(Tensorflow Object Detection Api)ssd-mobilenet v1 算法结构及代码介绍
(Tensorflow Object detection Api)安装
(Tensorflow Object Detection Api)标注数据获取及格式转换
(Tensorflow Object Detection Api)模型训练
通过前面三次分享,基本把Object Detection Api的入门使用方式就都陈列了出来。接下来计划分享一下算法的具体结构和代码的部分,以及相关的参数调试方法。毕竟,真正拿来用的话,根据场景的不同,需要不同的性能和侧重点。如下,仅对ssd-mobilenet-v1进行分享。
ssd原文 MobileNet V1论文
两个月前刚开始搞物体检测的项目的时候,我的想法是比较naive的,由于我要检测的物体只有一类,我尝试自己按照VGG-16的想法设计了简单版的网络的结构,然后直接预测左上角和右下角坐标。之所以这么想,是因为觉得深度学习那么强大,这么简单的功能应该很好实现想要的效果。可是,事与愿违,直接预测坐标的想法在真正实践的时候,准确率我都不好意思说出来。
在之后研读各种物体检测算法的过程中,发现其实神经网络并没有强大到傻瓜式操作的境界,它还是需要精心的喂养,并且需要尽量多的提供给它各种维度的信息,更加要考虑如何为它减负,而不是刁难它。
提供的信息越多,神经网络的表现自然更好,比如在Reid中,有些人就尝试在将原有数据集中的人的其他属性,诸如衣服颜色,性别,年龄等加入到训练中,这样训练出来的网络在Reid上的效果有很大提升,参见Improving Person Re-identification by Attribute and Identity Learning。
闲话太多了,开始讲故事。RCNN系列的故事我这里是不讲的,这里是按着YOLO和SSD的风格来讲的。
到底该如何检测图片中的物体呢?看下面的图吧。将原图打散成7*7的格子,基于每个格子再预设2个不同长宽比的虚拟框,然后调整虚拟框的大小以使得虚拟框来拟合真实的物体边框。大概的想法就是这样的。模型不需要从整张图片的角度来预测物体的位置,而是从局部的角度来进行预测,为模型减负。而且,预设的不同长宽比的虚拟框,也是减轻模型负担的一种方式,其实也给模型提供了更多的信息。大概的思路就是如此。但是真正实施起来,各路大神开始各显神通。我们先来说SSD。
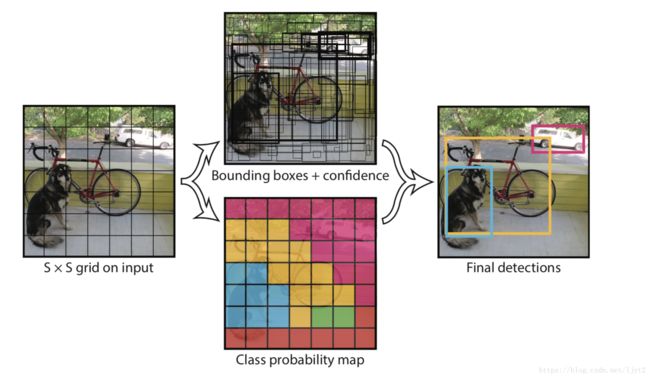
(一)先要说一些概念:见下图

(二)刚才说过,将图片打散成7*7的格子,然后针对每一个格子进行相应的预测。而神经网络的不同的部分的特征图其实就可以看作原图像打不同细致程度的格子的结果,因为随着网络深度增加,每个节点的感受野增大了,所以越往后的特征图打格子的程度越粗。反之越细致。不同细致程度的特征图正好可以用来检测不同大小的物体,正如下图所解释的。
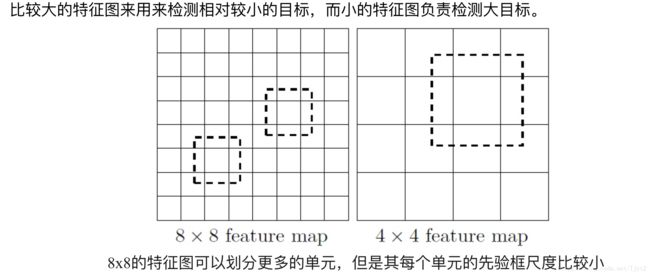
(三)理解到这里之后,我们就可以看SSD-300的网络图:
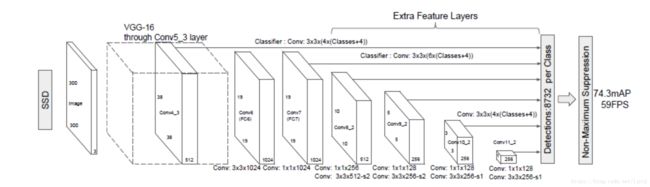


看到这里应该也都不难理解,只是对不同的特征图进行预测。
(四)具体的边框参数设定
刚才说了将图片打成格子后,每个格子会相应有若干个不同长宽比的虚拟框,那么这些虚拟框的大小到底是多大呢?不同特征图上的虚拟框的大小又有何区别?有一个前提,实现我们会将物体对应的真实边框坐标归一化,也就是相应的除以原始图片的长和宽。因此,下面说到的参数都是在0,1之间。
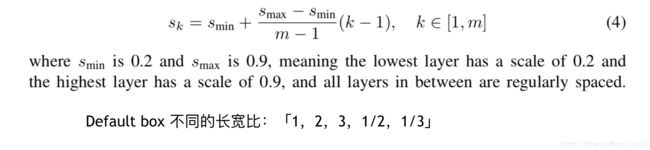

这是ssd的default box的大小的设定方式。
(五)到底是怎么训练啊?
如果只是看上面这些理论,估计很难搞懂。下面具体说一下,上面这些理论是怎么具体串起来的。
1、数据归一化
模型真正读进去的数据是刚才说的归一化之后的数据,也就是需要把标注的坐标和得到的物体的长和宽除以原始图片的长和宽。具体代码
注意:严格意义上讲,这里所标注的数据,并不是真正意义上的训练数据,因为后面ssd自己有一套方法来根据default box来产生训练数据。
2、训练数据生成
按照前面的说法,ssd-300共有8732个预测框,但是前期训练的时候,并不是每一张图片输进去,就基于所有的预测框给一个损失函数,然后反向传播。而是在8732个预测框中有针对性的选择一部分来作为训练数据,包括正例(含有物体的框)和反例(背景框),反例(背景框)的选取还是有讲究的,毕竟大部分框都是背景框,如果都拿来训练,那么会造成严重的类别不平衡。
正例的产生: tensorflow 相关代码

我想上面的解释还是不错的,里面的IOU称为交并比,其实就是两个框的交集的面积除以它们并集的面积,也称为jaccard overlap 或者 jaccard 距离,以此来度量两个框的相似度:

反例的产生—Hard example miner

注:背景框的定位损失默认为[0,0,0,0] 相关代码
tensorflow给出的反例产生的代码段的链接
config文件中的hard_example_miner参数设置:
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image:0
}1)0.99 相当于不进行NMS,只是单纯的按损失排序。所以,这个参数尽量不要动,否则就违背了SSD模型的原意。
2)loss_type 是选择排序所用的损失的类型:classification, localization, both,三种。相关代码链接在这里。
3、损失函数
损失函数分为两部分:定位损失和分类损失,对于反例预测框,其定位损失是零。

(六)mobileNet v1
原文在此,核心的想法是经典的卷积操作转化为 深度可分离卷积
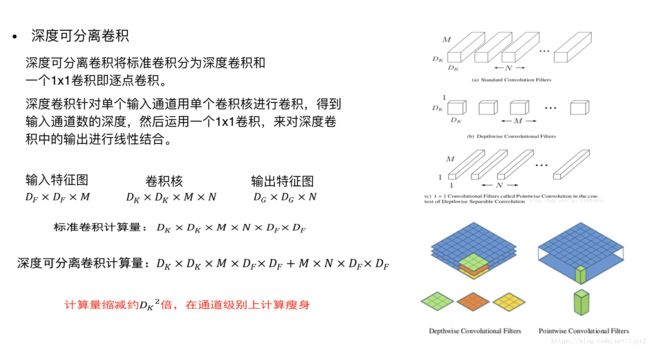
mobilenet v1 网络架构:
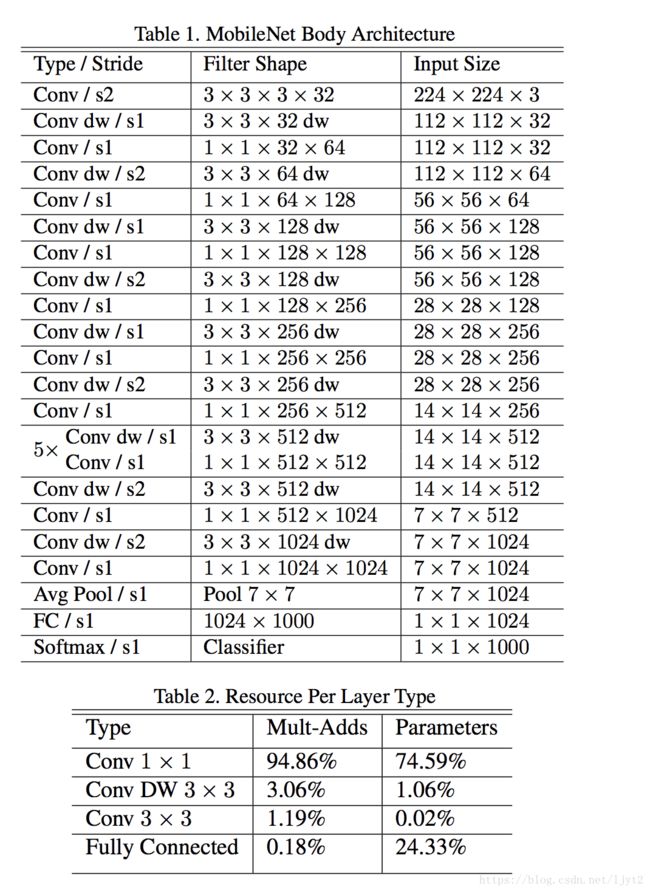
相关代码
用此网络来替换前面ssd网络架构中的VGG16,所得到的模型即为ssd-mobilenet v1. 最终从此网络中选取两个特征图,及后续再产生4个特征图,总共6个特征图来作为ssd用来进行检测的特征图相关代码。