【python】爬虫篇:python使用psycopg2批量插入数据(三)
本人菜鸡,有什么错误,还望大家批评指出,最近在更新python的爬虫系列,○( ^皿^)っHiahiahia…
该系列暂时总共有3篇文章,连接如下
【python】爬虫篇:python连接postgresql(一):https://blog.csdn.net/lsr40/article/details/83311860
【python】爬虫篇:python对于html页面的解析(二):https://blog.csdn.net/lsr40/article/details/83380938
【python】爬虫篇:python使用psycopg2批量插入数据(三):https://blog.csdn.net/lsr40/article/details/83537974
根据前两篇的思路,我们已经将html页面解析成功,接下来就是insert插入数据库,总所周知1W条数据一条一条插入,肯定是比一次性插入1W条来得慢的,所以最好要考虑到批量插入数据库,既可以缓解数据库的压力,又能加快速度。
psycopg2的文档:http://initd.org/psycopg/docs/
# 插入数据库的方法
def insertManyRow(strings):
# 这里就不需要遍历了,因为executemany接受
# for index in range(len(rows)):
try:
conn_2 = psycopg2.connect(database="数据库", user="用户名", password="密码",
host="ip",
port="端口号")
cur2 = conn_2.cursor()
sql2 = "INSERT INTO test(字段1,字段2,字段3,字段4,字段5) VALUES(%s,%s,%s,%s,%s)"
cur2.executemany(sql2, strings)
conn_2.commit()
conn_2.close()
except Exception as e:
print("执行sql时出错:%s" % (e))
conn_word_2.rollback()
conn_2.close()关于这个strings可以传入什么样的参数类型?见如下代码:
# 第一种:strings可以是
strings = ({'num': 0, 'text': 'Zero'},
{'num': 1, 'text': 'Item One'},
{'num': 2, 'text': 'Item Two'},
{'num': 3, 'text': 'Three'})
cur.executemany("INSERT INTO test VALUES (%(num)d, %(text)s)", rows)
# 第二种:strings可以是,我测试的时候是第二种速度更快,但是应该没有快多少
strings = [[0,'zero'],[1,'item one'],[3,'item two']]
sql2 = "INSERT INTO test(num,text) VALUES(%s,%s)"
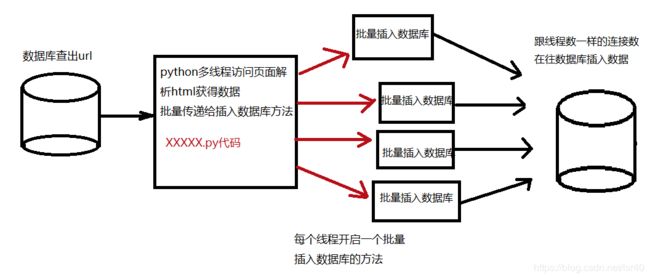
cur.executemany(sql,strings)理论上来说,插入就批量插入就好了,不要搞什么多线程,但是如果是多线程获取数据的话,看起来也只能每个线程各自往数据库中插入(下一篇文章会使用其他技术来解决这个问题),但是请注意数据库连接有限,在使用的时候注意看下数据库连接被占了多少,是否有释放连接!
因此来总结下这整套方案用的东西和缺点:
流程:
1、先从数据库查出数据
2、将每条数据通过urllib和python多线程的方式请求到页面
3、通过bs4或者xpath或者其他的html页面解析的方式去解析到我想要的东西
4、将我想要的东西一批一批的传入批量插入数据库的代码中,然后执行批量插入
每个点会遇到的问题:
1、从数据库,我一次性查出200W条数据,python报了个内存溢出的错误,我一直不太清楚python的内存机制,其实java我也没有非常清晰,希望以后会有机会多学学!可以写个循环,(在sql里面做排序,然后limit偏移量叠加)就像做java的分页功能一样,每次处理一页的数据,处理完再从数据库查询下一页(这种方式在该系列的第一篇文章中有提到,用offset和limit实现)。当然我认真搜索了下,发现了executemany方法,也就是说,我可以查询全部数据,但是并不用一次性全部加载出来,分批加载就可以(这里我没实际测试过会不会内存溢出,但是我想应该是不会溢出,毕竟不是一次性将全部数据取出),每次调用executemany,返回的结果相当于有一个游标往下偏移,就是不会查出重复数据,这样也是能够满足我的需求的。
executemany的API:http://initd.org/psycopg/docs/cursor.html?highlight=fetchmany#cursor.fetchmany,
代码如下:
if __name__ == '__main__':
conn = psycopg2.connect(database="数据库", user="用户名", password="密码",
host="ip",
port="端口")
cur = conn.cursor()
# 查询条件
sql = "查询全量数据的sql"
cur.execute(sql)
# 手动给定循环次数5次
for i in range(5):
# 每次查询1000条数据
rows = cur.fetchmany(size=1000)
print('第{i}次拉取到数据'.format(i=i+1))
for row in rows:
print(row)
conn.close()2、这步就考虑用多线程还是多进程,每个线程(进程)的数据从哪来,必须不能重复;有时候在请求页面的时候会假死(卡住),相应的api是否有timeout时间,例如我用的urllib.request.urlopen(url,timeout=5)就有这样的参数;还有一点,是否会被封号,多久解封,我在做的这个是,今天被封,得等到明天才能再用,所以得有多个ip或者伪装自己的方式,并且要做爬取该文章的时候是否已经被封了,如果被封了可以发警报或者停止继续爬等等,避免浪费资源。
3、解析的方式很多,在能接受消耗资源的情况下,哪种更快?是否有更好的方式来获取(该系列第二篇文章有介绍)?解析出来的数据如何拼接,传递到下一个方法(我会在下一篇文章来谈谈这个点)是这个阶段要考虑的问题。
4、批量插入数据库,该篇文章提供了一种方法,就是解析完之后把数据List加到一个外层的List列表中(List嵌套,类似如上代码strings的第二种方式),传入批量插入的代码中执行executemany,然后我看到除了executemany之外还有一个execute_batch,并且可以设置page_size(默认值是100),这是一次能插入100条数据,然后插入多个批次固定条数的sql,我自己没有测试过,因为我每个批次数据量不大,但是看stackoverflow上,有这么一段话。

大概的意思就是说在他的测试中execute_batch的性能是executemany的两倍,并且可以调整每次插入的数据条数(page_size)。
链接在这里:https://stackoverflow.com/questions/2271787/psycopg2-postgresql-python-fastest-way-to-bulk-insert
总结:到此,结构如下