python网络爬虫系列教程——Scrapy框架应用全解
全栈工程师开发手册 (作者:栾鹏)
python教程全解
安装
在cmd中输入
Scrapy的安装依赖wheel、twiste、lxml包。所以先通过pip install wheel安装wheel库,通过pip install lxml安装lxml库,不过twiste包必须通过离线whl文件安装。
进入http://www.lfd.uci.edu/~gohlke/pythonlibs/,在网页中搜索twisted找到其对应的whl包并下载
Twisted‑17.9.0‑cp36‑cp36m‑win_amd64.whl
离线包的安装请参考:
http://blog.csdn.net/luanpeng825485697/article/details/77816740
成功安装了上面的依赖包,就可以通过pip在线安装Scrapy了
pip install Scrapy
等待一会,大功告成!
验证安装:cmd中输入Scrapy,显示如下图,表示安装成功。现在Scrapy已经出到了1.4版

另外你需要在cmd中输入以下命令,分别安装pywin32、pyOPENSSL、lxml包。
pip install pywin32
pip install pyOPENSSL
pip install lxml
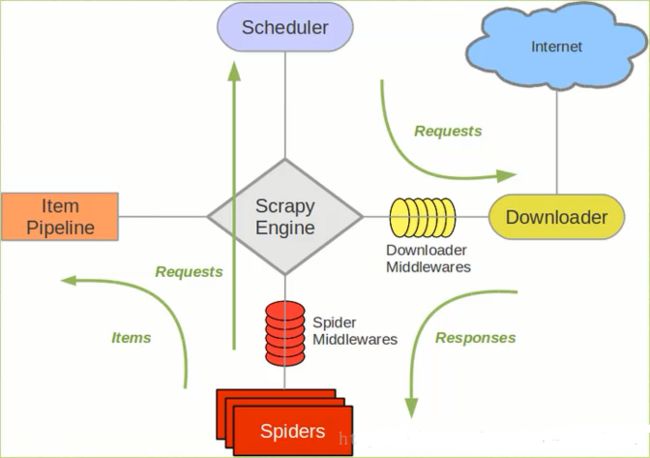
scrapy处理流程
Scrapy Engine(Scrapy核心) 负责数据流在各个组件之间的流动。Spiders(爬虫)发出Requests请求,经由Scrapy Engine(Scrapy核心) 交给Scheduler(调度器),Downloader(下载器)Scheduler(调度器) 获得Requests请求,然后根据Requests请求,从网络下载数据。Downloader(下载器)的Responses响应再传递给Spiders进行分析。根据需求提取出Items,交给Item Pipeline进行下载。Spiders和Item Pipeline是需要用户根据响应的需求进行编写的。除此之外,还有两个中间件,Downloaders Mddlewares和Spider Middlewares,这两个中间件为用户提供方面,通过插入自定义代码扩展Scrapy的功能,例如去重等。因为中间件属于高级应用,本次教程不涉及,因此不做过多讲解。
github托管:https://github.com/626626cdllp/crawler/tree/master/myscrapy
scrapy项目demo
要理解上面的流程,spiders文件夹下定义的爬虫,请求网址,获取响应,解析数据,赋值想要的数据给items中定义的类实体。最后会自动调用pipelines下的类获取items中的数据,进一步做处理。
今天我们来实现获取我的csdn中的全部文章的名称、阅读书目、链接
我的首页http://blog.csdn.net/luanpeng825485697
1、创建项目
创建项目,在cmd中先cd到你的项目路径,然后使用scrapy创建一个项目。这里将项目放在D:\scrapydemo文件夹下
所以在cmd中执行
D:
cd /scrapydemo
scrapy startproject projectname
scrapy startproject是固定命令,后面的projectname是自己想起的工程名字。
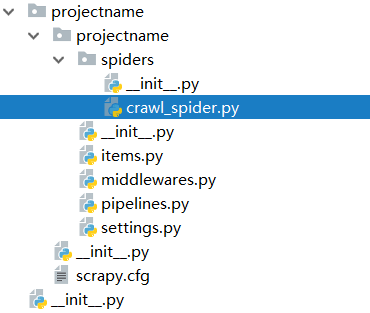
该命令将会创建包含下列内容的projectname目录:
projectname/
scrapy.cfg
projectname/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件分别是:
scrapy.cfg: 项目的配置文件;
projectname/: 该项目的python模块。之后将在此加入Spider代码;
projectname/items.py: 项目中的item文件,定义需要的实体类
projectname/middlewares .py:项目中的中间件,不用关心
projectname/pipelines.py: 项目中的pipelines文件;用来写爬虫之后的处理文件
projectname/settings.py: 项目的设置文件,定义参数
projectname/spiders/: 放置spider代码的目录。定义爬虫要放在这个文件夹下。
2、定义我们需要的实体类items.py
在这里我们定义我们需要的文章名称、链接、阅读数目
# -*- coding: utf-8 -*-
# 定义我们要爬取信息的标准格式,这个类被爬虫引用,爬虫解析数据后赋值给该类实例,并将类实例提交给pipelines,再进行进一步处理。
import scrapy
class myentity(scrapy.Item):
name = scrapy.Field()
link = scrapy.Field()
readnum = scrapy.Field()
3、创建一个爬虫
我们使用这个爬虫获取博客下的文章名称、链接地址、阅读数量。
在projectname/spiders/文件夹下新建一个crawl_spider.py,我们在这里实现请求、响应、解析的过程。
xpath语法参考http://blog.csdn.net/luanpeng825485697/article/details/78410691
# -*- coding: utf-8 -*-
# 在这里实现请求、响应、解析的过程
import re
import scrapy
import urllib
from scrapy import Selector
from projectname.items import myentity
class MySpider(scrapy.Spider):
name = 'myspider' #爬虫名称,需要这个名称才能启动爬虫
def __init__(self):
self.allowed_domains = ['blog.csdn.net']
self.start_urls = ['http://blog.csdn.net/luanpeng825485697/article/list/']
#从start_requests发送请求
def start_requests(self):
yield scrapy.Request(url = self.start_urls[0]+"1", meta = {'data':1},callback = self.parse1) #请求网址,设置响应函数,同时向响应函数传递参数
#解析response,获得文章名称、连接、阅读数目,还可以进行二次请求。
def parse1(self, response):
index = response.meta['data'] #接收请求函数发来的参数
if index>100: #这里只爬取前100页
return
hxs = Selector(response)
#文章链接地址
links = hxs.xpath("//span[@class='link_title']/a[1]/@href").extract() #xpath路径表达式获取文章连接地址
#文章名
names = hxs.xpath("//span[@class='link_title']/a[1]/text()").extract() #xpath路径表达式获取文章名
#文章阅读数量
reads = hxs.xpath("//span[@class='link_view']/text()").extract() #xpath路径表达式获取文章阅读数量
#将爬取的数据赋值给items
for i in range(1,len(links)):
item = myentity()
item['link'] = urllib.parse.urljoin('http://blog.csdn.net/',links[i]) #获取绝对域名
item['name'] = names[i]
item['readnum'] = reads[i]
# 返回item,交给item pipeline处理
yield item
#迭代下一页
yield scrapy.Request(url=self.start_urls[0]+str(index+1), meta={'data': index+1}, callback=self.parse1)
4、设置pipeline处理文件
pipeline主要是负责根据item数据进行下一步处理,比如下载图片,保存文件,
这里只是把item中的文章名称、链接、阅读书目进行保存文件。
data文件地址:https://github.com/626626cdllp/crawler/tree/master/myscrapy/projectname
# -*- coding: utf-8 -*-
#pipelines.py主要根据item保存的信息,进行进一步多线程操作
from projectname import settings
from scrapy import Request
import requests
import os
class MyPipeline(object):
allpaper=[]
def process_item(self, item, spider):
paper={}
paper['name']=item['name']
paper['link'] = item['link']
paper['read'] = item['readnum']
self.allpaper.append(paper)
file_object = open('data.txt', 'a')
file_object.write(str(paper)+"\r\n")
file_object.close()
return item
5、完善settings配置文件
settings.py中的内容大部分都是自动生成的,我们不需要做太多改动,在这里只是使用字典的形式定义自己的pipelines中的处理类
SPIDER_MODULES = ['projectname.spiders'] #自动生成的内容;
NEWSPIDER_MODULE = 'projectname.spiders' #自动生成的内容;
# Obey robots.txt rules #它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录
ROBOTSTXT_OBEY = False #自动生成的内容,是否遵守robots.txt规则,这里选择不遵守;
ITEM_PIPELINES = { #定义item的pipeline;
'projectname.pipelines.MyPipeline': 1, #此处的1表示优先级,因为本项目只用到这一个pipeline,所以随意取0-1000中的一个数值即可
}
DOWNLOAD_DELAY = 0.25 # 下载延时,这里使用250ms延时。
COOKIES_ENABLED = False #Cookie使能,这里禁止Cookie;
支持我们需要编写的东西都完成了
下图是文件目录结构
6、运行scrapy项目
首先在cmd中cd到自己的项目文件夹下,即scrapy.cfg所在的目录中,这里cd到D:\scrapydemo\projectname文件夹下,然后使用下面的代码运行自己的爬虫。myspider就是在crawl_spider.py文件中的name变量
scrapy crawl myspider