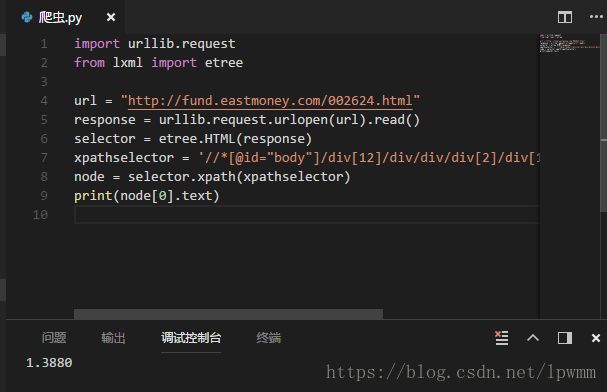
使用lxml编写简单爬虫实例
这里使用Python3.6.5,Python的安装就不用说了,需要先安装lxml,ps:翻阅了许多资料里面用的是urllib2进行网页内容的获取,在Python3.x版本中其实urllib2已经合并到了urllib里面。
pip install lxml
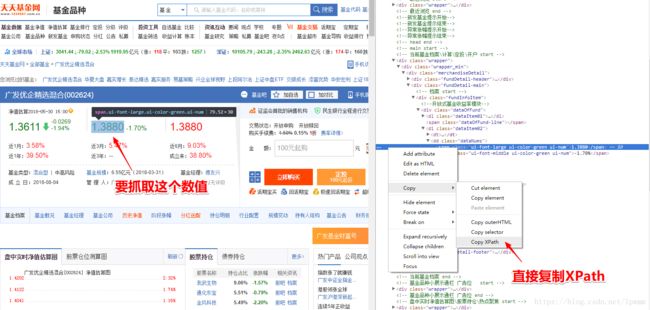
下面是对天天基金网的一个固定静态页面中的制定内容进行抓取
import urllib.request
from lxml import etree
url = "http://fund.eastmoney.com/002624.html"
response = urllib.request.urlopen(url).read()
selector = etree.HTML(response)
xpathselector = '//*[@id="body"]/div[12]/div/div/div[2]/div[1]/div[1]/dl[2]/dd[1]/span[1]'
node = selector.xpath(xpathselector)
print(node[0].text)