BP神经网络代码示例
BP神经网络
BP(back propagation)神经网络是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。
发展背景
在人工神经网络的发展历史上,感知机(Multilayer Perceptron,MLP)网络曾对人工神经网络的发展发挥了极大的作用,也被认为是一种真正能够使用的人工神经网络模型,它的出现曾掀起了人们研究人工神经元网络的热潮。单层感知网络(M-P模型)做为最初的神经网络,具有模型清晰、结构简单、计算量小等优点。
但是,随着研究工作的深入,人们发现它还存在不足,例如无法处理非线性问题,即使计算单元的作用函数不用阀函数而用其他较复杂的非线性函数,仍然只能解决解决线性可分问题.不能实现某些基本功能,从而限制了它的应用。增强网络的分类和识别能力、解决非线性问题的唯一途径是采用多层前馈网络,即在输入层和输出层之间加上隐含层。构成多层前馈感知器网络。
20世纪80年代中期,David Runelhart。Geoffrey Hinton和Ronald W-llians、DavidParker等人分别独立发现了误差反向传播算法(Error Back Propagation Training),简称BP,系统解决了多层神经网络隐含层连接权学习问题,并在数学上给出了完整推导。人们把采用这种算法进行误差校正的多层前馈网络称为BP网。
BP神经网络具有任意复杂的模式分类能力和优良的多维函数映射能力,解决了简单感知器不能解决的异或(ExclusiveOR,XOR)和一些其他问题。从结构上讲,BP网络具有输入层、隐藏层和输出层;从本质上讲,BP算法就是以网络误差平方为目标函数、采用梯度下降法来计算目标函数的最小值。
基本原理编辑
人工神经网络无需事先确定输入输出之间映射关系的数学方程,仅通过自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果。作为一种智能信息处理系统,人工神经网络实现其功能的核心是算法。BP神经网络是一种按误差反向传播(简称误差反传)训练的多层前馈网络,其算法称为BP算法,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小。
基本BP算法包括信号的前向传播和误差的反向传播两个过程。即计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行。正向传播时,输入信号通过隐含层作用于输出节点,经过非线性变换,产生输出信号,若实际输出与期望输出不相符,则转入误差的反向传播过程。误差反传是将输出误差通过隐含层向输入层逐层反传,并将误差分摊给各层所有单元,以从各层获得的误差信号作为调整各单元权值的依据。通过调整输入节点与隐层节点的联接强度和隐层节点与输出节点的联接强度以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。
BP网络是在输入层与输出层之间增加若干层(一层或多层)神经元,这些神经元称为隐单元,它们与外界没有直接的联系,但其状态的改变,则能影响输入与输出之间的关系,每一层可以有若干个节点。
计算过程
BP神经网络的计算过程由正向计算过程和反向计算过程组成。正向传播过程,输入模式从输入层经隐单元层逐层处理,并转向输出层,每层神经元的状态只影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入反向传播,将误差信号沿原来的连接通路返回,通过修改各神经元的权值,使得误差信号最小。
1.网络状态初始化
2.前向计算过程
优劣势
BP神经网络无论在网络理论还是在性能方面已比较成熟。其突出优点就是具有很强的非线性映射能力和柔性的网络结构。网络的中间层数、各层的神经元个数可根据具体情况任意设定,并且随着结构的差异其性能也有所不同。但是BP神经网络也存在以下的一些主要缺陷。
①学习速度慢,即使是一个简单的问题,一般也需要几百次甚至上千次的学习才能收敛。
②容易陷入局部极小值。
③网络层数、神经元个数的选择没有相应的理论指导。
④网络推广能力有限。
对于上述问题,目前已经有了许多改进措施,研究最多的就是如何加速网络的收敛速度和尽量避免陷入局部极小值的问题。
应用
目前,在人工神经网络的实际应用中,绝大部分的神经网络模型都采用BP网络及其变化形式。它也是前向网络的核心部分,体现了人工神经网络的精华。
BP网络主要用于以下四个方面。
1)函数逼近:用输入向量和相应的输出向量训练一个网络逼近一个函数。
2)模式识别:用一个待定的输出向量将它与输入向量联系起来。
3)分类:把输入向量所定义的合适方式进行分类。
4)数据压缩:减少输出向量维数以便于传输或存储。
代码示例
%BP神经网络matlab源程序代码)
%******************************%
%学习程序
%******************************%
%======原始数据输入========
p=[2845 2833 4488;2833 4488 4554;4488 4554 2928;4554 2928 3497;2928 3497 2261;...
3497 2261 6921;2261 6921 1391;6921 1391 3580;1391 3580 4451;3580 4451 2636;...
4451 2636 3471;2636 3471 3854;3471 3854 3556;3854 3556 2659;3556 2659 4335;...
2659 4335 2882;4335 2882 4084;4335 2882 1999;2882 1999 2889;1999 2889 2175;...
2889 2175 2510;2175 2510 3409;2510 3409 3729;3409 3729 3489;3729 3489 3172;...
3489 3172 4568;3172 4568 4015;]';
%===========期望输出=======
t=[4554 2928 3497 2261 6921 1391 3580 4451 2636 3471 3854 3556 2659 ...
4335 2882 4084 1999 2889 2175 2510 3409 3729 3489 3172 4568 4015 ...
3666];
ptest=[2845 2833 4488;2833 4488 4554;4488 4554 2928;4554 2928 3497;2928 3497 2261;...
3497 2261 6921;2261 6921 1391;6921 1391 3580;1391 3580 4451;3580 4451 2636;...
4451 2636 3471;2636 3471 3854;3471 3854 3556;3854 3556 2659;3556 2659 4335;...
2659 4335 2882;4335 2882 4084;4335 2882 1999;2882 1999 2889;1999 2889 2175;...
2889 2175 2510;2175 2510 3409;2510 3409 3729;3409 3729 3489;3729 3489 3172;...
3489 3172 4568;3172 4568 4015;4568 4015 3666]';
[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %将数据归一化
NodeNum1 =20; % 隐层第一层节点数
NodeNum2=40; % 隐层第二层节点数
TypeNum = 1; % 输出维数
TF1 = 'tansig';
TF2 = 'tansig';
TF3 = 'tansig';
net=newff(minmax(pn),[NodeNum1,NodeNum2,TypeNum],{TF1 TF2 TF3},'traingdx');
%网络创建traingdm
net.trainParam.show=50;
net.trainParam.epochs=50000; %训练次数设置
net.trainParam.goal=1e-5; %训练所要达到的精度
net.trainParam.lr=0.01; %学习速率
net=train(net,pn,tn);
p2n=tramnmx(ptest,minp,maxp);%测试数据的归一化
an=sim(net,p2n);
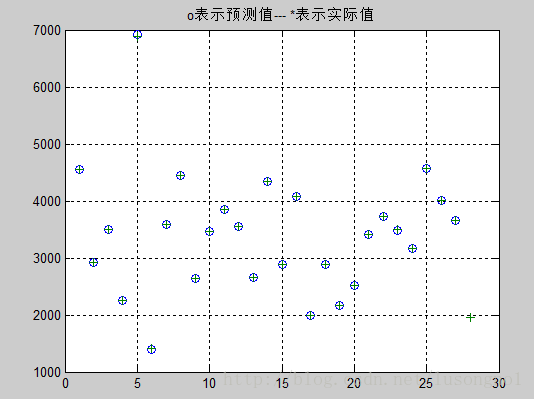
[a]=postmnmx(an,mint,maxt) %数据的反归一化 ,即最终想得到的预测结果
plot(1:length(t),t,'o',1:length(t)+1,a,'+');
title('o表示预测值--- *表示实际值')
grid on
m=length(a); %向量a的长度
t1=[t,a(m)];
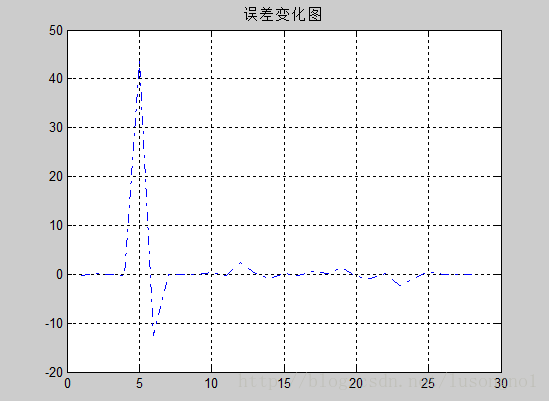
error=t1-a; %误差向量
figure
plot(1:length(error),error,'-.')
title('误差变化图')
grid on

神经网络代码:
clc
clear
P=[
0 0 0 0 0 0 0 0;
0 0 1 1 1 1 1 1;
0 0 2 2 2 2 2 2;
0 1 0 0 1 1 2 2;
0 1 1 1 2 2 0 0;
0 1 2 2 0 0 1 1;
0 2 0 1 0 2 1 2;
0 2 1 2 1 0 2 0;
0 2 2 0 2 1 0 1;
1 0 0 2 2 1 1 0;
1 0 1 0 0 2 2 1;
1 0 2 1 1 0 0 2;
1 1 0 1 2 0 2 1;
1 1 1 2 0 1 0 2;
1 1 2 0 1 2 1 0;
1 2 0 2 1 2 0 1;
1 2 1 0 2 0 1 2;
1 2 2 1 0 1 2 0;]';
%按每行为一个样本输入并装置,下次输入直接按列做样本即可。
T = [53.44096386 137.9638554 99.42409639 91.27951807 177.2987952 203.8819277 23.80481928 171.2120482 146.1445783 144.9253012 ...
55.84096386 127.7445783 110.653012 170.6626506 128.0361446 225.6795181 46.55421687 124.1012048];
[P PS_P]=mapminmax(P,0.1,0.9)
%max min按列求最大最小,标准化处理还可以[P,minp,maxp,T,mint,maxt] = premnmx(P,T)
[T PS_T]=mapminmax(T,0.1,0.9)
net=newff(minmax(P),[12,1],{'tansig','purelin'},'trainscg');
%训练前馈网络的第一步是建立网络对象
%常用的激活函数有线性函数purelin 对数s形转移logsig 双曲正切tansig 激活函数无论对于识别率或收敛速度都有显著的影响。在逼近高次曲线时,S形函数精度比线性函数要高得多,但计算量也要大得多
%常用训练函数有traingd traingdx
%traninglm等 隐含节点个数过多会增加运算量,使得训练较慢。
%learn属性 'learngdm' 附加动量因子的梯度下降学习函数
%net=init(net)
inputWeights=net.IW{1,1}
inputbias=net.b{1}
layerWeights=net.LW{2,1}
layerbias=net.b{2}
net.trainParam.mc = 0.9;
%动量因子一般取0.6 ~0.8
net.trainParam.epochs = 30;
net.trainParam.show = 10;
net.trainParam.goal = 1e-2;
%net.performFcn='msereg';
net.performParam.ratio=0.5;
%训练速率越大,权重变化越大,收敛越快;但训练速率过大,会引起系统的振荡,因此,训练速率在不导致振荡前提下,越大越好。一般取0.9
net.trainParam.lr=0.05;
%学习率设置偏小可以保证网络收敛,但是收敛较慢。相反,学习率设置偏大则有可能使网络训练不收敛,影响识别效果。
[net,tr]=train(net,P,T);
%[ net, tr, Y1, E ] = train( net, X, Y ) 参数:X:网络实际输入Y:网络应有输出 tr:训练跟踪信息 Y1:网络实际输出 E:误差矩阵
P_af=sim(net,P)
error=abs(T-P_af)./T
plot(P_af,'g-')
hold on;
plot(T,'r-')
opt_sol=max(T);
t_best=[1 0 1 1 0 0 -1 0]'
for i=0.8:0.1:1
for j=-0.1:0.1:0.1
for k=0.8:0.1:1
for l=0.8:0.1:1
for m=-0.1:0.1:0.1
for n=-0.1:0.1:0.1
for o=-1:0.1:-0.8
for p=-0.1:0.1:0.1
t=[i j k l m n o p]'
a=sim(net,t)
if opt_sol<=a
opt_sol=a
t_best=t
end
end
end
end
end
end
end
end
end
t_best=[rev(t_best(1),2,3),rev(t_best(2),10,20),rev(t_best(3),70,90),rev(t_best(4),5,15),rev(t_best(5),0.5,1.5),rev(t_best(6),3,7),rev(t_best(7),0.15,0.50),rev(t_best(8),20,30)]
opt_sol=rev(opt_sol,23.80,225.67)
net=init(net)实例分析:最优工艺参数优化神经网络代码
clc
clear
close all;
P=[
0 0 0 0 0 0 0 0;
0 0 1 1 1 1 1 1;
0 0 2 2 2 2 2 2;
0 1 0 0 1 1 2 2;
0 1 1 1 2 2 0 0;
0 1 2 2 0 0 1 1;
0 2 0 1 0 2 1 2;
0 2 1 2 1 0 2 0;
0 2 2 0 2 1 0 1;
1 0 0 2 2 1 1 0;
1 0 1 0 0 2 2 1;
1 0 2 1 1 0 0 2;
1 1 0 1 2 0 2 1;
1 1 1 2 0 1 0 2;
1 1 2 0 1 2 1 0;
1 2 0 2 1 2 0 1;
1 2 1 0 2 0 1 2;
1 2 2 1 0 1 2 0;
]';
T = [53.44096386 137.9638554 99.42409639 91.27951807 177.2987952 203.8819277 23.80481928 171.2120482 146.1445783 144.9253012 ...
55.84096386 127.7445783 110.653012 170.6626506 128.0361446 225.6795181 46.55421687 124.1012048];
[P,minp,maxp,T,mint,maxt] = premnmx(P,T)%标准化处理
net=newff(minmax(P),[12,1],{'tansig','purelin'},'trainscg');%训练前馈网络的第一步是建立网络对象
%net=init(net)
net.trainParam.epochs = 30;
net.trainParam.show = 10;
net.trainParam.goal = 1e-2;
net.performFcn='msereg';
net.performParam.ratio=0.5;
[net,tr]=train(net,P,T);
P_af=sim(net,P)
error=abs(T-P_af)./T
plot(P_af,'g-')
hold on;
plot(T,'r-')
opt_sol=max(T);
for i=0.8:0.1:1
for j=-0.1:0.1:0.1
for k=0.8:0.1:1
for l=0.8:0.1:1
for m=-0.1:0.1:0.1
for n=-0.1:0.1:0.1
for o=-1:0.1:-0.8
for p=-0.1:0.1:0.1
t=[i j k l m n o p]'
a=sim(net,t)
if opt_sol<=a
opt_sol=a
t_best=t
end
end
end
end
end
end
end
end
end
t=[rev(t(1),2,3),rev(t(2),10,20),rev(t(3),70,90),rev(t(4),5,15),rev(t(5),0.5,1.5),rev(t(6),3,7),rev(t(7),0.15,0.50),rev(t(8),20,30)]
opt_sol=rev(opt_sol,23.80,225.67)
实例分析:涂层工艺全局最优matlab代码
clc
clear
close all;
P=[
0 0 0 0 0 0 0 0;
0 0 1 1 1 1 1 1;
0 0 2 2 2 2 2 2;
0 1 0 0 1 1 2 2;
0 1 1 1 2 2 0 0;
0 1 2 2 0 0 1 1;
0 2 0 1 0 2 1 2;
0 2 1 2 1 0 2 0;
0 2 2 0 2 1 0 1;
1 0 0 2 2 1 1 0;
1 0 1 0 0 2 2 1;
1 0 2 1 1 0 0 2;
1 1 0 1 2 0 2 1;
1 1 1 2 0 1 0 2;
1 1 2 0 1 2 1 0;
1 2 0 2 1 2 0 1;
1 2 1 0 2 0 1 2;
1 2 2 1 0 1 2 0;
]';
T = [53.44096386 137.9638554 99.42409639 91.27951807 177.2987952 203.8819277 23.80481928 171.2120482 146.1445783 144.9253012 ...
55.84096386 127.7445783 110.653012 170.6626506 128.0361446 225.6795181 46.55421687 124.1012048];
z=1
[P,minp,maxp,T,mint,maxt] = premnmx(P,T)%标准化处理
net=newff(minmax(P),[12,1],{'tansig','purelin'},'trainscg');%训练前馈网络的第一步是建立网络对象
%net=init(net)
net.trainParam.epochs = 30;
net.trainParam.show = 10;
net.trainParam.goal = 1e-2;
net.performFcn='msereg';
net.performParam.ratio=0.5;
[net,tr]=train(net,P,T);
P_af=sim(net,P)
error=abs(T-P_af)./T
plot(P_af,'g-')
hold on;
plot(T,'r-')
opt_sol=max(T);
t_best=[0 0 0 0 0 0 0 0]'
for i=-1:0.2:1
for j=-1:0.2:1
for k=-1:0.2:1
for l=-1:0.2:1
for m=-1:0.2:1
for n=-1:0.2:1
for o=-1:0.2:1
for p=-1:0.2:1
t=[i j k l m n o p]'
a=sim(net,t)
if a>=300
a(z)=a
b(z,1:8)=t
z=z+1
end
if opt_sol<=a
opt_sol=a
t_best=t
end
end
end
end
end
end
end
end
end
t_best=[rev(t_best(1),2,3),rev(t_best(2),10,20),rev(t_best(3),70,90),rev(t_best(4),5,15),rev(t_best(5),0.5,1.5),rev(t_best(6),3,7),rev(t_best(7),0.15,0.50),rev(t_best(8),20,30)]
opt_sol=rev(opt_sol,23.80,225.67)
net=init(net)
BP神经网络无敌模板:
clc
clear
clf
P=[
0 0 0 0 0 0 0 0;
0 0 1 1 1 1 1 1;
0 0 2 2 2 2 2 2;
0 1 0 0 1 1 2 2;
0 1 1 1 2 2 0 0;
0 1 2 2 0 0 1 1;
0 2 0 1 0 2 1 2;
0 2 1 2 1 0 2 0;
0 2 2 0 2 1 0 1;
1 0 0 2 2 1 1 0;
1 0 1 0 0 2 2 1;
1 0 2 1 1 0 0 2;
1 1 0 1 2 0 2 1;
1 1 1 2 0 1 0 2;
1 1 2 0 1 2 1 0;
1 2 0 2 1 2 0 1;
1 2 1 0 2 0 1 2;
1 2 2 1 0 1 2 0;]';
%按每行为一个样本输入并装置,下次输入直接按列做样本即可。
T = [53.44096386 137.9638554 99.42409639 91.27951807 177.2987952 203.8819277 23.80481928 171.2120482 146.1445783 144.9253012 ...
55.84096386 127.7445783 110.653012 170.6626506 128.0361446 225.6795181 46.55421687 124.1012048];
[P PS_P]=mapminmax(P,0.1,0.9)
%max min按列求最大最小,标准化处理还可以[P,minp,maxp,T,mint,maxt] = premnmx(P,T)
[T PS_T]=mapminmax(T,0.1,0.9)
n=length(T)
n1=10%设置用来训练的样本个数
n2=n-n1
rd=randperm(n)
P1=P(:,rd(1:n1))
P2=P(:,rd(n1+1:n))
T1=T(rd(1:n1));T2=T(rd(n1+1:n))%将样本分为训练样本和监控样本
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%数据的预处理
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
net=newff(minmax(P),[7,1],{'logsig','purelin'},'traingdx');
%训练前馈网络的第一步是建立网络对象
%常用的激活函数有线性函数purelin 对数s形转移logsig 双曲正切tansig 激活函数无论对于识别率或收敛速度都有显著的影响。在逼近高次曲线时,S形函数精度比线性函数要高得多,但计算量也要大得多
%常用训练函数有traingd traingdx trainscg
%traninglm等 隐含节点个数过多会增加运算量,使得训练较慢。
%learn属性 'learngdm' 附加动量因子的梯度下降学习函数
%net.iw{1,1}= inputWeights
%net.lw{2,1}=layerWeights
%net.b{1}=inputbias
%net.b{2}=layerbias
net.trainParam.mc = 0.8;
%动量因子一般取0.6 ~0.8
net.trainParam.epochs = 1000;
net.trainParam.show = 10;
net.trainParam.goal = 1e-2;
net.performParam.ratio=0.7;
%训练速率越大,权重变化越大,收敛越快;但训练速率过大,会引起系统的振荡,因此,训练速率在不导致振荡前提下,越大越好。一般取0.9
net.trainParam.lr=0.05;
%学习率设置偏小可以保证网络收敛,但是收敛较慢。相反,学习率设置偏大则有可能使网络训练不收敛,影响识别效果。
[net,tr]=train(net,P1,T1);%net=init(net)
%[ net, tr, Y1, E ] = train( net, X, Y ) 参数:X:网络实际输入Y:网络应有输出 tr:训练跟踪信息 Y1:网络实际输出 E:误差矩阵
T1_sim=sim(net,P1)
T2_sim=sim(net,P2)
e1=sum(abs((T1_sim-T1)./T1))/n1
e2=sum(abs((T2_sim-T2)./T2))/n2%求相对平均误差绝对值
en=e1*n1/n+e2*n2/n%逼近误差
dn=100/exp(10*en)%逼近度
net=init(net)
subplot(1,2,1),plot(T1);hold on;plot(T1_sim,'r')
subplot(1,2,2),plot(T2,':mo');hold on;plot(T2_sim,'-.r*')
%inputWeights=net.iw{1,1}
%layerWeights=net.lw{2,1}
%inputbias=net.b{1}
%layerbias=net.b{2}
%save mynet net;
%load mynet net;
