记一次OOM排查过程(入门版)
第一次线上遇到问题,最近也在学jvm,记录一下,算是一个入门版jvm故障排查,希望能给新手带来一点干货。
背景
机器 (2c8g) 默认jvm部分关键参数配置:
- Xmx 最大堆内存
- Xms 最小堆内存
- UseG1GC 使用G1垃圾回收器
- PrintGCDetails/PrintGC 打印GC详细日志
- HeapDumpOnOutOfMemoryError 这个是故障排查关键,会在OOM的时候生成一个堆快照做参考
- -Xloggc 日志GC文件地址
- HeapDumpPath:堆快照存放地址
-Xmx1024m -Xms1024m -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGC() -XX:+HeapDumpOnOutOfMemoryError -Xloggc:/opt/logs/10494/gc-1559715804.log -XX:HeapDumpPath=/opt/logs/10494
发现问题
系统上线一个功能,是对日志 进行手机号脱敏,代码大致流程是每处理完一个手机号,递归调用自己,重新从第一个字符开始判断。从描述和下图大概可以看出端倪,这样遇到带有很多手机号的日志会因为递归造成严重的性能问题。

public static String desensitizationMobile(String json) {
if (StringUtils.isEmpty(json) || json.length() < 12) {
return json;
}
int length = json.length();
int j = 0;
for (; j < length - 10; ) {
char[] validate = new char[11];
char c = json.charAt(j);
//如果以1开头,往后判断11位
if (c == 49) {
validate[0] = c;
for (int i = 1; i < 11; i++) {
char charAt = json.charAt(j + i);
if (isNumber(charAt)) {
validate[i] = charAt;
} else {
j += i;
break;
}
}
if (validate[10] != 0 && leftAndRightNotCharacter(json, j)) {
String mobile = new String(validate);
Matcher matcher = phonePattern.matcher(mobile);
if (matcher.matches()) {
String replace = json.replace(mobile, mobileEncrypt(mobile));
return desensitizationMobile(replace);
}
}
}
j++;
}
return json;
}
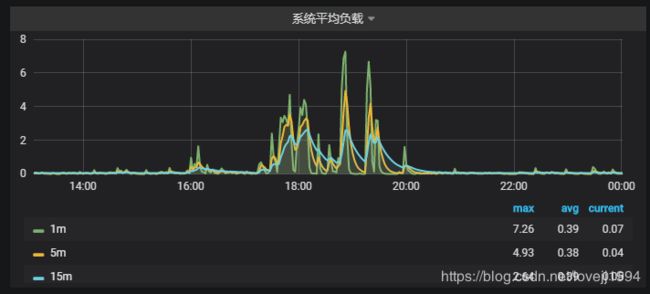
上线之后,可以看到18点左右 系统负载开始上升,CPU曲线高居不下。

分析问题
分析gc日志
对于G1日志的查看,可以看这篇文章 浅谈 G1 GC 日志格式
这是我根据GC日志截取 Full GC 部分,可以看到,Full GC已经达到了几乎一秒执行一次,并且发生的原因都是Allocation Failure,这是不正常的情况,再加上每次耗时(real)0.6 secs左右,cpu高居不下,服务卡顿就可以解释了。
2019-06-03T17:40:16.564+0800: 1337.747: [Full GC (Allocation Failure) 872M->639M(1024M), 0.6469558 secs]
[Eden: 0.0B(50.0M)->0.0B(249.0M) Survivors: 1024.0K->0.0B Heap: 873.0M(1024.0M)->639.7M(1024.0M)], [Metaspace: 137645K->137641K(1173504K)]
[Times: user=0.83 sys=0.00, real=0.65 secs]
2019-06-03T17:40:18.202+0800: 1339.385: [Full GC (Allocation Failure) 863M->617M(1024M), 0.6544072 secs]
[Eden: 0.0B(50.0M)->0.0B(274.0M) Survivors: 1024.0K->0.0B Heap: 863.1M(1024.0M)->617.6M(1024.0M)], [Metaspace: 137646K->137646K(1173504K)]
[Times: user=0.83 sys=0.00, real=0.66 secs]
2019-06-03T17:40:20.010+0800: 1341.194: [Full GC (Allocation Failure) 837M->613M(1024M), 0.6534616 secs]
[Eden: 0.0B(50.0M)->0.0B(281.0M) Survivors: 1024.0K->0.0B Heap: 837.9M(1024.0M)->613.4M(1024.0M)], [Metaspace: 137651K->137648K(1173504K)]
[Times: user=0.83 sys=0.00, real=0.65 secs]
2019-06-03T17:40:21.179+0800: 1342.363: [Full GC (Allocation Failure) 821M->627M(1024M), 0.6571097 secs]
[Eden: 0.0B(67.0M)->0.0B(268.0M) Survivors: 1024.0K->0.0B Heap: 821.3M(1024.0M)->627.4M(1024.0M)], [Metaspace: 137655K->137652K(1173504K)]
[Times: user=0.84 sys=0.00, real=0.66 secs]
2019-06-03T17:40:22.396+0800: 1343.580: [Full GC (Allocation Failure) 847M->612M(1024M), 0.6436667 secs]
[Eden: 0.0B(50.0M)->0.0B(283.0M) Survivors: 1024.0K->0.0B Heap: 847.8M(1024.0M)->612.5M(1024.0M)], [Metaspace: 137656K->137656K(1173504K)]
[Times: user=0.84 sys=0.00, real=0.64 secs]
jstat 分析gc情况
上面是硬核看日志的方式来分析gc情况,看日志的缺点就是不够直观,我们现在换个工具达到一样的效果,因为故障当时没有去用,我用jstat是模拟数据。
先用jps找到java进程号
jps -v -l

然后用jstat命令,31500就是你要监控的java进程号,1000表示1000ms打印一次。
jstat -gcutil 31500 1000
英文来自官方文档,都是程序员,应该看得懂意思,而 FGC 则表示了full GC的次数,基于数据的变化,我们就能方便监控full gc是否正常。
- S0: Survivor space 0 utilization as a percentage of the space’s current capacity.
- S1: Survivor space 1 utilization as a percentage of the space’s current capacity.
- E: Eden space utilization as a percentage of the space’s current capacity.
- O: Old space utilization as a percentage of the space’s current capacity.
- M: Metaspace utilization as a percentage of the space’s current capacity.
- CCS: Compressed class space utilization as a percentage.
- YGC: Number of young generation GC events.
- YGCT: Young generation garbage collection time.
- FGC: Number of full GC events.
- FGCT: Full garbage collection time.
- GCT: Total garbage collection time.

jhat 找出元凶
知道 full gc频繁导致负载较高,但是 是什么原因导致的还没有查清楚。在之前jvm参数里有一个HeapDumpOnOutOfMemoryError,当OOM发生时会自动生成一个堆快照文件,我们可以通过jhat来分析问题。
jhat java_pid22270.hprof
jhat会启动一个网页服务,默认端口7000,通过服务我们可以看到 出问题时 堆内部的对象情况

直接进下面链接,展示的是堆中对象的个数及大小,而且从大到小已经排好序。
localhost:7000/histo/
排好名后 class [C 高居第一,并且个数和大小与其它的差距很大,[C是字节码,翻译过来就是char[]
- [C is a char[]
- [S is a short[]
- [I is a int[]
- [B is a byte[]
- [I is a int[][]

在我们的脱敏代码中,因为递归的方式,创建了很多char数组,当我们找到罪魁祸首之后,我们需要优化代码(去掉递归的方式),重新上线。
调整jvm参数
之前我们的默认参数 堆内存被固定成1g,这对于8g内存的机器是不合理的,所以我们也要调整下jvm参数
-Xms4096m -Xmx4096m
结束
改好代码上线之后,故障就消除了,这是一个很简单的入门排查,最近也在看《深入理解Java虚拟机》,很好的书,推荐给大家。