深度学习-迁移学习
今天简单看了迁移学习,感觉还是挺牛逼的。可以在短时间内将在其它数据集中已经训练好的模型快速转移到另一个数据集上。当然,如果你的数据集比较庞大,还是自己训练好的。
例如,将在ImageNet上训练好的Inception-V3模型转移到另外一个图像分类数据集上,并取得较高的准确率。
在了解迁移学习前,需要了解什么是瓶颈层。它是从神经网络的输入开始算起,一直到神经网络的最后一层的前向传播称为瓶颈层,这里最后一层指的不是softmax层。最后一层为已经将输入数据经过网络结构完成好了分类。瓶颈层可以理解为对输入数据的特征提取过程。
例如,我们有一个10分类的训练集,网络结构为5层。卷积层—最大池化层—-全连接层—-输出层—-softmax层.瓶颈层为从卷积层到全连接层。假如输入数据传输到最大池化层输出的shape=[batch_size,10,10,64],这将作为全连接层的输入,在输入全连接层时,需要将shape更为为1-D。因此全连接层的输入shape=[batch_size,10*10*64],而全连接层的输出为shape=[batch_size,128],最后输出层的输出为shape=[batch_size,10],获得输入数据的分类,最后在经过softmax层完成最后的输出。
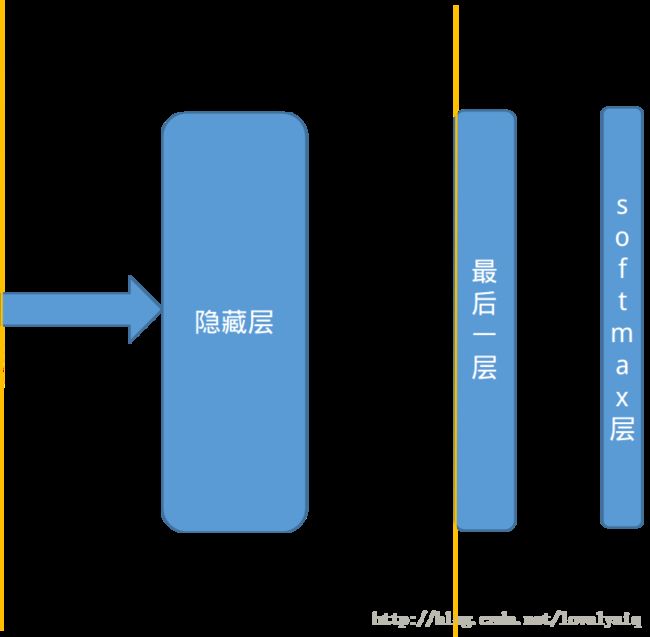
接下来,要迁移已经训练好的模型到一个新的数据中,而新数量的类别为n_class = 5。因此,最后一层权重的shape变为[10*10*64,n_class],因此在设计结构时始终记住输入数据经过瓶颈层是抽取特征的过程。
设计流程:
1、加载已经训练好的模型。
2、加载瓶颈层和输入节点的名称,用于恢复对应变量的计算方法。
3、获取瓶颈层的输出特征。
4、瓶颈层的输出特征作为最后一层的输入,最后一层权重的shape=[10*10*64,n_class],设计最后一层的网络结构。
5、计算softmax层,损失函数等。
下面的例子,通过在ImageNet训练好的inception V3模型迁移到另外一个训练集中,最后可以实现经过一个短时间的训练,就可以达到一个比较高的准确率,准确率大概在94%左右。
所使用的数据为:Inception V3模型集训练集链接为:
http://download.tensorflow.org/example_images/flower_photos.tgz
http://download.csdn.net/download/lovelyaiq/10138957
import glob
import os
import numpy as np
import random
import tensorflow as tf
from tensorflow.python.platform import gfile
import cv2
# inception-v3模型瓶颈层的节点个数
BOTTLENECT_TENSOR_SIZE = 2048
# 瓶颈层中结果的张量名称,在训练时,可以通过tensor.name获取
BOTTLENECT_TENSOR_NAME = 'pool_3/_reshape:0'
# 图像输入张量对应的名称
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
# 模型所在的路径
MODEL_DIR = './'
# 谷歌训练好的inception-v3模型
MODEL_FILE_NAME = './inception_dec_2015/tensorflow_inception_graph.pb'
# 保存图像经过inception-v3模型计算后得到的特征向量。
CACHE_DIR = 'temp/'
# 输入图片对应的路径
INPUT_DATA = 'flower_photos'
VALIDATAION_PERCENTAGE = 10
TEST_PERCENTAGE = 10
LEANRNING_RAGE = 0.01
STEPS = 40000
BATCH = 200
# 从数据集中读取图片,并分为训练集、测试集、验证集。
def create_image_list(test_percentage,val_percentage):
result = {}
# 获取当前目录下的所有子目录
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
is_root_dir = True
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
extensions = ['jpg','jpeg','JPG','JPEG']
file_list = []
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA,dir_name,'*.' + extension)
file_list.extend(glob.glob(file_glob))
if not file_list:
continue
# 通过目录名称获取类别的名称
label_name = dir_name.lower()
test_image = []
val_image = []
train_image = []
for file_name in file_list:
base_name = os.path.basename(file_name)
chance = np.random.randint(100)
if chance < val_percentage:
val_image.append(base_name)
elif chance < (test_percentage + val_percentage):
test_image.append(base_name)
else:
train_image.append(base_name)
# 将当前的类别放入字典中
result[label_name] = {
'dir':dir_name,
'training':train_image,
'testing':test_image,
'valing':val_image,
}
return result
# image_lists:所有图片的信息
# image_dir:根目录,存放图片数据的根目录
# label_name:类别的名称
# index :需要获取的图片的编号
# category:需要获取的图片属于那个激活【测试集、训练集、验证集】
def get_image_path(image_lists,image_dir,label_name,index,category):
lable_lists= image_lists[label_name]
category_list = lable_lists[category]
mod_index = index % len(category_list)
base_name = category_list[mod_index]
sub_dir = lable_lists['dir']
full_path = os.path.join(image_dir,sub_dir,base_name)
return full_path
def get_bottleneck_path(image_lists,label_name,index,category):
return get_image_path(image_lists,CACHE_DIR,label_name,index,category) + '.txt'
def run_bottlenect_on_image(sess,image_data,image_data_tensro,bottlenect_tensor):
bottlenect_values = sess.run(bottlenect_tensor,{image_data_tensro:image_data})
bottlenect_values = np.squeeze(bottlenect_values)
return bottlenect_values
def get_or_create_bottleneck(sess,image_lists,label_name,index,category,jpeg_data_tensor,bottleneck_tensor):
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(CACHE_DIR,sub_dir)
if not os.path.exists(sub_dir_path):
os.makedirs(sub_dir_path)
bottleneck_path = get_bottleneck_path(image_lists,label_name,index,category)
if not os.path.exists(bottleneck_path):
image_path = get_image_path(image_lists,INPUT_DATA,label_name,index,category)
image_data = gfile.FastGFile(image_path,'rb').read()
bottlenect_values = run_bottlenect_on_image(sess,image_data,jpeg_data_tensor,bottleneck_tensor)
bottleneck_string = ','.join(str(x) for x in bottlenect_values)
with open(bottleneck_path,'w') as f:
f.write(bottleneck_string)
else:
with open(bottleneck_path,'r') as f:
bottleneck_string = f.read()
bottlenect_values = [float(x) for x in bottleneck_string.split(',')]
return bottlenect_values
def get_random_cached_bottlenecks(sess,n_classes,image_lists,how_many,category,jpeg_data_tensor,bottleneck_tensor):
bottlenecks = []
ground_truths = []
for _ in range(how_many):
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(65536)
bottleneck = get_or_create_bottleneck(sess,image_lists,label_name,image_index,
category,jpeg_data_tensor,bottleneck_tensor)
ground_truth = np.zeros(n_classes,np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks,ground_truths
def get_test_bottlenecks(sess,image_lists,n_classes,jpeg_data_tensor,bottleneck_tensor):
bottlenecks = []
groud_truths = []
# print(image_lists.keys())
label_name_list = image_lists.keys()
for label_index,label_name in enumerate(label_name_list):
category = 'testing'
for index,unused_base_name in enumerate(image_lists[label_name][category]):
bottleneck = get_or_create_bottleneck(sess,image_lists,label_name,index,category,
jpeg_data_tensor,bottleneck_tensor)
groud_truth = np.zeros(n_classes,np.float32)
groud_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
groud_truths.append(groud_truth)
return bottlenecks,groud_truths
def main(_):
image_lists = create_image_list(TEST_PERCENTAGE,VALIDATAION_PERCENTAGE)
n_classes = len(image_lists.keys())
with gfile.FastGFile(os.path.join(MODEL_DIR,MODEL_FILE_NAME),'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
bottlenect_tensro,jpep_data_tensor = tf.import_graph_def(graph_def,return_elements=
[BOTTLENECT_TENSOR_NAME,JPEG_DATA_TENSOR_NAME])
# 定义新的神经网络深入,这个输入就是图片进过inception-v3模型前向传播到达瓶颈层时的节点取值。
bottleneck_input = tf.placeholder(tf.float32,[None,BOTTLENECT_TENSOR_SIZE])
# 定义新的标准答案输入。
ground_truth_input = tf.placeholder(tf.float32,shape=[None,n_classes],name='GroundTruthInput')
with tf.name_scope('final_train_ops'):
w = tf.Variable(tf.truncated_normal(shape=[BOTTLENECT_TENSOR_SIZE,n_classes],stddev=0.1))
b = tf.Variable(tf.zeros([n_classes]))
logits = tf.matmul(bottleneck_input,w) + b
final_tensor = tf.nn.softmax(logits)
cross_entroy = tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=ground_truth_input)
cross_entroy_mean = tf.reduce_mean(cross_entroy)
train_step = tf.train.GradientDescentOptimizer(LEANRNING_RAGE).minimize(cross_entroy_mean)
with tf.name_scope('evaluation'):
correct_prediction = tf.equal(tf.argmax(final_tensor,1),tf.argmax(ground_truth_input,1))
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(STEPS):
# print(i)
train_bottlenecks,train_ground_truth = get_random_cached_bottlenecks(sess,
n_classes,image_lists,BATCH,'training',jpep_data_tensor,bottlenect_tensro)
sess.run(train_step,feed_dict={bottleneck_input:train_bottlenecks,\
ground_truth_input:train_ground_truth})
if i % 100 ==0 or i + 1 ==STEPS:
val_bottlenecks,val_ground_truth = get_random_cached_bottlenecks(sess,n_classes,
image_lists,BATCH,'valing',jpep_data_tensor,bottlenect_tensro)
val_accuracy = sess.run(evaluation_step,feed_dict={bottleneck_input:val_bottlenecks,
ground_truth_input:val_ground_truth})
print('Step is %d, val accuracy on random sampled is %d examples %.1f%%' %(i,BATCH,val_accuracy*100))
test_bottlenecks, test_ground_truth = get_test_bottlenecks(sess,image_lists,n_classes,
jpep_data_tensor,bottlenect_tensro)
test_accuracy = sess.run(evaluation_step,feed_dict={bottleneck_input:test_bottlenecks,
ground_truth_input:test_ground_truth})
print('Final test accuracy = %.1f%%'%(test_accuracy*100))
if __name__ == '__main__':
tf.app.run()