MobileNet v1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Abstract
MobileNets是用于移动和嵌入式视觉应用的高效模型。MobileNets是基于流线型架构,使用深度可分离卷积来构建轻量级深度神经网络。
论文介绍了两个简单的全局超参数,可以在延迟和准确度之间有效折中。这些超参数允许模型构建器根据问题的约束为其应用选择合适大小的模型。我们展示了关于资源和准确度权衡的大量实验,并且在ImageNet分类上与其它流行模型进行比较展现MobileNets的高效性能。然后我们展示了MobileNets在各种应用中的有效性,包括对象检测、细粒度分类和大规模地理定位。
Introduction
自从AlexNet通过赢得ImageNet比赛推广深度卷积神经网络以来,卷积神将网络已经在计算机视觉中普遍应用,总体趋势是制造更深层更复杂的网络来提高准确度。然而这些提高准确度的努力并不一定使网络在大小和速度方面更有效率。在许多现实世界的应用里,比如机器人、自动驾驶和增强现实,识别任务需要在计算有限的平台上及时进行。本文描述了一种高效的网络结构和两个超参数来建立很小、低延迟的模型,可以很容易的达到移动端和嵌入式视觉应用的设计要求。
Prior Work
现阶段,在建立小型高效的神经网络工作中,通常可分为两类工作:
压缩预训练模型。基于乘积量化、散列哈希、修剪、矢量量化和Huffman编码等压缩方法,此外,大量因素被提出来加速预训练网络。另一个训练小型网络的方法是蒸馏,该方法使用更大的网络来训练更小的网络,这是我们的方法的补充,还有一种叫做低比特网络。
直接训练小型模型。扁平化网络利用完全分解的卷积构建网络,并展示了全因式分解网络的潜力。独立于当前论文,因式分解网络引入了类似的因式分解卷积核拓扑连接的使用。随后,Xception网络展示了如何扩展深度可分离滤波器来战胜Inception V3网络。另一个小型网络是Squeezenet,它使用瓶颈方法来设计小型网络,其他减小的网络包括结构化变换网络和深度煎炸网络。
本文提出了一类网络结构允许模型开发者专门选择与其应用程序的资源限制(延迟、大小)想匹配的小型网络。MobileNets主要专注于优化延迟,但也会产生小型网络,许多同类论文只关注了大小但没考虑速度。MobileNets主要由深度可分离卷积构建,随后用于Inception模型来减少在前几层的计算。
MobileNet Architecture
在这一节我们首先介绍MobileNet的核心层,即深度可分离滤波器。我们然后介绍了MobileNet网络结构和两个模型缩减超参:宽度乘数和分辨率乘数。
深度可分离卷积
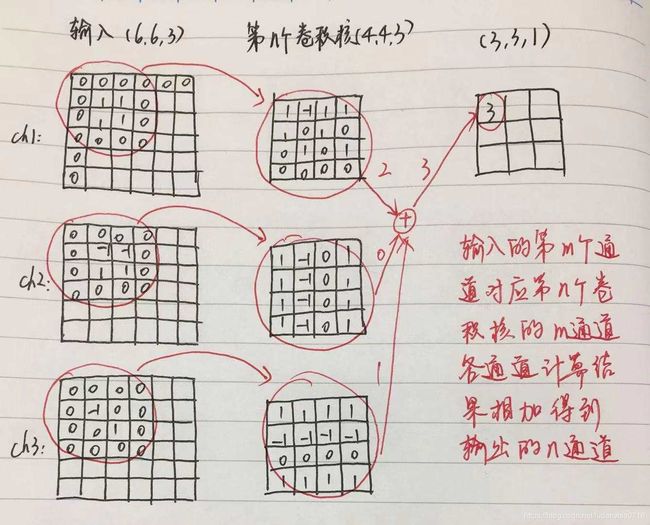
MobileNet模型基于深度可分离卷积,它是因式分解卷积的一种形式,将一个标准的卷积分解成一个深度卷积和一个1×1的逐点卷积。MobileNets中深度卷积在每一个输入通道上实现一个单独的滤波器,然后点对点卷积实现一个1×1的卷积来将深度卷积的输出结合起来。标准卷积在一步中既滤波又合并输入成一个新的输出。而深度可分离卷积将它分成了2层,一层用来滤波一层用来合并。该分解大大的减少了计算和模型体积,如下图所示。

一个标准的卷积层输入是DF×DF×M的特征映射F,输出是DG×DG×N的特征映射G,DF是一个方形输入特征映射的空间宽和高,M是输入通道数(输入深度),DG是方形输出特征映射的空间宽和高,N是输出通道数(输出深度)。标准卷积层的输入参数是卷积核K,大小是DK×DK×M×N,DK是卷积核的空间维度,M是输入通道数,N是输出通道数,输出特征映射公式如下:

标准卷积的计算复杂度是
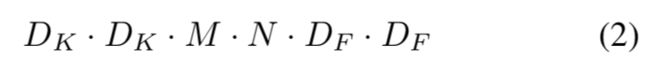
标准卷积操作根据卷积核过滤特征,并合并特征构成新的表示。深度可分离卷积由两层构成:深度卷积和逐点卷积。我们使用深度卷积对每个输入通道进行单独滤波。点卷积(1×1)用来创建对深度卷积层输出结果的线性合并。MobileNets在每一层中都使用了batchnorm和relu非线性。每个输入通道一个过滤器的深度卷积形式如下,其中K是DF×DF×M的深度卷积核,其中第m个滤波器与F的第m个通道生成G的第m个输出通道。
深度卷积的卷积公式:
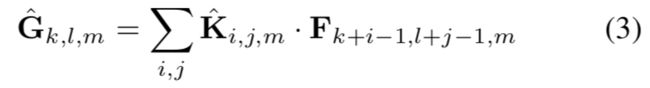
深度卷积的计算复杂度是:

与标准卷积相比深度卷积非常高效,但是它只过滤输入通道,而没有把它们合并成新的特征。因此一个额外的1×1卷积用来计算这些输出的线性合并。深度卷积和点卷积合并称为深度可分离卷积,计算开销是:

在分解为两步后,计算减少了:
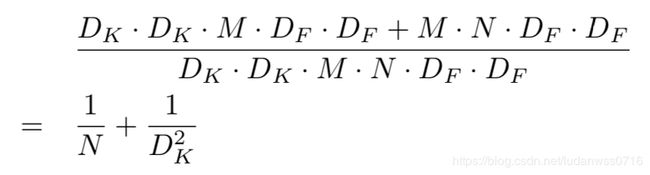
MobileNet使用一个3×3的深度可分离卷积,相比标准卷积减少了8-9倍的计算量,而准确度只减少很小一部分。

网络结构和训练
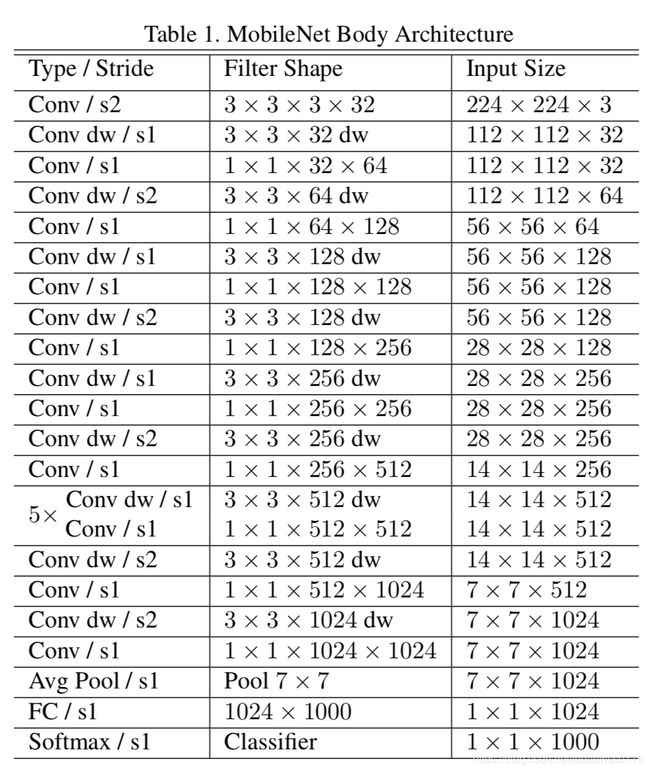
MobileNet结构建立在深度可分离卷积上,除了第一层是完全卷积,具体结构在Table1中(dw表示深度分离卷积),所有层的后面都是一个batchnorm和relu非线性,但最后的全连接层除外,它没有非线性并且输入softmax层进行分类。
Figure3对比了标准卷积核MobileNet中深度分离卷积。如果需要下采样,在第一个深度卷积中采用跨步卷积。将深度卷积和点卷积当做不同的层,MobileNet一共有28层。
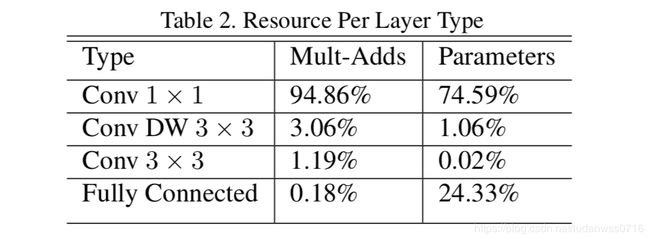
非结构化稀疏矩阵运算通常不比密集矩阵运算快,除非稀疏度很高。我们的模型结构几乎将所有的计算都放入密集的1×1卷积中,这可以通过高度优化的通用矩阵乘法(GEMM)函数实现。通常,卷积由GEMM实现,但是需要在内存中进行称为im2col的初始重排序来将其映射到GEMM。1×1卷积不需要在内存中重排序,并且可以直接用GEMM实现,GEMM是最优化的数值线性代数算法之一。如Table2所示,MobileNet在1×1卷积中耗时占比95%,参数占75%,几乎所有的附加参数都是在全连接层中。
MobileNet模型在Tensorflow中使用RMSprop进行训练,使用类似Inception V3的异步梯度下降算法。但是,与训练大型网络相比,我们较少使用正则和数据增强技术,因为小模型不易过拟合。在训练MobileNets时我们不使用side heads or label smoothing,在深度滤波器上放置很少或没有重量衰减(L2正则化)很重要,因为它们的参数很少。

宽度因子
虽然基础的MobileNet结构已经很小且低延迟,但是特定用例或应用程序很多时候可能要求模型更小更快。为了构造这些更小的模型,我们引入了一个很简单的参数α,即宽度乘数。α的作用是在每层均匀的使网络变窄,对于给定的层和α,输入通道M的数量变为αM,输出通道由N变成αN。
具有宽度乘数α的深度可分离卷积网络的计算开销是:

其中α∈(0,1],一般设置为1,0.75,0.5和0.25,α=1时是基准MobileNet,α<1时是减小的MobileNet。宽度乘数具有降低计算开销和参数数量的效果,大约能减少α2倍。宽度乘数可以应用于任何模型结构以定义一个新的小模型,具有适合的精确度、延迟和大小。
分辨率乘数
第二个减少神经网络计算开销的超参是分辨率乘数ρ。我们对输入图片做分辨率处理,每层的内部表示随后被同样的乘数减小。在这步之后的计算开销如下:
![]()
图3展示了在架构缩减方法被依次的作用于层之后该层的计算和参数量。

Experiments
模型选择
Table 4:使用深度可分离卷积与完全卷积相比,ImageNet的准确度降低了1%,而mult-adds和参数大量减少。
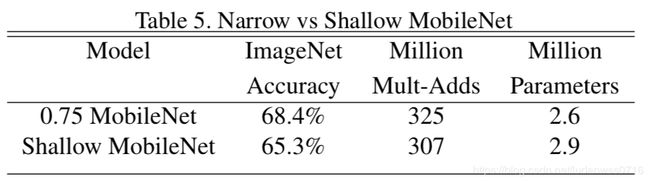
Table 5:删除了Table 1中特征尺寸为14×14×512的5层可分离滤波器,在相似的计算和参数数量下,窄模型比浅模型的性能好3%.

模型缩减超参
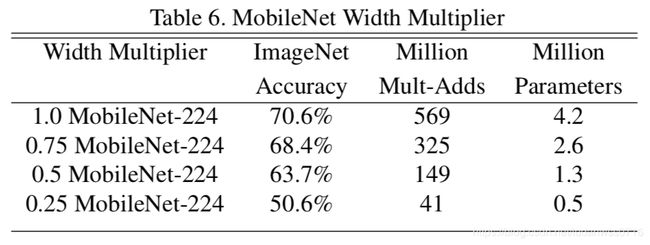
Table 6:精度平滑下降,直到网络在α=0.25时太小。
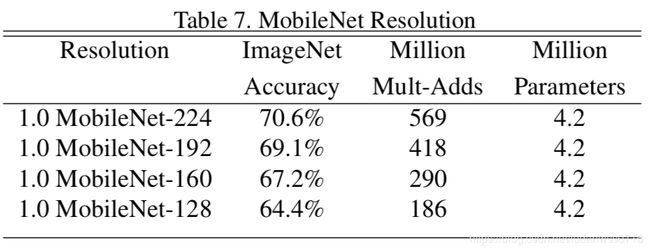
Table 7:降低输入分辨率,分辨率下降时精度降低。
交叉验证计算量对精度影响
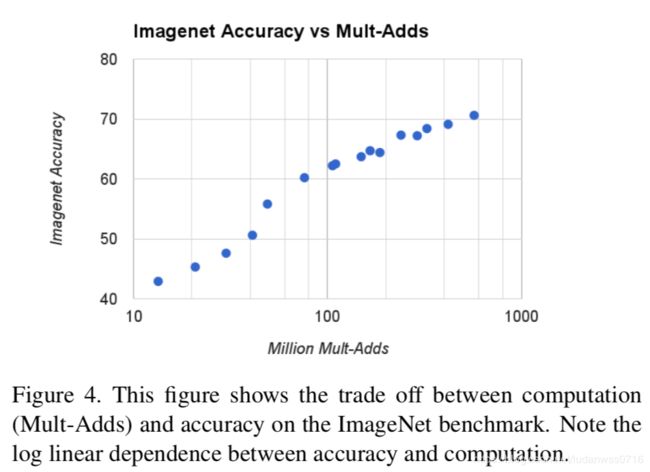
图4:ImageNet上16个模型性能,当α=0.25时模型非常小,结果是对数线性跳跃。
交叉验证参数量对精度影响
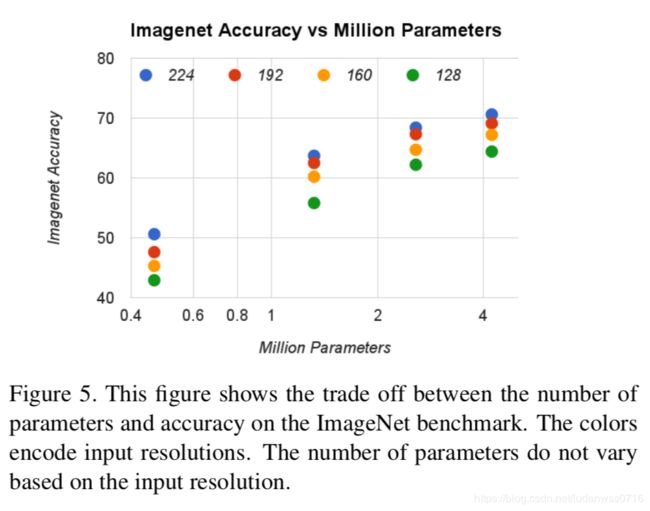
图5:ImageNet上16个模型的精度与参数数量之间的平衡。
与其他先进模型相比
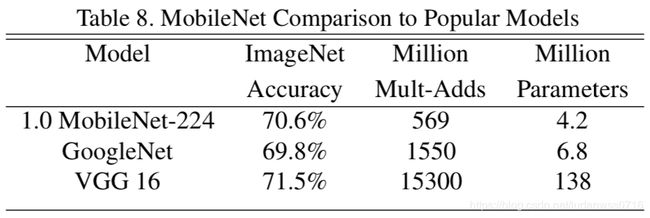
Table 8:对比完整的MobileNet和原始GoogleNet网络、VGG16,几乎一样精确,同事缩小了32倍,计算密集度降低了27倍。它比GoogleNet更精确,同时体积更小,计算量减小2.5倍以上。
Table 9:对比了缩小的MobileNet与AlexNet和Squeezenet。

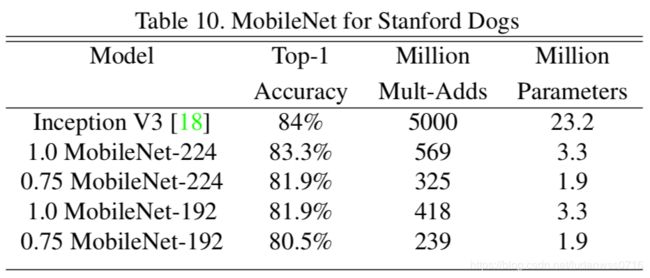
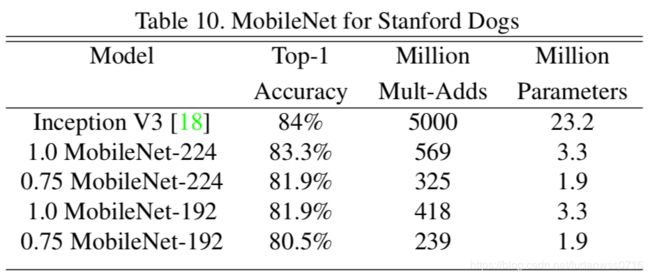
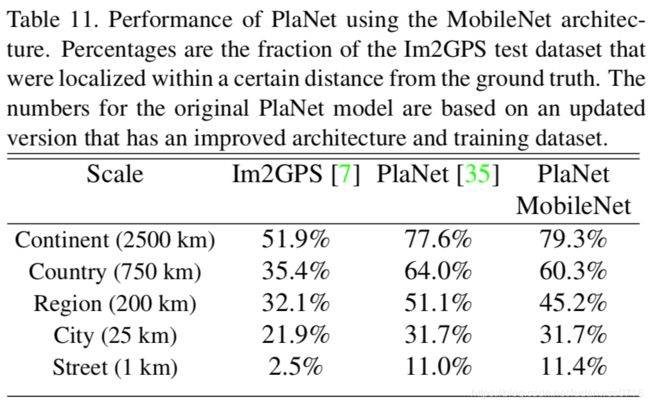
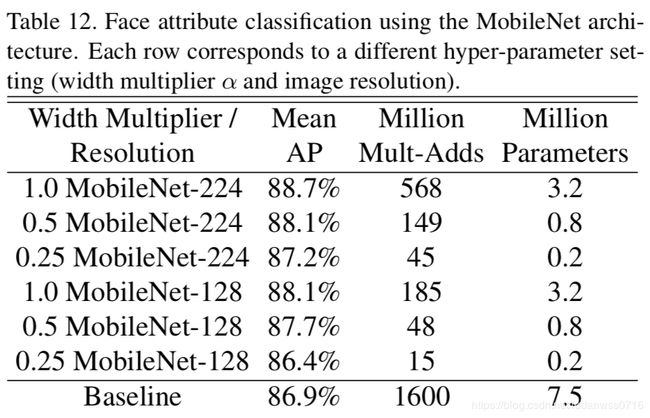
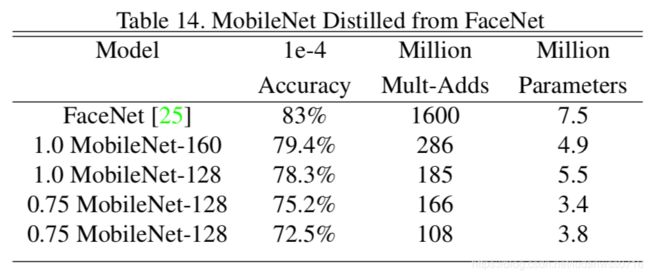
其他应用场景:Table10(细粒度识别) Table11(大规模定位) Table12(脸部属性) Table13(目标识别) Table14(人脸识别)
在Stanford Dogs数据集上训练了MobileNet的细粒度识别,如Table 10所示。