Python100天学习笔记 Day06-10
Python - 100天从新手到大师
项目地址:https://github.com/jackfrued/Python-100-Days
Day 06 函数和模块的使用
在Python中可以使用def关键字来定义函数,函数名命名规则和变量的命名规则一致,在函数后面的圆括号中可以放置传递给函数的参数,函数体的最后通过return关键字来返回一个值。
例如:构建一个阶乘函数
def factorial(num):
"""
求阶乘
:param num: 非负整数
:return: num的阶乘
"""
result = 1
for n in range(1, num + 1):
result *= n
return result
m = int(input('m = '))
n = int(input('n = '))
# 当需要计算阶乘的时候不用再写循环求阶乘而是直接调用已经定义好的函数
print(factorial(m) // factorial(n) // factorial(m - n))在Python中,函数的参数可以有默认值,也支持使用可变参数,所以Python并不需要像其他语言一样支持函数的重载
例如:一个简单的加和,可见可变参数是如何定义的,而且它也是可迭代对象
# 设定参数默认值
def add(a=0, b=0, c=0):
return a + b + c
# 在参数名前面的*表示args是一个可变参数
# 即在调用add函数时可以传入0个或多个参数
def add(*args):
total = 0
for val in args:
total += val
return total还是由于Python没有函数重载的概念,所以如果重复定义函数,后面的函数会对前面的进行覆盖。但是如果项目是由多人协作进行团队开发,团队中可能有多个人定义了同名的函数,那么怎么解决这种命名冲突呢?答案其实很简单,Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块就可以区分到底要使用的是哪个模块中的函数
module1.py
def foo():
print('hello, world!')module2.py
def foo():
print('goodbye, world!')test.py
from module1 import foo
# 输出hello, world!
foo()
from module2 import foo
# 输出goodbye, world!
foo()也可以按照如下所示的方式来区分到底要使用哪一个foo函数。
test.py
import module1 as m1
import module2 as m2
m1.foo()
m2.foo()笔者认为第二种方式较好✔,别名总是比较方便区分的。
需要说明的是,如果我们导入的模块除了定义函数之外还中有可以执行代码,那么Python解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,因此如果我们在模块中编写了执行代码,最好是将这些执行代码放入如下所示的条件中,这样的话除非直接运行该模块,if条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是“__main__”。
def foo():
pass
def bar():
pass
# __name__是Python中一个隐含的变量它代表了模块的名字
# 只有被Python解释器直接执行的模块的名字才是__main__
if __name__ == '__main__':
print('call foo()')
foo()
print('call bar()')
bar()Python中的变量作用域
def foo():
b = 'hello'
def bar(): # Python中可以在函数内部再定义函数
c = True
print(a)
print(b)
print(c)
bar()
# print(c) # NameError: name 'c' is not defined
if __name__ == '__main__':
a = 100
# print(b) # NameError: name 'b' is not defined
foo()上面的代码能够顺利的执行并且打印出100和“hello”,但我们注意到了,在bar函数的内部并没有定义a和b两个变量,那么a和b是从哪里来的。我们在上面代码的if分支中定义了一个变量a,这是一个全局变量(global variable),属于全局作用域,因为它没有定义在任何一个函数中。在上面的foo函数中我们定义了变量b,这是一个定义在函数中的局部变量(local variable),属于局部作用域,在foo函数的外部并不能访问到它;但对于foo函数内部的bar函数来说,变量b属于嵌套作用域,在bar函数中我们是可以访问到它的。bar函数中的变量c属于局部作用域,在bar函数之外是无法访问的。事实上,Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索,前三者我们在上面的代码中已经看到了,所谓的“内置作用域”就是Python内置的那些隐含标识符min、len等都属于内置作用域)。
简单的说,就是内层的可以访问外层的,但是反之则不行。
def foo():
a = 200
print(a) # 200
if __name__ == '__main__':
a = 100
foo()
print(a) # 100这里在foo里写a=200相当于是重新定义了一个名为a的变量并赋值,而且属于局部作用域,因此foo函数就不会理会全局作用域中的a了。如果我们希望在foo函数中修改全局作用域中的a,代码如下所示。
def foo():
global a
a = 200
print(a) # 200
if __name__ == '__main__':
a = 100
foo()
print(a) # 200我们可以使用global关键字来指示foo函数中的变量a来自于全局作用域,如果全局作用域中没有a,那么下面一行的代码就会定义变量a并将其置于全局作用域。同理,如果我们希望函数内部的函数能够修改嵌套作用域中的变量,可以使用nonlocal关键字来指示变量来自于嵌套作用域。
在实际开发中,我们应该尽量减少对全局变量的使用,因为全局变量的作用域和影响过于广泛,可能会发生意料之外的修改和使用,除此之外全局变量比局部变量拥有更长的生命周期,可能导致对象占用的内存长时间无法被垃圾回收。事实上,减少对全局变量的使用,也是降低代码之间耦合度的一个重要举措,同时也是对迪米特法则(一个对象应当对其他对象有尽可能少的了解)的践行。减少全局变量的使用就意味着我们应该尽量让变量的作用域在函数的内部,但是如果我们希望将一个局部变量的生命周期延长,使其在函数调用结束后依然可以访问,这时候就需要使用闭包。
练习1:实现计算最大公约数和最小公倍数的函数
# -*- coding: utf-8 -*-
# 辗转相除法求最大公约数
def gcd(a: int, b: int):
if a < b:
a, b = b, a
if b == 0:
return a
else:
return gcd(b, a % b)
# 求最小公倍数
# 定理:a、b 两个数的最小公倍数乘以它们的最大公约数等于 a 和 b 本身的乘积。
def lcm(a: int, b: int):
return a * b // gcd(a, b)
if __name__ == '__main__':
print(gcd(123456, 7890)) # 6
print(lcm(24, 21)) # 168
练习2:实现判断一个数是不是回文数的函数
# -*- coding: utf-8 -*-
# 两种方法判断数字是否为回文数
# 使用遍历的方式比对头尾
def palid_1(a: int):
str_a = str(a)
for i in range(0, int(len(str_a) / 2)):
if str_a[i] != str_a[-i - 1]:
return False
return True
# 使用字符串切片的方式,将字符串倒序比较
def palid_2(a: int):
str_a = str(a)
return str_a == str_a[::-1]
练习3:实现判断一个数是不是素数的函数
# -*- coding: utf-8 -*-
import math
# 判断素数
def prime_1(a: int):
if a == 2:
return 'Yes'
else:
for i in (2, int(math.sqrt(a))):
if a % i == 0:
return 'No'
return 'Yes'练习4:写一个程序判断输入的正整数是不是回文素数
# -*- coding: utf-8 -*-
from PalidNum import palid_1
from primeNum import prime_1
if __name__ == '__main__':
x = int(input('x='))
if palid_1(x) is True and prime_1(x) == 'Yes':
print('Yes')ps:在import的时候死活认不出来同目录下的module,这个时候就需要把目录改成Source类型的,在Pycharm里为蓝色文件夹图标,这样就能导了。
Day 07 字符串和常用数据结构
使用字符串
def main():
str1 = 'hello, world!'
# 通过len函数计算字符串的长度
print(len(str1)) # 13
# 获得字符串首字母大写的拷贝
print(str1.capitalize()) # Hello, world!
# 获得字符串变大写后的拷贝
print(str1.upper()) # HELLO, WORLD!
# 从字符串中查找子串所在位置
print(str1.find('or')) # 8
print(str1.find('shit')) # -1
# 与find类似但找不到子串时会引发异常
print(str1.index('or'))
print(str1.index('shit'))
# 检查字符串是否以指定的字符串开头
print(str1.startswith('He')) # False
print(str1.startswith('hel')) # True
# 检查字符串是否以指定的字符串结尾
print(str1.endswith('!')) # True
# 将字符串以指定的宽度居中并在两侧填充指定的字符
print(str1.center(50, '*'))
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
print(str1.rjust(50, ' '))
str2 = 'abc123456'
# 从字符串中取出指定位置的字符(下标运算)
print(str2[2]) # c
# 字符串切片(从指定的开始索引到指定的结束索引)
print(str2[2:5]) # c12
print(str2[2:]) # c123456
print(str2[2::2]) # c246
print(str2[::2]) # ac246
print(str2[::-1]) # 654321cba
print(str2[-3:-1]) # 45
# 检查字符串是否由数字构成
print(str2.isdigit()) # False
# 检查字符串是否以字母构成
print(str2.isalpha()) # False
# 检查字符串是否以数字和字母构成
print(str2.isalnum()) # True
str3 = ' [email protected] '
print(str3)
# 获得字符串修剪左右两侧空格的拷贝
print(str3.strip())
if __name__ == '__main__':
main()使用列表
下面的代码演示了如何定义列表、使用下标访问列表元素以及添加和删除元素的操作。
def main():
list1 = [1, 3, 5, 7, 100]
print(list1) # [1, 3, 5, 7, 100]
list2 = ['hello'] * 5
print(list2) # ['hello', 'hello', 'hello', 'hello', 'hello']
# 计算列表长度(元素个数)
print(len(list1)) # 5
# 下标(索引)运算
print(list1[0]) # 1
print(list1[4]) # 100
print(list1[5]) # IndexError: list index out of range
print(list1[-1]) # 100
print(list1[-3]) # 5
list1[2] = 300
print(list1) # [1, 3, 300, 7, 100]
# 添加元素
list1.append(200) # [1, 3, 300, 7, 100, 200]
list1.insert(1, 400) # [1, 400, 3, 300, 7, 100, 200]
list1 += [1000, 2000] # [1, 400, 3, 300, 7, 100, 200, 1000, 2000]
print(list1)
print(len(list1))
# 删除元素
list1.remove(3) # [1, 400, 300, 7, 100, 200, 1000, 2000]
if 1234 in list1:
list1.remove(1234)
del list1[0]
print(list1) # [400, 300, 7, 100, 200, 1000, 2000]
# 清空列表元素
list1.clear()
print(list1)
if __name__ == '__main__':
main()和字符串一样,列表也可以做切片操作,通过切片操作我们可以实现对列表的复制或者将列表中的一部分取出来创建出新的列表,代码如下所示。
def main():
fruits = ['grape', 'apple', 'strawberry', 'waxberry']
fruits += ['pitaya', 'pear', 'mango']
# 循环遍历列表元素
for fruit in fruits:
print(fruit.title(), end=' ') #title方法让每个单词都以大写开头
print()
# 列表切片
fruits2 = fruits[1:4]
print(fruits2)
# fruit3 = fruits # 没有复制列表只创建了新的引用
# 可以通过完整切片操作来复制列表
fruits3 = fruits[:]
print(fruits3)
fruits4 = fruits[-3:-1]
print(fruits4)
# 可以通过反向切片操作来获得倒转后的列表的拷贝
fruits5 = fruits[::-1]
print(fruits5)
if __name__ == '__main__':
main()下面的代码实现了对列表的排序操作。
def main():
list1 = ['orange', 'apple', 'zoo', 'internationalization', 'blueberry']
list2 = sorted(list1)
# sorted函数返回列表排序后的拷贝不会修改传入的列表
# 函数的设计就应该像sorted函数一样尽可能不产生副作用
list3 = sorted(list1, reverse=True)
# 通过key关键字参数指定根据字符串长度进行排序而不是默认的字母表顺序
list4 = sorted(list1, key=len)
print(list1)
print(list2)
print(list3)
print(list4)
# 给列表对象发出排序消息直接在列表对象上进行排序
list1.sort(reverse=True)
print(list1)
if __name__ == '__main__':
main()还可以使用列表的生成式语法来创建列表,注意括号的不同,一种是用空间换时间,一种是用时间换空间,按需取用
import sys
def main():
f = [x for x in range(1, 10)]
print(f)
f = [x + y for x in 'ABCDE' for y in '1234567']
print(f)
# 用列表的生成表达式语法创建列表容器
# 用这种语法创建列表之后元素已经准备就绪所以需要耗费较多的内存空间
f = [x ** 2 for x in range(1, 1000)]
print(sys.getsizeof(f)) # 查看对象占用内存的字节数
print(f)
# 请注意下面的代码创建的不是一个列表而是一个生成器对象
# 通过生成器可以获取到数据但它不占用额外的空间存储数据
# 每次需要数据的时候就通过内部的运算得到数据(需要花费额外的时间)
f = (x ** 2 for x in range(1, 1000))
print(sys.getsizeof(f)) # 相比生成式生成器不占用存储数据的空间
print(f)
for val in f:
print(val)
if __name__ == '__main__':
main()Python中还有另外一种定义生成器的方式,就是通过yield关键字将一个普通函数改造成生成器函数。下面的代码演示了如何实现一个生成斐波拉切数列的生成器。
斐波那契数列的递归公式是:F(0)=0,F(1)=1,Fn=F(n-1)+F(n-2)
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
yield a
def main():
for val in fib(20):
print(val)
if __name__ == '__main__':
main()程序开始执行之后,因为fib函数中有yield关键字,所以fib函数并不会真的执行,yield跟return类似,但是return会直接返回一个结果,而yield不会,yield把fib函数变成了一个生成器,除非用next方法或者用循环遍历的方式,才能让fib生成器一个接一个的返回a的值,每次只返回一个值,执行一次next后,yield语句被挂起,等待下一次的调用。
在yield被挂起的时候,是可以通过send方法来传入值的,而send方法中也包含了next方法,所以程序会继续向下运行。(我寻思这种破坏完整性的操作一般啥时候能用上啊?)
使用元组
元组与列表类似,不同之处在于元组的元素不能修改
def main():
# 定义元组
t = ('骆昊', 38, True, '四川成都')
print(t)
# 获取元组中的元素
print(t[0])
print(t[3])
# 遍历元组中的值
for member in t:
print(member)
# 重新给元组赋值
# t[0] = '王大锤' # TypeError
# 变量t重新引用了新的元组原来的元组将被垃圾回收
t = ('王大锤', 20, True, '云南昆明')
print(t)
# 将元组转换成列表
person = list(t)
print(person)
# 列表是可以修改它的元素的
person[0] = '李小龙'
person[1] = 25
print(person)
# 将列表转换成元组
fruits_list = ['apple', 'banana', 'orange']
fruits_tuple = tuple(fruits_list)
print(fruits_tuple)
if __name__ == '__main__':
main()可以看到,单独修改元组中的元素是不可以的,除非给整个元组重新赋值。
这里有一个非常值得探讨的问题,我们已经有了列表这种数据结构,为什么还需要元组这样的类型呢?
元组中的元素是无法修改的,事实上我们在项目中尤其是多线程环境(后面会讲到)中可能更喜欢使用的是那些不变对象(一方面因为对象状态不能修改,所以可以避免由此引起的不必要的程序错误,简单的说就是一个不变的对象要比可变的对象更加容易维护;另一方面因为没有任何一个线程能够修改不变对象的内部状态,一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。一个不变对象可以方便的被共享访问)。所以结论就是:如果不需要对元素进行添加、删除、修改的时候,可以考虑使用元组,当然如果一个方法要返回多个值,使用元组也是不错的选择。
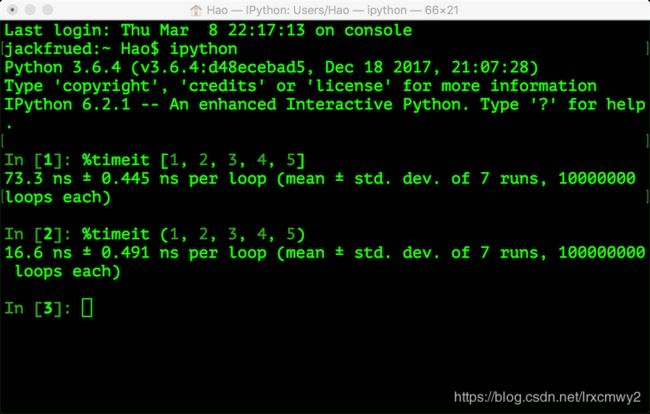
元组在创建时间和占用的空间上面都优于列表。我们可以使用sys模块的getsizeof函数来检查存储同样的元素的元组和列表各自占用了多少内存空间,这个很容易做到。我们也可以在ipython中使用魔法指令%timeit来分析创建同样内容的元组和列表所花费的时间,下图是作者的macOS系统上测试的结果。
使用集合
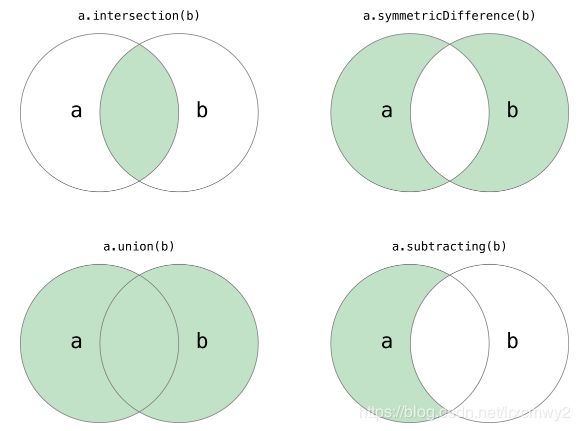
Python中的集合跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集等运算。
def main():
set1 = {1, 2, 3, 3, 3, 2}
print(set1)
print('Length =', len(set1))
set2 = set(range(1, 10))
print(set2)
set1.add(4)
set1.add(5)
set2.update([11, 12])
print(set1)
print(set2)
set2.discard(5)
# remove的元素如果不存在会引发KeyError,但discard不会
if 4 in set2:
set2.remove(4)
print(set2)
# 遍历集合容器
for elem in set2:
print(elem ** 2, end=' ')
print()
# 将元组转换成集合
set3 = set((1, 2, 3, 3, 2, 1))
# 取出第一个元素,并在元组中将该元素删除
print(set3.pop())
print(set3)
# 集合的交集、并集、差集、对称差运算
print(set1 & set2)
# print(set1.intersection(set2))
print(set1 | set2)
# print(set1.union(set2))
print(set1 - set2)
# print(set1.difference(set2))
print(set1 ^ set2)
# print(set1.symmetric_difference(set2))
# 判断子集和超集
print(set2 <= set1)
# print(set2.issubset(set1))
print(set3 <= set1)
# print(set3.issubset(set1))
print(set1 >= set2)
# print(set1.issuperset(set2))
print(set1 >= set3)
# print(set1.issuperset(set3))
if __name__ == '__main__':
main()使用字典
字典是另一种可变容器模型,每个元素都是由一个键和一个值组成的键值对,key和value通过冒号分开。
def main():
scores = {'骆昊': 95, '白元芳': 78, '狄仁杰': 82}
# 通过键可以获取字典中对应的值
print(scores['骆昊'])
print(scores['狄仁杰'])
# 对字典进行遍历(遍历的其实是键再通过键取对应的值)
for elem in scores:
print('%s\t--->\t%d' % (elem, scores[elem]))
# 更新字典中的元素
scores['白元芳'] = 65
scores['诸葛王朗'] = 71
scores.update(冷面=67, 方启鹤=85)
print(scores)
if '武则天' in scores:
print(scores['武则天'])
print(scores.get('武则天'))
# get方法也是通过键获取对应的值但是可以设置默认值
print(scores.get('武则天', 60))
# 取出字典中的第一个元素,并将其在字典中删除
print(scores.popitem())
print(scores.popitem())
print(scores.pop('骆昊', 100))
# 清空字典
scores.clear()
print(scores)
if __name__ == '__main__':
main()练习1:在屏幕上显示跑马灯文字
# -*- coding: utf-8 -*-
import os
import time
def main():
content = '北京欢迎你为你开天辟地…………'
while True:
# 清理屏幕上的输出
os.system('cls') # os.system('clear')
print(content)
# 休眠200毫秒
time.sleep(0.2)
content = content[1:] + content[0]
if __name__ == '__main__':
main()
练习2:设计一个函数产生指定长度的验证码,验证码由大小写字母和数字构成。
# -*- coding: utf-8 -*-
# 设计一个函数产生指定长度的验证码,验证码由大小写字母和数字构成。
# Author : Kevin Luo
import random
def idencode(n: int):
strlist = '1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
code = ''
for i in range(0, n):
x = random.randint(0, 61)
code += strlist[x]
return code
if __name__ == '__main__':
a = int(input('长度为:'))
flag = 0
while flag == 0:
x = idencode(a)
if (x.isalpha() is not True) and (x.isdigit() is not True):
flag = 1
print(x)
练习3:设计一个函数返回给定文件名的后缀名。
# -*- coding: utf-8 -*-
# 设计一个函数返回给定文件名的后缀名。
# Author : Kevin Luo
def getsuffix(s: str):
tmp = s.split('.')
if len(tmp) != 2:
print("Error Filename")
else:
return tmp[1]
if __name__ == '__main__':
s = input('Filename:')
result = getsuffix(s)
if result is not None:
print(result)
练习4:设计一个函数返回传入的列表中最大和第二大的元素的值。
# -*- coding: utf-8 -*-
# 设计一个函数返回传入的列表中最大和第二大的元素的值。
# Author: Kevin Luo
def top2num(a: list):
a.sort(reverse=True)
return a[0], a[1]
if __name__ == '__main__':
a = input('list=')
la = a.split(",")
print(top2num(la))
练习5:计算指定的年月日是这一年的第几天
# -*- coding: utf-8 -*-
# 计算指定的年月日是这一年的第几天
# Author: Kevin Luo
def getday(a, b, c):
# 闰年判断
rn = False
if a % 100 == 0 and a % 400 == 0:
rn = True
elif a % 4 == 0:
rn = True
# 创建一个dict,月份对应总天数
daydict = {1: 31, 2: 28, 3: 31, 4: 30, 5: 31, 6: 30, 7: 31, 8: 31, 9: 30, 10: 31, 11: 30, 12: 31}
# 根据闰年标记更新2月的天数
if rn is True:
daydict[2] = 29
# 变量n用于计算指定月份前的总天数
n = 0
for i in range(1, b):
n += daydict[i]
# 加上该月天数
n += c
return n
if __name__ == '__main__':
a = int(input('year:'))
b = int(input('month:'))
c = int(input('day:'))
print("这是该年的第%d天" % getday(a, b, c))
练习6:打印杨辉三角。
# -*- coding: utf-8 -*-
# 打印杨辉三角
# 这种思路是使用生成器,每次先生成中间的数字,然后两端补1
def triangles(n):
N = [1]
while len(N) != n + 1:
yield N
s = N
N = [s[i] + s[i + 1] for i in range(len(s) - 1)]
N.append(1)
N.insert(0, 1)
# 这种思路是通过在末尾补0实现两端的1,中间的值跟上面的思路是一样的
# [1] 补0
# [1,0] s[-1]+s[0]=0+1=1 s[0]+s[1]=1+0=1 [1,1] 补0
# [1,1,0] s[-1]+s[0]=0+1=1 s[0]+s[1]=1+1=2 s[1]+s[2]=1 [1,2,1]
def triangles2(n):
N = [1]
while len(N) != n+1:
yield N
s = N
s.append(0)
N = [s[i - 1] + s[i] for i in range(len(s))]
if __name__ == '__main__':
n = int(input('n='))
for t in triangles(n):
print(t)
for t in triangles2(n):
print(t)
综合案例1:双色球选号
# -*- coding: utf-8 -*-
# “双色球”每注投注号码由6个红色球号码和1个蓝色球号码组成。红色球号码从1--33中选择;蓝色球号码从1--16中选择。
import random
def randchoose(color):
if color == 'red':
return random.randint(1, 33)
else:
return random.randint(1, 16)
if __name__ == '__main__':
n = int(input('投注数:'))
for i in range(1, n + 1):
print('红球:', end=' ')
for j in range(1, 7):
print(randchoose('red'), end=' ')
print('蓝球:', randchoose('blue'))
综合案例2:约瑟夫环问题
# -*- coding: utf-8 -*-
# 《幸运的基督徒》
# 有15个基督徒和15个非基督徒在海上遇险,为了能让一部分人活下来不得不将其中15个人扔到海里面去,有个人想了个办法就是大家围成一个圈,
# 由某个人开始从1报数,报到9的人就扔到海里面,他后面的人接着从1开始报数,报到9的人继续扔到海里面,直到扔掉15个人。由于上帝的保佑,
# 15个基督徒都幸免于难,问这些人最开始是怎么站的,哪些位置是基督徒哪些位置是非基督徒。
def main():
persons = [True] * 30
# counter:报数计数器,记录已经扔到海里的人数
# index:索引,用于循环数数,当数到第30个的时候会回到第一个
#
counter, index, number = 0, 0, 0
while counter < 15:
if persons[index]:
number += 1
if number == 9:
persons[index] = False
counter += 1
number = 0
index += 1
index %= 30
for person in persons:
print('基' if person else '非', end='')
if __name__ == '__main__':
main()
综合案例3:井字棋游戏
没做>,<
Day 08 面向对象编程基础
面向对象编程:把一组数据结构和处理它们的方法组成对象(object),把相同行为的对象归纳为类(class),通过类的封装(encapsulation)隐藏内部细节,通过继承(inheritance)实现类的特化(specialization)和泛化(generalization),通过多态(polymorphism)实现基于对象类型的动态分派。
类和对象
类是对象的蓝图和模版,对象是类的实例,在面向对象编程的世界中,一切皆为对象,对象都有属性和行为,每个对象都是独一无二的,而且对象一定属于某个类(型)。当我们把一大堆拥有共同特征的对象的静态特征(属性)和动态特征(行为)都抽取出来后,就可以定义出一个叫做“类”的东西。
定义类
在Python中可以使用class关键字定义类,然后在类中通过之前学习过的函数来定义方法,这样就可以将对象的动态特征描述出来,代码如下所示。
class Student(object):
# __init__是一个特殊方法用于在创建对象时进行初始化操作
# 通过这个方法我们可以为学生对象绑定name和age两个属性
def __init__(self, name, age):
self.name = name
self.age = age
def study(self, course_name):
print('%s正在学习%s.' % (self.name, course_name))
# PEP 8要求标识符的名字用全小写多个单词用下划线连接
# 但是部分程序员和公司更倾向于使用驼峰命名法(驼峰标识)
def watch_movie(self):
if self.age < 18:
print('%s只能观看《熊出没》.' % self.name)
else:
print('%s正在观看岛国爱情大电影.' % self.name)创建和使用对象
定义好一个类之后,可以通过下面的方式来创建对象并给对象发消息。
def main():
# 创建学生对象并指定姓名和年龄
stu1 = Student('骆昊', 38)
# 给对象发study消息
stu1.study('Python程序设计')
# 给对象发watch_av消息
stu1.watch_movie()
stu2 = Student('王大锤', 15)
stu2.study('思想品德')
stu2.watch_movie()
if __name__ == '__main__':
main()访问可见性问题
在很多面向对象编程语言中,我们通常会将对象的属性设置为私有的(private)或受保护的(protected),简单的说就是不允许外界访问,而对象的方法通常都是公开的(public),因为公开的方法就是对象能够接受的消息。在Python中,属性和方法的访问权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在给属性命名时可以用两个下划线作为开头。
class Test:
def __init__(self, foo):
self.__foo = foo
def __bar(self):
print(self.__foo)
print('__bar')
def main():
test = Test('hello')
# AttributeError: 'Test' object has no attribute '__bar'
test.__bar()
# AttributeError: 'Test' object has no attribute '__foo'
print(test.__foo)
if __name__ == "__main__":
main()可以发现,无论是通过直接访问私有属性还是通过方法去访问私有属性都是会报错的,但事实上还是有别的骚操作可以访问到的
class Test:
def __init__(self, foo):
self.__foo = foo
def __bar(self):
print(self.__foo)
print('__bar')
def main():
test = Test('hello')
test._Test__bar()
print(test._Test__foo)
if __name__ == "__main__":
main()在实际开发中,我们并不建议将属性设置为私有的,因为这会导致子类无法访问(后面会讲到)。所以大多数Python程序员会遵循一种命名惯例就是让属性名以单下划线开头来表示属性是受保护的,本类之外的代码在访问这样的属性时应该要保持慎重。这种做法并不是语法上的规则,单下划线开头的属性和方法外界仍然是可以访问的,所以更多的时候它是一种暗示或隐喻。
面向对象的支柱
面向对象有三大支柱:封装、继承和多态。后面两个概念在下一个章节中进行详细的说明,这里我们先说一下什么是封装。我自己对封装的理解是“隐藏一切可以隐藏的实现细节,只向外界暴露(提供)简单的编程接口”。我们在类中定义的方法其实就是把数据和对数据的操作封装起来了,在我们创建了对象之后,只需要给对象发送一个消息(调用方法)就可以执行方法中的代码,也就是说我们只需要知道方法的名字和传入的参数(方法的外部视图),而不需要知道方法内部的实现细节(方法的内部视图)。
练习1:定义一个类描述数字时钟
# -*- coding: utf-8 -*-
from time import sleep
class Clock(object):
"""数字时钟"""
def __init__(self, hour=0, minute=0, second=0):
"""初始化方法
:param hour: 时
:param minute: 分
:param second: 秒
"""
self._hour = hour
self._minute = minute
self._second = second
def run(self):
"""走字"""
self._second += 1
if self._second == 60:
self._second = 0
self._minute += 1
if self._minute == 60:
self._minute = 0
self._hour += 1
if self._hour == 24:
self._hour = 0
def show(self):
"""显示时间"""
return '%02d:%02d:%02d' % \
(self._hour, self._minute, self._second)
def main():
clock = Clock(23, 59, 58)
while True:
print(clock.show())
sleep(1)
clock.run()
if __name__ == '__main__':
main()练习2:定义一个类描述平面上的点并提供移动点和计算到另一个点距离的方法。
# -*- coding: utf-8 -*-
from math import sqrt
class Point(object):
def __init__(self, x=0, y=0):
"""初始化方法
:param x: 横坐标
:param y: 纵坐标
"""
self.x = x
self.y = y
def move_to(self, x, y):
"""移动到指定位置
:param x: 新的横坐标
"param y: 新的纵坐标
"""
self.x = x
self.y = y
def move_by(self, dx, dy):
"""移动指定的增量
:param dx: 横坐标的增量
"param dy: 纵坐标的增量
"""
self.x += dx
self.y += dy
def distance_to(self, other):
"""计算与另一个点的距离
:param other: 另一个点
"""
dx = self.x - other.x
dy = self.y - other.y
return sqrt(dx ** 2 + dy ** 2)
def __str__(self):
return '(%s, %s)' % (str(self.x), str(self.y))
def main():
p1 = Point(3, 5)
p2 = Point()
print(p1)
print(p2)
p2.move_by(-1, 2)
print(p2)
print(p1.distance_to(p2))
if __name__ == '__main__':
main()
Day 09 面向对象进阶
@property装饰器
之前我们讨论过Python中属性和方法访问权限的问题,虽然我们不建议将属性设置为私有的,但是如果直接将属性暴露给外界也是有问题的,比如我们没有办法检查赋给属性的值是否有效。我们之前的建议是将属性命名以单下划线开头,通过这种方式来暗示属性是受保护的,不建议外界直接访问,那么如果想访问属性可以通过属性的getter(访问器)和setter(修改器)方法进行对应的操作。如果要做到这点,就可以考虑使用@property包装器来包装getter和setter方法,使得对属性的访问既安全又方便,代码如下所示。有了装饰器,我们就可以抽离出大量函数中与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
class Person(object):
def __init__(self, name, age):
self._name = name
self._age = age
# 访问器 - getter方法
@property
def name(self):
return self._name
# 访问器 - getter方法
@property
def age(self):
return self._age
# 修改器 - setter方法
@age.setter
def age(self, age):
self._age = age
def play(self):
if self._age <= 16:
print('%s正在玩飞行棋.' % self._name)
else:
print('%s正在玩斗地主.' % self._name)
def main():
person = Person('王大锤', 12)
person.play()
person.age = 22
person.play()
# person.name = '白元芳' # AttributeError: can't set attribute
if __name__ == '__main__':
main()__slots__魔法
通常,动态语言允许我们在程序运行时给对象绑定新的属性或方法,当然也可以对已经绑定的属性和方法进行解绑定。但是如果我们需要限定自定义类型的对象只能绑定某些属性,可以通过在类中定义__slots__变量来进行限定。需要注意的是__slots__的限定只对当前类的对象生效,对子类并不起任何作用。__slot__
在python中,它是使用字典来保存一个对象的实例属性的。这非常有用,因为它允许我们我们在运行时去设置任意的新属性。
但是,这对某型已知属性的类来说,它可能是一个瓶颈。因为这个字典浪费了很多内存。
python不能在对象创建的时候直接分配一个固定量的内存来保存所有属性,因此如果你有成千上万的属性的时候,它就会消耗很多内存。但是我们可以通过__slot__来告诉python不要使用字典,而是只给一个固定集合的属性分配空间。
使用__slots__的原因引自:https://www.jianshu.com/p/c0e5f7addb54
class Person(object):
# 限定Person对象只能绑定_name, _age和_gender属性
__slots__ = ('_name', '_age', '_gender')
def __init__(self, name, age):
self._name = name
self._age = age
@property
def name(self):
return self._name
@property
def age(self):
return self._age
@age.setter
def age(self, age):
self._age = age
def play(self):
if self._age <= 16:
print('%s正在玩飞行棋.' % self._name)
else:
print('%s正在玩斗地主.' % self._name)
def main():
person = Person('王大锤', 22)
person.play()
person._gender = '男'
# AttributeError: 'Person' object has no attribute '_is_gay'
# person._is_gay = True静态方法和类方法
之前,我们在类中定义的方法都是对象方法,也就是说这些方法都是发送给对象的消息。实际上,我们写在类中的方法并不需要都是对象方法,例如我们定义一个“三角形”类,通过传入三条边长来构造三角形,并提供计算周长和面积的方法,但是传入的三条边长未必能构造出三角形对象,因此我们可以先写一个方法来验证三条边长是否可以构成三角形,这个方法很显然就不是对象方法,因为在调用这个方法时三角形对象尚未创建出来(因为都不知道三条边能不能构成三角形),所以这个方法是属于三角形类而并不属于三角形对象的。我们可以使用静态方法来解决这类问题,代码如下所示。通过@staticmethod来标识静态方法
from math import sqrt
class Triangle(object):
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
@staticmethod
def is_valid(a, b, c):
return a + b > c and b + c > a and a + c > b
def perimeter(self):
return self._a + self._b + self._c
def area(self):
half = self.perimeter() / 2
return sqrt(half * (half - self._a) *
(half - self._b) * (half - self._c))
def main():
a, b, c = 3, 4, 5
# 静态方法和类方法都是通过给类发消息来调用的
if Triangle.is_valid(a, b, c):
t = Triangle(a, b, c)
print(t.perimeter())
# 也可以通过给类发消息来调用对象方法但是要传入接收消息的对象作为参数
# print(Triangle.perimeter(t))
print(t.area())
# print(Triangle.area(t))
else:
print('无法构成三角形.')
if __name__ == '__main__':
main()和静态方法比较类似,Python还可以在类中定义类方法,类方法用classmethod标识,第一个参数约定名为cls,它代表的是当前类相关的信息的对象(类本身也是一个对象,有的地方也称之为类的元数据对象),通过这个参数我们可以获取和类相关的信息并且可以创建出类的对象,代码如下所示。
from time import time, localtime, sleep
class Clock(object):
"""数字时钟"""
def __init__(self, hour=0, minute=0, second=0):
self._hour = hour
self._minute = minute
self._second = second
@classmethod
def now(cls):
ctime = localtime(time())
return cls(ctime.tm_hour, ctime.tm_min, ctime.tm_sec)
def run(self):
"""走字"""
self._second += 1
if self._second == 60:
self._second = 0
self._minute += 1
if self._minute == 60:
self._minute = 0
self._hour += 1
if self._hour == 24:
self._hour = 0
def show(self):
"""显示时间"""
return '%02d:%02d:%02d' % \
(self._hour, self._minute, self._second)
def main():
# 通过类方法创建对象并获取系统时间
clock = Clock.now()
while True:
print(clock.show())
sleep(1)
clock.run()
if __name__ == '__main__':
main()类之间的关系
类之间的关系有三种:is-a、has-a和use-a关系
- is-a:继承关系,比如手机和电子产品的关系
- has-a:关联关系,比如汽车和引擎的关系,部门和员工的关系,关联关系如果是整体和部分的关联,那么我们称之为聚合关系;如果整体进一步负责了部分的生命周期(整体和部分是不可分割的,同时同在也同时消亡),那么这种就是最强的关联关系,我们称之为合成关系。
- use-a:依赖关系,比如司机有一个驾驶的行为(方法),其中(的参数)使用到了汽车,那么司机和汽车的关系就是依赖关系。
继承和多态
刚才我们提到了,可以在已有类的基础上创建新类,这其中的一种做法就是让一个类从另一个类那里将属性和方法直接继承下来,从而减少重复代码的编写。提供继承信息的我们称之为父类,也叫超类或基类;得到继承信息的我们称之为子类,也叫派生类或衍生类。子类除了继承父类提供的属性和方法,还可以定义自己特有的属性和方法,所以子类比父类拥有的更多的能力,在实际开发中,我们经常会用子类对象去替换掉一个父类对象,这是面向对象编程中一个常见的行为,对应的原则称之为里氏替换原则。
class Person(object):
"""人"""
def __init__(self, name, age):
self._name = name
self._age = age
@property
def name(self):
return self._name
@property
def age(self):
return self._age
@age.setter
def age(self, age):
self._age = age
def play(self):
print('%s正在愉快的玩耍.' % self._name)
def watch_av(self):
if self._age >= 18:
print('%s正在观看爱情动作片.' % self._name)
else:
print('%s只能观看《熊出没》.' % self._name)
class Student(Person):
"""学生"""
def __init__(self, name, age, grade):
super().__init__(name, age) # 使用super函数将子类与父类相同的参数依次传入
# __init__(xxx)的xxx参数中
self._grade = grade
@property
def grade(self):
return self._grade
@grade.setter
def grade(self, grade):
self._grade = grade
def study(self, course):
print('%s的%s正在学习%s.' % (self._grade, self._name, course))
class Teacher(Person):
"""老师"""
def __init__(self, name, age, title):
super().__init__(name, age)
self._title = title
@property
def title(self):
return self._title
@title.setter
def title(self, title):
self._title = title
def teach(self, course):
print('%s%s正在讲%s.' % (self._name, self._title, course))
def main():
stu = Student('王大锤', 15, '初三')
stu.study('数学')
stu.watch_av()
t = Teacher('骆昊', 38, '老叫兽')
t.teach('Python程序设计')
t.watch_av()
if __name__ == '__main__':
main()子类在继承了父类的方法后,可以对父类已有的方法给出新的实现版本,这个动作称之为方法重写(override)。通过方法重写我们可以让父类的同一个行为在子类中拥有不同的实现版本,当我们调用这个经过子类重写的方法时,不同的子类对象会表现出不同的行为,这个就是多态(poly-morphism)。
from abc import ABCMeta, abstractmethod
class Pet(object, metaclass=ABCMeta):
"""宠物"""
def __init__(self, nickname):
self._nickname = nickname
@abstractmethod
def make_voice(self):
"""发出声音"""
pass
class Dog(Pet):
"""狗"""
def make_voice(self):
print('%s: 汪汪汪...' % self._nickname)
class Cat(Pet):
"""猫"""
def make_voice(self):
print('%s: 喵...喵...' % self._nickname)
def main():
pets = [Dog('旺财'), Cat('凯蒂'), Dog('大黄')]
for pet in pets:
pet.make_voice()
if __name__ == '__main__':
main()在上面的代码中,我们将Pet类处理成了一个抽象类,所谓抽象类就是不能够创建对象的类,这种类的存在就是专门为了让其他类去继承它。Python从语法层面并没有像Java或C#那样提供对抽象类的支持,但是我们可以通过abc模块的ABCMeta元类和abstractmethod包装器来达到抽象类的效果,如果一个类中存在抽象方法那么这个类就不能够实例化(创建对象)。上面的代码中,Dog和Cat两个子类分别对Pet类中的make_voice抽象方法进行了重写并给出了不同的实现版本,当我们在main函数中调用该方法时,这个方法就表现出了多态行为(同样的方法做了不同的事情)。
Day 10 图形用户界面和游戏开发
基于tkinter模块的GUI
基本上使用tkinter来开发GUI应用需要以下5个步骤:
- 导入tkinter模块中我们需要的东西。
- 创建一个顶层窗口对象并用它来承载整个GUI应用。
- 在顶层窗口对象上添加GUI组件。
- 通过代码将这些GUI组件的功能组织起来。
- 进入主事件循环(main loop)。
需要说明的是,GUI应用通常是事件驱动式的,之所以要进入主事件循环就是要监听鼠标、键盘等各种事件的发生并执行对应的代码对事件进行处理,因为事件会持续的发生,所以需要这样的一个循环一直运行着等待下一个事件的发生。另一方面,Tk为控件的摆放提供了三种布局管理器,通过布局管理器可以对控件进行定位,这三种布局管理器分别是:Placer(开发者提供控件的大小和摆放位置)、Packer(自动将控件填充到合适的位置)和Grid(基于网格坐标来摆放控件),此处不进行赘述。
使用Pygame进行游戏开发
此处跳过