Kubernetes-基于EFK进行统一的日志管理原理(kibana查询语法)
网易公开课,开课啦!
主讲内容:docker/kubernetes 云原生技术,大数据架构,分布式微服务,自动化测试、运维。
7月1号-7月29号 8折优惠!!!
7月1号-7月29号 8折优惠!!!
7月1号-7月29号 8折优惠!!!
全栈工程师开发手册 (作者:栾鹏)
架构系列文章
EFK安装部署参考:https://blog.csdn.net/luanpeng825485697/article/details/83312662
1、统一日志管理的整体方案
通过应用和系统日志可以了解Kubernetes集群内所发生的事情,对于调试问题和监视集群活动来说日志非常有用。对于大部分的应用来说,都会具有某种日志机制。因此,大多数容器引擎同样被设计成支持某种日志机制。对于容器化应用程序来说,最简单和最易接受的日志记录方法是将日志内容写入到标准输出和标准错误流。
但是,容器引擎或运行时提供的本地功能通常不足以支撑完整的日志记录解决方案。例如,如果一个容器崩溃、一个Pod被驱逐、或者一个Node死亡,应用相关者可能仍然需要访问应用程序的日志。因此,日志应该具有独立于Node、Pod或者容器的单独存储和生命周期,这个概念被称为群集级日志记录。群集级日志记录需要一个独立的后端来存储、分析和查询日志。Kubernetes本身并没有为日志数据提供原生的存储解决方案,但可以将许多现有的日志记录解决方案集成到Kubernetes集群中。在Kubernetes中,有三个层次的日志:
- 基础日志
- Node级别的日志
- 群集级别的日志架构
1.1基础日志
kubernetes基础日志即将日志数据输出到标准输出流,可以使用kubectl logs命令获取容器日志信息。如果Pod中有多个容器,可以通过将容器名称附加到命令来指定要访问哪个容器的日志。例如,在Kubernetes集群中的devops命名空间下有一个名称为nexus3-f5b7fc55c-hq5v7的Pod,就可以通过如下的命令获取日志:
$ kubectl logs nexus3-f5b7fc55c-hq5v7 --namespace=devops
1.2 Node级别的日志
容器化应用写入到stdout和stderr的所有内容都是由容器引擎处理和重定向的。例如,docker容器引擎会将这两个流重定向到日志记录驱动,在Kubernetes中该日志驱动被配置为以json格式写入文件。docker json日志记录驱动将每一行视为单独的消息。当使用docker日志记录驱动时,并不支持多行消息,因此需要在日志代理级别或更高级别上处理多行消息。
默认情况下,如果容器重新启动,kubectl将会保留一个已终止的容器及其日志。如果从Node中驱逐Pod,那么Pod中所有相应的容器也会连同它们的日志一起被驱逐。Node级别的日志中的一个重要考虑是实现日志旋转,这样日志不会消耗Node上的所有可用存储。Kubernetes目前不负责旋转日志,部署工具应该建立一个解决方案来解决这个问题。
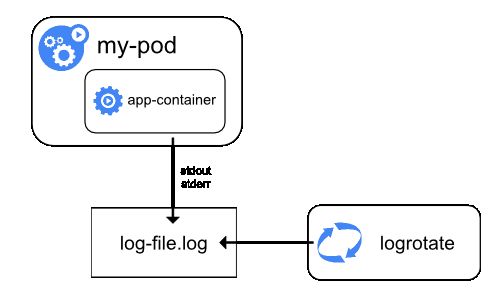
在Kubernetes中有两种类型的系统组件:运行在容器中的组件和不在容器中运行的组件。例如:
- Kubernetes调度器和kube-proxy在容器中运行。
- kubelet和容器运行时,例如docker,不在容器中运行。
在带有systemd的机器上,kubelet和容器运行时写入journaId。如果systemd不存在,它们会在**/var/log目录中写入.log文件。在容器中的系统组件总是绕过默认的日志记录机制,写入到/var/log目录,它们使用golg日志库。可以找到日志记录中开发文档中那些组件记录严重性的约定。**
类似于容器日志,在/var/log目录中的系统组件日志应该被旋转。这些日志被配置为每天由logrotate进行旋转,或者当大小超过100mb时进行旋转。
所以我们只要采集主机上/var/log/container/*.log就可以采集容器的打印日志了
1.3 集群级别的日志架构
Kubernetes本身没有为群集级别日志记录提供原生解决方案,但有几种常见的方法可以采用:
- 使用运行在每个Node上的Node级别的日志记录代理;
- 在应用Pod中包含一个用于日志记录的sidecar。
- 将日志直接从应用内推到后端。
经过综合考虑,本文采用通过在每个Node上包括Node级别的日志记录代理来实现群集级别日志记录。日志记录代理暴露日志或将日志推送到后端的专用工具。通常,logging-agent是一个容器,此容器能够访问该Node上的所有应用程序容器的日志文件。
因为日志记录必须在每个Node上运行,所以通常将它作为DaemonSet副本、或一个清单Pod或Node上的专用本机进程。然而,后两种方法后续将会被放弃。使用Node级别日志记录代理是Kubernetes集群最常见和最受欢迎的方法,因为它只为每个节点创建一个代理,并且不需要对节点上运行的应用程序进行任何更改。但是,Node级别日志记录仅适用于应用程序的标准输出和标准错误。
Kubernetes本身并没有指定日志记录代理,但是有两个可选的日志记录代理与Kubernetes版本打包发布:和谷歌云平台一起使用的Stackdriver和Elasticsearch,两者都使用自定义配置的fluentd作为Node上的代理。在本文的方案中,Logging-agent 采用 Fluentd,而 Logging Backend 采用 Elasticsearch,前端展示采用Grafana。即通过 Fluentd 作为 Logging-agent 收集日志,并推送给后端的Elasticsearch;Grafana从Elasticsearch中获取日志,并进行统一的展示。

2、安装统一日志管理的组件
在本文中采用使用Node日志记录代理的方面进行Kubernetes的统一日志管理,相关的工具采用:
- 日志记录代理(logging-agent):日志记录代理用于从容器中获取日志信息,使用Fluentd;
- 日志记录后台(Logging-Backend):日志记录后台用于处理日志记录代理推送过来的日志,使用Elasticsearch;
- 日志记录展示:日志记录展示用于向用户显示统一的日志信息,使用Kibana。
在Kubernetes中通过了Elasticsearch 附加组件,此组件包括Elasticsearch、Fluentd和Kibana。Elasticsearch是一种负责存储日志并允许查询的搜索引擎。Fluentd从Kubernetes中获取日志消息,并发送到Elasticsearch;而Kibana是一个图形界面,用于查看和查询存储在Elasticsearch中的日志。
安装部署EFK,参考https://blog.csdn.net/luanpeng825485697/article/details/83312662
2.1 Elasticsearch简介
Elasticsearch是一个基于Apache Lucene™的开源搜索和数据分析引擎引擎,Elasticsearch使用Java进行开发,并使用Lucene作为其核心实现所有索引和搜索的功能。它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。Elasticsearch不仅仅是Lucene和全文搜索,它还提供如下的能力:
- 分布式的实时文件存储,每个字段都被索引并可被搜索;
- 分布式的实时分析搜索引擎;
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据。
在Elasticsearch中,包含多个索引(Index),相应的每个索引可以包含多个类型(Type),这些不同的类型每个都可以存储多个文档(Document),每个文档又有多个属性。索引 (index) 类似于传统关系数据库中的一个数据库,是一个存储关系型文档的地方。Elasticsearch 使用的是标准的 RESTful API 和 JSON。此外,还构建和维护了很多其他语言的客户端,例如 Java, Python, .NET, 和 PHP。
2.2 Fluentd简介
Fluentd是一个开源数据收集器,通过它能对数据进行统一收集和消费,能够更好地使用和理解数据。Fluentd将数据结构化为JSON,从而能够统一处理日志数据,包括:收集、过滤、缓存和输出。Fluentd是一个基于插件体系的架构,包括输入插件、输出插件、过滤插件、解析插件、格式化插件、缓存插件和存储插件,通过插件可以扩展和更好的使用Fluentd。
Fluentd的整体处理过程如下,通过Input插件获取数据,并通过Engine进行数据的过滤、解析、格式化和缓存,最后通过Output插件将数据输出给特定的终端。

Fluentd 作为 Logging-agent 进行日志收集,并将收集到的日子推送给后端的Elasticsearch。对于Kubernetes来说,DaemonSet确保所有(或一些)Node会运行一个Pod副本。因此,Fluentd被部署为DaemonSet,它将在每个节点上生成一个pod,以读取由kubelet,容器运行时和容器生成的日志,并将它们发送到Elasticsearch。为了使Fluentd能够工作,每个Node都必须标记beta.kubernetes.io/fluentd-ds-ready=true。
2.3 Kibana简介
Kibana是一个开源的分析与可视化平台,被设计用于和Elasticsearch一起使用的。通过kibana可以搜索、查看和交互存放在Elasticsearch中的数据,利用各种不同的图表、表格和地图等,Kibana能够对数据进行分析与可视化。Kibana部署的YAML如下所示,通过环境变量ELASTICSEARCH_URL,指定所获取日志数据的Elasticsearch服务,此处为:http://elasticsearch-logging:9200,elasticsearch.cattle-logging是elasticsearch在Kubernetes中代理服务的名称。在Fluented配置文件中,有下面的一些关键指令:
- source指令确定输入源。
- match指令确定输出目标。
- filter指令确定事件处理管道。
- system指令设置系统范围的配置。
- label指令将输出和过滤器分组以进行内部路由
- @include指令包含其他文件。
kibana查询语法
elasticsearch构建在Lucene之上,过滤器语法和Lucene相同
全文搜索
在搜索栏输入login,会返回所有字段值中包含login的文档
使用双引号包起来作为一个短语搜索
"like Gecko"
字段
也可以按页面左侧显示的字段搜索
限定字段全文搜索:field:value
精确搜索:关键字加上双引号 filed:"value"
http.code:404 搜索http状态码为404的文档
字段本身是否存在
_exists_:http:返回结果中需要有http字段
_missing_:http:不能含有http字段
通配符
? 匹配单个字符
* 匹配0到多个字符
kiba?a, el*search
?*不能用作第一个字符,例如:?text*text
正则
es支持部分正则功能,性能较差
name:/joh?n(ath[oa]n)/
模糊搜索
quikc~ brwn~ foks~
~:在一个单词后面加上~启用模糊搜索,可以搜到一些拼写错误的单词
first~ 这种也能匹配到 frist
还可以设置编辑距离(整数),指定需要多少相似度
cromm~1 会匹配到 from 和 chrome
默认2,越大越接近搜索的原始值,设置为1基本能搜到80%拼写错误的单词
近似搜索
在短语后面加上~,可以搜到被隔开或顺序不同的单词
"where select"~5 表示 select 和 where 中间可以隔着5个单词,可以搜到 select password from users where id=1
范围搜索
数值/时间/IP/字符串 类型的字段可以对某一范围进行查询
length:[100 TO 200]
sip:["172.24.20.110" TO "172.24.20.140"]
date:{"now-6h" TO "now"}
tag:{b TO e} 搜索b到e中间的字符
count:[10 TO *] * 表示一端不限制范围
count:[1 TO 5} [ ] 表示端点数值包含在范围内,{ } 表示端点数值不包含在范围内,可以混合使用,此语句为1到5,包括1,不包括5
可以简化成以下写法:
age:>10
age:<=10
age:(>=10 AND <20)
优先级
quick^2 fox
使用^使一个词语比另一个搜索优先级更高,默认为1,可以为0~1之间的浮点数,来降低优先级
逻辑操作
AND
OR
+:搜索结果中必须包含此项
-:不能含有此项
+apache -jakarta test aaa bbb:结果中必须存在apache,不能有jakarta,剩余部分尽量都匹配到
分组
(jakarta OR apache) AND jakarta
字段分组
title:(+return +"pink panther")
host:(baidu OR qq OR google) AND host:(com OR cn)
转义特殊字符
+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /
以上字符当作值搜索的时候需要用\转义
\(1\+1\)\=2用来查询*(1+1)=2*