip()
print("编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 开始下载。")
print("正在寻找第一章页面。。。")
#获取小说所有章节信息
first_page=soups.select('#wrapper .box_con #list dl dd a')
#获取小说总章页面数
section_ct=len(first_page)
#获取小说第一章页面地址
first_page = first_page[0]['href'].split('/')[3]
print("小说章节页数:"+str(section_ct))
print("第一章地址寻找成功:"+ first_page)
#设置现在下载小说章节页面
txt_section=first_page
#打开小说文件写入小说相关信息
fo = open('{0:0>8}-{1}.txt.download'.format(txt['id'],txt['title']), "ab+")
fo.write((txt['title']+"\r\n").encode('UTF-8'))
fo.write((txt['author'] + "\r\n").encode('UTF-8'))
fo.write((txt['update'] + "\r\n").encode('UTF-8'))
fo.write((txt['lately'] + "\r\n").encode('UTF-8'))
fo.write(("*******简介*******\r\n").encode('UTF-8'))
fo.write(("\t"+txt['intro'] + "\r\n").encode('UTF-8'))
fo.write(("******************\r\n").encode('UTF-8'))
#进入循环,写入每章内容
while(1):
try:
#请求当前章节页面
r=requests.get(req_url+str(txt_section),params=req_header)
#soup转换
soup=BeautifulSoup(r.text,"html.parser")
#获取章节名称
section_name=soup.select('#wrapper .content_read .box_con .bookname h1')[0]
section_text=soup.select('#wrapper .content_read .box_con #content')[0]
for ss in section_text.select("script"): #删除无用项
ss.decompose()
#获取章节文本
section_text=re.sub( '\s+', '\r\n\t', section_text.text).strip('\r\n')#
#获取下一章地址
txt_section=soup.select('#wrapper .content_read .box_con .bottem2 #A3')[0]['href']
#判断是否最后一章,当为最后一章时,会跳转至目录地址,最后一章则跳出循环
if(txt_section=='./'):
print("编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 下载完成")
break
#以二进制写入章节题目
fo.write(('\r'+section_name.text+'\r\n').encode('UTF-8'))
#以二进制写入章节内容
fo.write((section_text).encode('UTF-8'))
print(txt['title']+' 章节:'+section_name.text+' 已下载')
#print(section_text.text.encode('UTF-8'))
except:
print("编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 章节下载失败,正在重新下载。")
fo.close()
os.rename('{0:0>8}-{1}.txt.download'.format(txt['id'],txt['title']), '{0:0>8}-{1}.txt'.format(txt['id'],txt['title']))
except: #出现错误会将错误信息写入dowload.log文件,同时答应出来
fo_err = open('dowload.log', "ab+")
try:
fo_err.write(('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:" + '{0:0>8} '.format(txt['id']) + "小说名:《" + txt['title'] + "》 下载失败。\r\n").encode('UTF-8'))
print('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:"+'{0:0>8} '.format(txt['id'])+ "小说名:《"+txt['title']+"》 下载失败。")
os.rename('{0:0>8}'.format(txt['id']) + '-' + txt['title'] + '.txt.download',
'{0:0>8}'.format(txt['id']) + '-' + txt['title'] + '.txt.error')
except:
fo_err.write(('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:"+'{0:0>8} '.format(txt['id'])+"下载失败。\r\n").encode('UTF-8'))
print('['+time.strftime('%Y-%m-%d %X', time.localtime())+"]:编号:"+'{0:0>8} '.format(txt['id'])+"下载失败。")
finally: #关闭文件
fo_err.close()
#此处为需要下载小说的编号,编号获取方法在上文中已经讲过。
get_txt(1150)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
文章有那块不对的地方,希望大家帮忙指正改进。