tensorflow
tensorflow下载以及编译:
1下载TensorFlow ,使用 git clone --recursive https://github.com/tensorflow/tensorflow
2.下载bazel工具(mac下载installer-darwin、linux用installer-linux)
3. 进入tensorflow的根目录
3.1 执行./configure 根据提示配置一下环境变量这个官网上有类似的 应该能看到 \
要GPU的话要下载nvidia驱动的 尽量装最新版的驱动吧 还有cudnn version为5以上的 这些在官网都有提及的
3.2 有显卡的执行 " bazel build --config=opt --config=cuda //tensorflow:libtensorflow_cc.so "
没显卡的 " --config=cuda " 就不要加了
如果是c版本的tensorflow, 把" libtensorflow_cc " 改成 " libtensorflow "
这句命令其实是bazel的用法 具体要生成哪个可以 " vim $(TF_ROOT_PATH)/tensorflow/BUILD " 查看
编译需要挺久的 大概大半个小时吧我记得,这里编译要有sudo权限,否则编译过程会报错。
sudo bazel build --config=opt //tensorflow:libtensorflow_cc.so
4. 一般是不报错的 如果报错要么是依赖项没有 到时候一个个装就好了 也有个错误是说 protoc 版本太低 这时候更新一下protoc就好了
5. bazel build成功后会有提示的 然后拷贝一下头文件 (这里应该没落下, 如果有找不到的话还得再找找吧- -)
我tensorflow clone路径是, /Users/zhoumeixu/Documents,后面在cmakelist.txt文件中注意路径。
===========================================================================================================================================================================================================================================================================
最近在研究如何打通tensorflow线下 python 的脚本训练建模, 利用freeze_graph工具输出.pb图文件,之后再线上生产环境用C++代码直接调用预先训练好的模型完成预测的工作,而不需要用自己写的Inference的函数。因为目前tensorflow提供的C++的API比较少,所以参考了几篇已有的日志,踩了不少坑一并记录下来。写了一个简单的ANN模型对Iris数据集分类的Demo。
梳理过后的流程如下:
1. python脚本中定义自己的模型,训练完成后将tensorflow graph定义导出为protobuf的二进制文件或文本文件(一个仅有tensor定义但不包含权重参数的文件);
2. python脚本训练过程保存模型参数文件 *.ckpt。
3. 调用tensorflow自带的freeze_graph.py 小工具, 输入为格式*.pb或*.pbtxt的protobuf文件和*.ckpt的参数文件,输出为一个新的同时包含图定义和参数的*.pb文件;这个步骤的作用是把checkpoint .ckpt文件中的参数转化为常量const operator后和之前的tensor定义绑定在一起。
4. 在C++中新建Session,只需要读取一个绑定后的模型文件.pb, 进行预测,利用Session->Run()获得输出的tensor的值就okay;
5. 编译和运行,这时有两个选择:
a) 一种是在tensorflow源代码的子目录下新建自己项目的目录和代码,然后用bazel来编译成一个很大的100多MB的二进制文件,这个方法的缺点在于无法把预测模块集成在自己的代码系统和编译环境如cmake, bcloud中,迁移性和实用性不强;参考: (https://medium.com/jim-fleming/loading-a-tensorflow-graph-with-the-c-api-4caaff88463f) 如果打不开貌似有中文翻译版的博客
b) 另一种是自己把tensorflow源代码编译成一个.so文件,然后在自己的C++代码环境中依赖这个文件完成编译。C的API依赖libtensorflow.so,C++的API依赖libtensorflow_cc.so
运行成功后
下面通过具体的例子写了一个简单的ANN预测的demo,应该别的模型也可以参考或者拓展C++代码中的基类。测试环境:MacOS, 需要依赖安装:tensorflow, bazel, protobuf , eigen(一种矩阵运算的库);
配置环境
系统安装 HomeBrew, Bazel, Eigen
# Mac下安装包管理工具homebrew
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
# 安装Bazel, Google 的一个编译工具
brew install bazel
# 安装Protobuf, 参考 http://blog.csdn.net/wwq_1111/article/details/50215645
git clone https://github.com/google/protobuf.git
brew install automake libtool
./autogen.sh
./configure
make check
make && make install
# 安装 Eigen, 用于矩阵运算
brew install eigen
下载编译tensorflow源码
# 从github下载tensorflow源代码
git clone --recursive https://github.com/tensorflow/tensorflow
## 进入根目录后编译
# 编译生成.so文件, 编译C++ API的库 (建议)
bazel build //tensorflow:libtensorflow_cc.so
# 也可以选择,编译C API的库
bazel build //tensorflow:libtensorflow.so
在等待30多分钟后, 如果编译成功,在tensorflow根目录下出现 bazel-bin, bazel-genfiles 等文件夹, 按顺序执行以下命令将对应的libtensorflow_cc.so文件和其他文件拷贝进入 /usr/local/lib/ 目录
mkdir /usr/local/include/tf
cp -r bazel-genfiles/ /usr/local/include/tf/
cp -r tensorflow /usr/local/include/tf/
cp -r third_party /usr/local/include/tf/
cp -r bazel-bin/tensorflow/libtensorflow_cc.so /usr/local/lib/
这一步完成后,我们就准备好了libtensorflow_cc.so文件等,后面在自己的C++编译环境和代码目录下编译时链接这些库即可。
==================================================================================================================================================================================
TensorFlow有三种类型的起始节点:constant(常量)、placeholder(占位符)、Variable(变量)。
1.1常量:
TensorFlow的常量节点是通过constant方法创建,其是Computational Graph中的起始节点,在图中以一个圆点表示,如图 32所示。
1.2占位符
TensorFlow的placeholder节点是由placeholder方法创建,其也是一种常量,但是由用户在调用run方法是传递的,也可以将placeholder理解为一种形参。即其不像constant那样直接可以使用,需要用户传递常数值。
1.3变量
TensorFlow的Variable节点是通过Variable方法创建,并且需要传递初始值。常量在执行过程中无法修改值,变量可以在执行过程修改其值。但是TensorFlow的变量在创建之后需要再进行手动初始化操作,而TensorFlow常量在创建时就已进行了初始化,无需再进行手动初始化。
如下示例,创建两个变量,分别初始化为0.3和-0.3,然后传入一个向量值,最后计算出一个新的向量:
===============================》》》》》》》》》》》
===========================================>>>>>>>>>>>>>>>>>>>>>>>
===============================================》》》》》》》》》》》》》》》》》》》
1,Computational graph 是由一系列边(Tensor)和节点(operation)组成的数据流图。每个节点都是一种操作,其有0个或多个Tensor作为输入边,且每个节点都会产生0个或多个Tensor作为输出边。即节点是将多条输入边作为操作的数据,然后通过操作产生新的数据。可以将这种操作理解为模型,或一个函数,如加减乘除等操作。
简单地说,可以将Computational graph理解为UML的活动图,活动图和Computational graph都是一种动态图形。TensorFlow的节点(操作)类似活动图的节点(动作),TensorFlow每个节点都有输入(Tensor),可以将用户创建的起始Tensor看做是活动图的起始节点,而TensorFlow最终产生的Tensor看做是活动图的终止节点
2, TensorFlow通过一个对象(Session)来管理Computational graph 节点动态变换。由于Tensor是一种数据结构,为了获取Tensor存储的数据,需要手动调用Session对象的run方法获得。
=======================----------------------------===================================
TensorFlow框架(1)之Computational Graph详解
1. Getting Start
1.1 import
TensorFlow应用程序需要引入编程架包,才能访问TensorFlow的类、方法和符号。如下所示的方法:
| import tensorflow as tf |
2. Tensor
TensorFlow用Tensor这种数据结构来表示所有的数据。可以把一个Tensor想象成一个n维的数组或列表。Tensor有一个静态的类型和动态的维数。Tensor可以在图中的节点之间流通。
2.1 秩(Rank)
Tensor对象由原始数据组成的多维的数组,Tensor的rank(秩)其实是表示数组的维数,如下所示的tensor例子:
| Rank |
数学实例 |
Python 例子 |
| 0 |
常量 (只有大小) |
s = 483 |
| 1 |
向量(大小和方向) |
v = [1.1, 2.2, 3.3] |
| 2 |
矩阵(数据表) |
m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 |
3阶张量 (数据立体) |
t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
| n |
n阶 (自己想想看) |
… |
2.2 形状(Shape)
TensorFlow为了描述Tensor每一维的长度,相当于描述每一维数组的长度,所以定义了Shape概念。其可以描述Tensor的维数,又可以描述每一维的长度。
| Rank |
Shape |
Dimension number |
Example |
| 0 |
[] |
0-D |
一个常量. |
| 1 |
[D0] |
1-D |
[5]:表示一个向量有5个元素 |
| 2 |
[D0, D1] |
2-D |
[3, 4]:表示一个矩阵,共有3*4个元素 |
| 3 |
[D0, D1, D2] |
3-D |
[2, 4, 3]:总共有2*4*3个元素 |
| n |
[D0, D1, D2,… DN-1] |
n-D |
…. |
2.3 类型(Data type)
除了维度,Tensor有一个数据类型属性,你可以为一个张量指定下列数据类型中的任意一个类型,但是一个Tensor所有元素的类型必须相同。
| 数据类型 |
Python 类型 |
描述 |
| DT_FLOAT |
tf.float32 |
32 位浮点数. |
| DT_DOUBLE |
tf.float64 |
64 位浮点数. |
| DT_INT64 |
tf.int64 |
64 位有符号整型. |
| DT_INT32 |
tf.int32 |
32 位有符号整型. |
| DT_INT16 |
tf.int16 |
16 位有符号整型. |
| DT_INT8 |
tf.int8 |
8 位有符号整型. |
| DT_UINT8 |
tf.uint8 |
8 位无符号整型. |
| DT_STRING |
tf.string |
可变长度的字节数组.每一个张量元素都是一个字节数组. |
| DT_BOOL |
tf.bool |
布尔型. |
| DT_COMPLEX64 |
tf.complex64 |
由两个32位浮点数组成的复数:实数和虚数. |
| DT_QINT32 |
tf.qint32 |
用于量化Ops的32位有符号整型. |
| DT_QINT8 |
tf.qint8 |
用于量化Ops的8位有符号整型. |
| DT_QUINT8 |
tf.quint8 |
用于量化Ops的8位无符号整型. |
3. Computational graph
3.1 定义
Computational graph 是由一系列边(Tensor)和节点(operation)组成的数据流图。每个节点都是一种操作,其有0个或多个Tensor作为输入边,且每个节点都会产生0个或多个Tensor作为输出边。即节点是将多条输入边作为操作的数据,然后通过操作产生新的数据。可以将这种操作理解为模型,或一个函数,如加减乘除等操作。
简单地说,可以将Computational graph理解为UML的活动图,活动图和Computational graph都是一种动态图形。TensorFlow的节点(操作)类似活动图的节点(动作),TensorFlow每个节点都有输入(Tensor),可以将用户创建的起始Tensor看做是活动图的起始节点,而TensorFlow最终产生的Tensor看做是活动图的终止节点,如图 31所示。
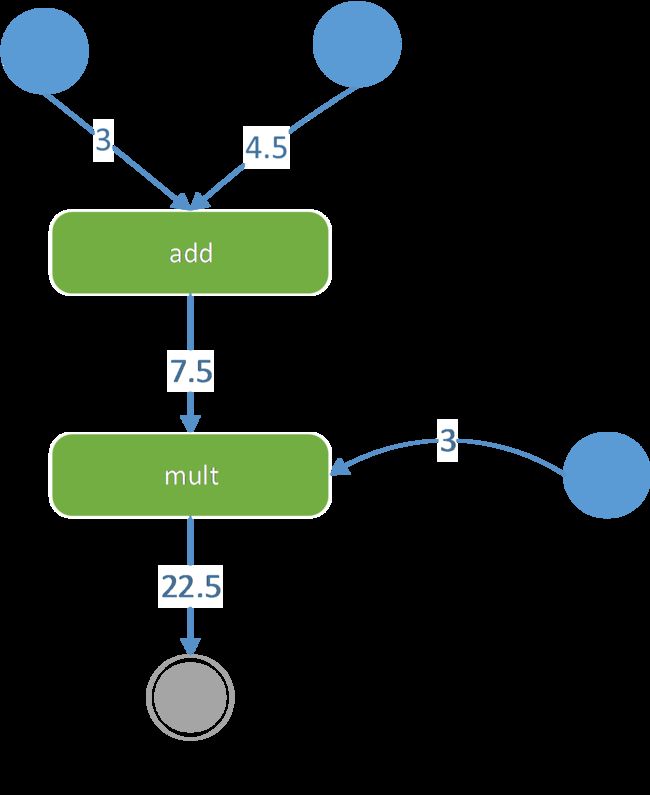
图 31
图 31所示,常量3和常量4.5两个起始Tensor通过add操作后产生了一个新Tensor(值7.5);接着新Tensor(值7.5)和常量3经multi操作后产生一个新Tensor(值22.5),因为22.5是TensorFlow最后产生的Tensor,所以其是终止节点。
3.2 Session
TensorFlow通过一个对象(Session)来管理Computational graph 节点动态变换。由于Tensor是一种数据结构,为了获取Tensor存储的数据,需要手动调用Session对象的run方法获得。
实现一个TensorFlow应用程序,用户需要进行两个步骤:
1) 建立计算图(Building the computational graph)
Computational Graph建立其实是建立节点和边的一些依赖关系,这个过程是建立一种静态结构。
2) 执行计算图(Running the computational graph)
Computational Graph执行其实就是调用session.run()方法。由于Computational Graph是有边和节点组成,所以可以向run方法传递的两种参数:
-
边(Tensor):若传递的是Tensor对象,则是获取Tensor对象的数据;
-
节点:若传递的是节点,则会先获取节点返回的Tensor对象,然后再获取Tensor对象的数据。
综上所述执行Computational Graph其实是获取Tensor的数据。在执行Tensor对象数据时,会根据节点的依赖关系进行计算,直至初始节点。
如下建立两个TensorFlow节点,节点的类型是constant,然后通过add操作后产生一个新节点,如下所示:
| ##1.建立computational graph node1 = tf.constant(3., tf.float32) node2 = tf.constant(4.5) tensor = tf.add(node1, node2)
print(node1) print(node2)
##2.执行computational graph session = tf.Session() print(session.run(node1)) print(session.run(node2)) print(session.run(tensor)) |
| 输出: Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32) 3.0 4.5 7.5 |
图 32
注意:
-
在执行computational graph之前,TensorFlow节点是一种静态结构,所以输出的并不是3.0和4.0,而是tensor对象;
-
在执行computational graph之后,才输出了节点的值,即为了让某个节点从初始节点开始变换,需要通过Session对象的run方法手动变换。
3.3 InteractiveSession
文档中的 Python 示例使用一个会话 Session 来 启动图, 并调用 Session.run() 方法执行操作.为了便于使用诸如 IPython 之类的 Python 交互环境, 可以使用 InteractiveSession 代替 Session 类, 使用 Tensor.eval() 和 Operation.run() 方法代替 Session.run(). 这样可以避免使用一个变量来持有会话.
| # 进入一个交互式 TensorFlow 会话. import tensorflow as tf sess = tf.InteractiveSession()
x = tf.Variable([1.0, 2.0]) a = tf.constant([3.0, 3.0])
# 使用初始化器 initializer op 的 run() 方法初始化 'x' x.initializer.run()
# 增加一个减法 sub op, 从 'x' 减去 'a'. 运行减法 op, 输出结果 sub = tf.sub(x, a) print sub.eval() # ==> [-2. -1.] |
4. 起始节点
目前了解的,TensorFlow有三种类型的起始节点:constant(常量)、placeholder(占位符)、Variable(变量)。
4.1 常量 (constant)
TensorFlow的常量节点是通过constant方法创建,其是Computational Graph中的起始节点,在图中以一个圆点表示,如图 32所示。
如下述程序中所示,直接创建,但创建的节点不会开始执行,需要由Session对象的run方法开始启动。
| tensor1 = tf.constant(3., tf.float32) print(tensor1)
tensor2 = tf.constant([1, 2, 3, 4, 5, 6, 7]) print(tensor2)
tensor3 = tf.constant(-1.0, shape=[2, 3]) print(tensor3)
session = tf.Session() print(session.run(tensor1)) print(session.run(tensor2)) print(session.run(tensor3)) |
| 输出: Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(7,), dtype=int32) Tensor("Const_2:0", shape=(2, 3), dtype=float32) 3.0 [1 2 3 4 5 6 7] [[-1. -1. -1.] [-1. -1. -1.]] |
4.2 占位符 (placeholder)
TensorFlow的placeholder节点是由placeholder方法创建,其也是一种常量,但是由用户在调用run方法是传递的,也可以将placeholder理解为一种形参。即其不像constant那样直接可以使用,需要用户传递常数值。
如下所示在执行node3:
| import tensorflow as tf
node1 = tf.placeholder(tf.float32) node2 = tf.placeholder(tf.float32) tensor = tf.add(node1, node2)
print(node1) print(node2)
session = tf.Session() print(session.run(tensor, {node1:3,node2:4} )) |
| 输出: Tensor("Placeholder:0", dtype=float32) Tensor("Placeholder_1:0", dtype=float32) 7.0 |
注意:
由于在执行node3节点时,需要node1和node2作为输入节点,所以此时需要传递"实参",即3和4.
图 41
4.3 变量 (Variable)
TensorFlow的Variable节点是通过Variable方法创建,并且需要传递初始值。常量在执行过程中无法修改值,变量可以在执行过程修改其值。但是TensorFlow的变量在创建之后需要再进行手动初始化操作,而TensorFlow常量在创建时就已进行了初始化,无需再进行手动初始化。
如下示例,创建两个变量,分别初始化为0.3和-0.3,然后传入一个向量值,最后计算出一个新的向量:
| from __future__ import print_function import tensorflow as tf
w = tf.Variable([.3], tf.float32) b = tf.Variable([-.3], tf.float32) x = tf.placeholder(tf.float32)
linear = w * x + b
session = tf.Session() init = tf.global_variables_initializer() session.run(init)
print(session.run(linear, {x: [1, 2, 3, 4]})) |
| 输出: [ 0. 0.30000001 0.60000002 0.90000004] |

图 42
从W展开细节看,变量其实只是一个命名空间,其内部由一系列的节点和边组成。同时有一个常量节点,即初始值节点。
5. 模型评估
模型评估是指比较期望值和模型产生值之间的差异,若差异越大,则性能越差;差异越小,性能越好。模型评估有很多种方法,如均分误差或交差熵。
如下以常用的"均分误差"法举例说明,其等式为:

Y为期望向量,X为输入向量,f(X)为计算向量,如下所示:
| from __future__ import print_function import tensorflow as tf #1. 构建计算流图 w = tf.Variable([.3], tf.float32) b = tf.Variable([-.3], tf.float32) x = tf.placeholder(tf.float32) y = tf.placeholder(tf.float32) #期望向量 linear_model = w * x + b
squared_deltas = tf.square(linear_model - y) #对两个向量的每个元素取差并平方,最后得出一个新的向量 loss = tf.reduce_sum(squared_deltas) #对向量取总和
#2. 执行计算流图 session = tf.Session() init = tf.global_variables_initializer() session.run(init)
print(session.run(loss, {x: [1, 2, 3, 4], y: [0, -1, -2, -3]})) |
| 输出: 23.66 |
注意:
loss的值是依赖W、B和Y三个向量的值,所以计算loss Tensor会根据依赖关系获取W、B和Y三个Tensor的值,其计算流程图如图 51所示:

图 51
6. 优化
优化是指减少期望值与模型产生值之间的差异,即减少均分误差或交差熵的计算结果,如减少上述的loss变量值。
6.1 手动优化
我们可以通过修改上述的w和b的变量值,来手动优化上述的模型。由于TensorFlow的变量是通过tf.Variable方法创建,而重新赋值是通过tf.assign方法来实现。注意修改变量的动作需要执行Session.run方法来开始执行。
比如可以修改w=-1,b=1参数来优化模型,如下
| from __future__ import print_function import tensorflow as tf
w = tf.Variable([.3], tf.float32) b = tf.Variable([-.3], tf.float32) x = tf.placeholder(tf.float32) y = tf.placeholder(tf.float32 ") linear_model = w * x + b
squared_deltas = tf.square(linear_model - y) loss = tf.reduce_sum(squared_deltas)
session = tf.Session() init = tf.global_variables_initializer() session.run(init)
#1.变量w和b初始值为3和-3时,计算loss值 print(session.run(loss, {x: [1, 2, 3, 4], y: [0, -1, -2, -3]}))
#2.重置变量w和b值为-1和1时,再计算loss值 fixw = tf.assign(w,[-1.]) fixb = tf.assign(b,[1.]) session.run(fixw) session.run(fixb) print(session.run(loss, {x:[1,2,3,4],y:[0,-1,-2,-3]})) |
| 输出: 23.66 0.0 |
注意:
loss的值是依赖W、B和Y三个向量的值来计算,即每次计算loss都需要上述三个变量的值进行计算。由于通过调用Session.run()方法来执行某个节点(Computational graph的节点为操作)时,会自动根据节点前后依赖关系,自动从初始节点开始计算到该节点。在第一次执行session.run(loss)时,W和B的值是3和-3;第二次执行session.run(loss)时,W和B的值被修改为-1和1后。所以session.run(loss)时会自动根据W和B的不同进行计算。

图 61
6.2 自动优化
上述通过手动调整变量w和b的值来改善模型的执行性能,虽然也行的通,但是非常单调且工作量太大。所以TensorFlow提供一些优化器(optimizers)来提高用户的工作效率,可以自动完成优化,即可以自动更新相关变量的值。
如下所示,以最简单的优化器gradient descent为例,其可以根据执行loss值逐渐修改每个变量值,:
| import numpy as np import tensorflow as tf w = tf.Variable([.3], tf.float32) b = tf.Variable([-.3], tf.float32) x = tf.placeholder(tf.float32) linear_model = w * x + b y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y) loss = tf.reduce_sum(squared_deltas)
#1. optimizer optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss)
#2. training loop init = tf.global_variables_initializer() session = tf.Session() session.run(init)
for i in range(1000): session.run(train, {x:[1,2,3,4], y:[0, -1, -2, -3]})
#3. evaluate training accuracy curr_w, curr_b, curr_loss = session.run([w,b,loss], {x:[1, 2, 3, 4], y:[0, -1, -2, -3]}) print("w:%s b:%s loss:%s"%(curr_w,curr_b,curr_loss)) |
| 输出: w:[-0.9999969] b:[ 0.99999082] loss:5.69997e-11 |
注意:
1) optimizer:创建一个优化器,并指定优化的方向;优化器的优化过程是:对于方程中的权值(w)和偏置(b)对跟进loss值进行调整,v是泛指w或b参数,则每趟优化过程都会按如下方程更改w或b的值:
![]()
则dV是参数调整数幅度,如若v是权值w,则
2) training:执行优化器,在执行过程中会不断更新涉及的变量,即会更新W和B两个Tensor值;
3) evaluate:W和B在优化前就有初始值;在优化后会更新两个值;所以再执行loss时,会根据W、B和Y三个Tensor值来计算。
如图 62所示是产生的Computational graph图变换:
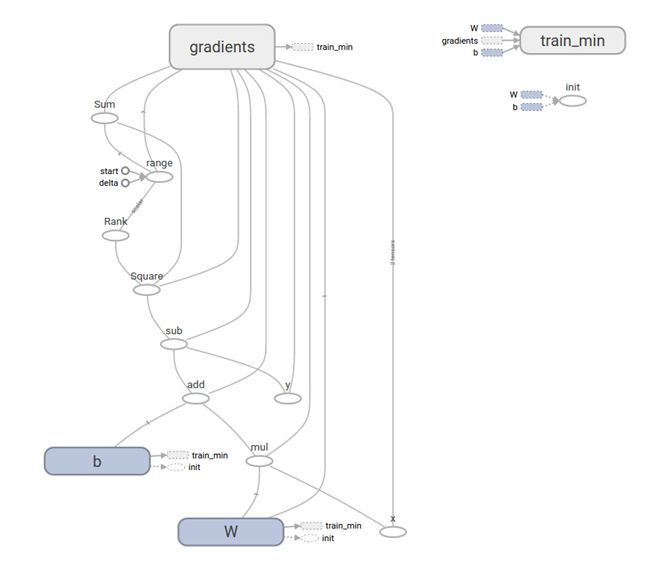
图 62
图中带有箭头的边缘是指依赖,如节点b有一个指向tain_min节点,表明b的值依赖tain_min节点。
=======================-----------------------------===================================
tensorflow中的节点(Op)
在上面创建图中,每一个节点代表着一个操作(operation,Op),一般用来表示施加的的数学运算,也可以表示数据输入的起点以及输出的终点,或者是读取/写入持久变量(persistent veriable)的终点,Op也可用于状态初始化的任务.tensorflow中的其他数学运算tf.mul(),tf.sub,tf.div,tf.mod分别是乘法,减法,除法,取模. tf.div()执行的除法取决于提供的数据类型,如果要使用浮点数除法,可以使用:tf.truediv()
Tensorflow中还有很多操作函数,与之相关的代码都在tensorflow/python/ops/目录下的文件中
tensorflow中的张量(tensor):
在tensorflow中所有的数据都是以张量的形式来表示的,张量可以理解为多维数组,零阶张量表示标量(一个数),一阶张量就是一个向量类似一维数组,二阶张量相当于二维数组.但是张量在tensorflow中并不是直接采用数组的形式,在tensorflow中张量不用来保存结果,它是对计算结果的引用,保存的是得到计算结果的计算过程.
计算图中的边包含这两种关系:数据依赖和控制依赖.(不需要对计算图中的边进行定义,因为在tensorflow中创建节点是已包含了相应的Op完成计算所需的全部输入,tensorflow会自动绘制必要的连接)
实线的边代表着数据依赖.标识连接的两个节点之间有tensor的流动(传递)
虚线的边代表着控制依赖.用于控制操作的运行,确保happens-before关系,连接的节点之间间没有tensor的传递,但是源节点必须在目的节点执行前完成执行.
========================================================
【转载】Tensorflow C++ 编译和调用图模型
http://blog.csdn.net/rockingdingo/article/details/75452711
Github下载完整代码
tensorflow freeze_graph.py 工具
简介
最近在研究如何打通tensorflow线下 python 的脚本训练建模, 利用freeze_graph工具输出.pb图文件,之后再线上生产环境用C++代码直接调用预先训练好的模型完成预测的工作,而不需要用自己写的Inference的函数。因为目前tensorflow提供的C++的API比较少,所以参考了几篇已有的日志,踩了不少坑一并记录下来。写了一个简单的ANN模型对Iris数据集分类的Demo。
梳理过后的流程如下:
1. python脚本中定义自己的模型,训练完成后将tensorflow graph定义导出为protobuf的二进制文件或文本文件(一个仅有tensor定义但不包含权重参数的文件);
2. python脚本训练过程保存模型参数文件 *.ckpt。
3. 调用tensorflow自带的freeze_graph.py 小工具, 输入为格式*.pb或*.pbtxt的protobuf文件和*.ckpt的参数文件,输出为一个新的同时包含图定义和参数的*.pb文件;这个步骤的作用是把checkpoint .ckpt文件中的参数转化为常量const operator后和之前的tensor定义绑定在一起。
4. 在C++中新建Session,只需要读取一个绑定后的模型文件.pb, 进行预测,利用Session->Run()获得输出的tensor的值就okay;
5. 编译和运行,这时有两个选择:
a) 一种是在tensorflow源代码的子目录下新建自己项目的目录和代码,然后用bazel来编译成一个很大的100多MB的二进制文件,这个方法的缺点在于无法把预测模块集成在自己的代码系统和编译环境如cmake, bcloud中,迁移性和实用性不强;参考: (https://medium.com/jim-fleming/loading-a-tensorflow-graph-with-the-c-api-4caaff88463f) 如果打不开貌似有中文翻译版的博客
b) 另一种是自己把tensorflow源代码编译成一个.so文件,然后在自己的C++代码环境中依赖这个文件完成编译。C的API依赖libtensorflow.so,C++的API依赖libtensorflow_cc.so
运行成功后
下面通过具体的例子写了一个简单的ANN预测的demo,应该别的模型也可以参考或者拓展C++代码中的基类。测试环境:MacOS, 需要依赖安装:tensorflow, bazel, protobuf , eigen(一种矩阵运算的库);
配置环境
系统安装 HomeBrew, Bazel, Eigen
[python] view plain copy
# Mac下安装包管理工具homebrew
ruby -e"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
# 安装Bazel, Google 的一个编译工具
brew install bazel
# 安装Protobuf, 参考 http://blog.csdn.net/wwq_1111/article/details/50215645
git clone https://github.com/google/protobuf.git
brew install automake libtool
./autogen.sh
./configure
make check
make && make install
# 安装 Eigen, 用于矩阵运算
brew install eigen
下载编译tensorflow源码
[python] view plain copy
# 从github下载tensorflow源代码
git clone --recursive https://github.com/tensorflow/tensorflow
## 进入根目录后编译
# 编译生成.so文件, 编译C++ API的库 (建议)
bazel build //tensorflow:libtensorflow_cc.so
# 也可以选择,编译C API的库
bazel build //tensorflow:libtensorflow.so
在等待30多分钟后, 如果编译成功,在tensorflow根目录下出现 bazel-bin, bazel-genfiles 等文件夹, 按顺序执行以下命令将对应的libtensorflow_cc.so文件和其他文件拷贝进入 /usr/local/lib/ 目录
[python] view plain copy
mkdir /usr/local/include/tf
cp -r bazel-genfiles/ /usr/local/include/tf/
cp -r tensorflow /usr/local/include/tf/
cp -r third_party /usr/local/include/tf/
cp -r bazel-bin/tensorflow/libtensorflow_cc.so /usr/local/lib/
这一步完成后,我们就准备好了libtensorflow_cc.so文件等,后面在自己的C++编译环境和代码目录下编译时链接这些库即可。
1. Python线下定义模型和训练
我们写了一个简单的脚本,来训练一个包含1个隐含层的ANN模型来对Iris数据集分类,模型每层节点数:[5, 64, 3],具体脚本参考项目:
https://github.com/rockingdingo/tensorflow-tutorial
1.1 定义Graph中输入和输出tensor名称
为了方便我们在调用C++ API时,能够准确根据Tensor的名称取出对应的结果,在python脚本训练时就要先定义好每个tensor的tensor_name。 如果tensor包含命名空间namespace的如"namespace_A/tensor_A" 需要用完整的名称。(Tips: 对于不清楚tensorname具体是什么的,可以在输出的 .pbtxt文件中找对应的定义); 这个例子中,我们定义以下3个tensor的tensorname
[python] view plain copy
class TensorNameConfig(object):
input_tensor ="inputs"
target_tensor ="target"
output_tensor ="output_node"
# To Do
1.2 输出graph的定义文件*.pb和参数文件 *.ckpt
我们要在训练的脚本nn_model.py中加入两处代码:第一处是将tensorflow的graph_def保存成./models/目录下一个文件nn_model.pbtxt, 里面包含有图中各个tensor的定义名称等信息。 第二处是在训练代码中加入保存参数文件的代码,将训练好的ANN模型的权重Weight和Bias同时保存到./ckpt目录下的*.ckpt, *.meta等文件。最后执行 python nn_model.py 就可以完成训练过程
[python] view plain copy
# 保存图模型
tf.train.write_graph(session.graph_def, FLAGS.model_dir,"nn_model.pbtxt", as_text=True)
# 保存 Checkpoint
checkpoint_path = os.path.join(FLAGS.train_dir,"nn_model.ckpt")
model.saver.save(session, checkpoint_path)
# 执行命令完成训练过程
python nn_model.py
1.3 使用freeze_graph.py小工具整合模型freeze_graph
最后利用tensorflow自带的 freeze_graph.py小工具把.ckpt文件中的参数固定在graph内,输出nn_model_frozen.pb
[python] view plain copy
# 运行freeze_graph.py 小工具
# freeze the graph and the weights
python freeze_graph.py --input_graph=../model/nn_model.pbtxt --input_checkpoint=../ckpt/nn_model.ckpt --output_graph=../model/nn_model_frozen.pb --output_node_names=output_node
# 或者执行
sh build.sh
# 成功标志:
# Converted 2 variables to const ops.
# 9 ops in the final graph.
脚本中的参数解释:
--input_graph: 模型的图的定义文件nn_model.pb (不包含权重);
--input_checkpoint: 模型的参数文件nn_model.ckpt;
--output_graph: 绑定后包含参数的图模型文件 nn_model_frozen.pb;
-- output_node_names: 输出待计算的tensor名字【重要】;
发现tensorflow不同版本下运行freeze_graph.py 脚本时可能遇到的Bug挺多的,列举一下:
[python] view plain copy
# Bug1: google.protobuf.text_format.ParseError: 2:1 : Message type "tensorflow.GraphDef" has no field named "J".
# 原因: tf.train.write_graph(,,as_text=False) 之前写出的模型文件是Binary时,
# 读入文件格式应该对应之前设置参数 python freeze_graph.py [***] --input_binary=true,
# 如果as_text=True则可以忽略,因为默认值 --input_binary=false。
# 参考: https://github.com/tensorflow/tensorflow/issues/5780
# Bug2: Input checkpoint '...' doesn't exist!
# 原因: 可能是命令行用了 --input_checkpoint=data.ckpt ,
# 运行 freeze_graph.py 脚本,要在路径参数前加上 "./" 貌似才能正确识别路径。
# 如文件的路径 --input_checkpoint=data.ckpt 变为 --input_checkpoint=./data.ckpt
# 参考: http://www.it1me.seriousdigitalmedia.com/it-answers?id=42439233&ttl=How+to+use+freeze_graph.py+tool+in+TensorFlow+v1
# Bug3: google.protobuf.text_format.ParseError: 2:1 : Expected identifier or number.
# 原因: --input_checkpoint 需要找到 .ckpt.data-000*** 和 .ckpt.meta等多个文件,
# 因为在 --input_checkpoint 参数只需要添加 ckpt的前缀, 如: nn_model.ckpt,而不是完整的路径nn_model.ckpt.data-000***
# .meta .index .data checkpoint 4个文件
# Bug4: # you need to use a different restore operator?
# tensorflow.python.framework.errors_impl.DataLossError: Unable to open table file ./pos.ckpt.data-00000-of-00001: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
# Saver 保存的文件用格式V2,解决方法更新tensorflow....
# 欢迎补充
最后如果输出如下: Converted variables to const ops. * ops in the final graph 就代表绑定成功了!发现绑定了参数的的.pb文件大小有10多MB。
2. C++API调用模型和编译
在C++预测阶段,我们在工程目录下引用两个tensorflow的头文件:
2.1 C++加载模型
?
[cpp] view plain copy
#include "tensorflow/core/public/session.h"
#include "tensorflow/core/platform/env.h"
在这个例子中我们把C++的API方法都封装在基类里面了。 FeatureAdapterBase 用来处理输入的特征,以及ModelLoaderBase提供统一的模型接口load()和predict()方法。然后可以根据自己的模型可以继承基类实现这两个方法,如本demo中的ann_model_loader.cpp。可以参考下,就不具体介绍了。
a) 新建Session, 从model_path 加载*.pb模型文件,并在Session中创建图。预测的核心代码如下:
?
[cpp] view plain copy
// @brief: 从model_path 加载模型,在Session中创建图
// ReadBinaryProto() 函数将model_path的protobuf文件读入一个tensorflow::GraphDef的对象
// session->Create(graphdef) 函数在一个Session下创建了对应的图;
int ANNModelLoader::load(tensorflow::Session* session, const std::string model_path) {
//Read the pb file into the grapgdef member
tensorflow::Status status_load = ReadBinaryProto(Env::Default(), model_path, &graphdef);
if (!status_load.ok()) {
std::cout <<"ERROR: Loading model failed..." << model_path << std::endl;
std::cout << status_load.ToString() <<"\n";
return -1;
}
// Add the graph to the session
tensorflow::Status status_create = session->Create(graphdef);
if (!status_create.ok()) {
std::cout <<"ERROR: Creating graph in session failed..." << status_create.ToString() << std::endl;
return -1;
}
return 0;
}
b) 预测阶段的函数调用 session->Run(input_feature.input, {output_node}, {}, &outputs);
参数 const FeatureAdapterBase& input_feature, 内部的成员input_feature.input是一个Map型, std::vector, 类似于python里的feed_dict={"x":x, "y": y},这里的C++代码中的输入tensor_name也一定要和python训练脚本中的一致, 如上文中设定的"inputs", "targets" 等。调用基类 FeatureAdapterBase中的方法assign(std::string, std::string tname, std::vector* vec) 函数来定义。
参数 const std::string output_node, 对应的就是在python脚本中定义的输出节点的名称,如"name_scope/output_node"
[cpp] view plain copy
int ANNModelLoader::predict(tensorflow::Session* session, const FeatureAdapterBase& input_feature,
const std::string output_node, double* prediction) {
// The session will initialize the outputs
std::vector outputs;//shape [batch_size]
// @input: vector >, feed_dict
// @output_node: std::string, name of the output node op, defined in the protobuf file
tensorflow::Status status = session->Run(input_feature.input, {output_node}, {}, &outputs);
if (!status.ok()) {
std::cout <<"ERROR: prediction failed..." << status.ToString() << std::endl;
return -1;
}
// ...
}
2.1 C++编译的方法
记得我们之前预先编译好的libtensorflow_cc.so文件,要成功编译需要链接那个库。 运行下列命令:
[cpp] view plain copy
# 使用g++
g++ -std=c++11 -o tfcpp_demo \
-I/usr/local/include/tf \
-I/usr/local/include/eigen3 \
-g -Wall -D_DEBUG -Wshadow -Wno-sign-compare -w \
`pkg-config --cflags --libs protobuf` \
-L/usr/local/lib/libtensorflow_cc \
-ltensorflow_cc main.cpp ann_model_loader.cpp
参数含义:
a) -I/usr/local/include/tf # 依赖的include文件
b) -L/usr/local/lib/libtensorflow_cc # 编译好的libtensorflow_cc.so文件所在的目录
c) -ltensorflow_cc # .so文件的文件名
为了方便调用,尝试着写了一个Makefile文件,将里面的路径换成自己的,每次直接用make命令执行就好
[python] view plain copy
make
此外,在直接用g++来编译的过程中可能会遇到一些Bug, 现在记录下来
[python] view plain copy
# Bug1: main.cpp:9:10: fatal error: 'tensorflow/core/public/session.h' file not found
# include "tensorflow/core/public/session.h"
# 原因: 这个应该就是编译阶段没有找到之前编译好的tensorflow_cc.so 文件,检查-I和-L的路径参数
# Bug2: fatal error: 'google/protobuf/stubs/common.h' file not found
# 原因:没有成功安装 protobuf文件
# 参考: http://blog.csdn.net/wwq_1111/article/details/50215645
# Bug3: /usr/local/include/tf/third_party/eigen3/unsupported/Eigen/CXX11/Tensor:1:10: fatal error: 'unsupported/Eigen/CXX11/Tensor' file not found
# 原因: 没有安装或找到Eigen的路径
# 参考之前安装Eigen的步骤
3. 运行
最后试着运行一下之前编译好的可执行文件 tfcpp_demo
[python] view plain copy
# 运行可执行文件,输入参数 model_path指向之前的包含参数的模型文件 nn_model_frozen.pb
folder_dir=`pwd`
model_path=${folder_dir}/model/nn_model_frozen.pb
./tfcpp_demo ${model_path}
# 或者直接执行脚本:
sh run.sh
?
我们试着预测一个样本[1,1,1,1,1],输出该样本对应的分类和概率。进行到这一步,我们终于成功完成了在python中定义模型和训练,然后 在C++生产代码中进行编译和调用的流程。
参考资料和延伸阅读
Github模型源代码地址
medium: loading-a-tensorflow-graph-with-the-c-api
exporting-trained-tensorflow-models-to-c-the-right-way
deepnlp 0.1.6 : Python Package Index
小礼物走一走