HDP 2.5安装搭建部署
前言
HDP 全称Hortonworks Data Platform (HDP),是Hortomworks公司提供的一个大数据平台,它整合了开源hadoop生态圈的大部分组件,能够很简单便捷的帮助我们搭建起Hadoop大数据集群环境,与此类似的还有CDH(Cloudera Hadoop)。因最近在公司搭建这个,在此记录一下。
环境
- CentOS 7.x
- JDK 1.8
- HDP 2.5
准备工作
安装创建本地仓库工具
首先肯定是要有一台服务器可以连接外网的,否则任何软件包都无法下载了。
以下命令默认都是以root用户运行:
# yum install createrepo -ycreaterepo工具可以帮助我们创建一个本地局域网的私有仓库。
安装yum-utils包
yum-utils包含有reposync工具,可以方便的从远程同步仓库镜像到本地
# yum install yum-utils -y安装配置nginx
安装nginx是用来方便内网其他服务器进行访问私有仓库,用apache也可以,不过我个人比较喜欢用nginx。
# yum install nginx -y将nginx配置成文件服务器,类似apache那种。编辑/etc/nginx/nginx.conf文件。
# vim /etc/nginx/nginx.conf
找到server节点,添加以下内容即可。
server {
listen 80 default_server;
location / {
root /var/www/html; #这里可以选择一个空间较大分区
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
}之后执行以下命令,启动nginx,查看运行状态以及设置开机自启:
# systemctl start nginx
# systemctl status nginx # 出现Active: active (running)表示启动成功
# systemctl enable nginx配置HDP 2.5源
在可以访问外网的服务器上进行配置,执行以下命令:
# wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.2.0/ambari.repo -O /etc/yum.repos.d/ambari.repo这个命令是配置ambari仓库的,Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。目前也是Apache的顶级项目。
继续配置hdp仓库,执行以下命令:
# wget -nv http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.5.0.0/hdp.repo -O /etc/yum.repos.d/hdp.repo生成一下缓存:
# yum makecache
然后查看仓库id等信息,方便后面制作私有仓库。
# yum repolist
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
repo id repo name
!HDP-2.5.0.0 HDP Version - HDP-2.5.0.0
!HDP-UTILS-1.1.0.21 HDP-UTILS Version - HDP-UTILS-1.1.0.21
!Updates-ambari-2.4.2.0 ambari-2.4.2.0 - Updates创建私有仓库
进入我们上面nginx设置的web目录,通过reposync命令从远程同步仓库数据到本地来,执行以下命令:
# reposync -r xxx(repo id)其中的repo id就是上面通过yum repolist查看到的第一列。
比如想要同步hdp相关仓库就输入:
# reposync -r Updates-ambari-2.4.2.0
# reposync -r HDP-2.5.0.0
# reposync -r HDP-UTILS-1.1.0.21之后进入每个仓库目录下面,执行# createrepo .命令就可以创建一个源仓库了,也可以直接在当前目录下面执行,这样就把三个仓库都放在一个里面了。
使用私有仓库
局域网集群中其他服务器要使用该仓库,也需要进行一些配置。
在私有仓库的服务器镜像目录中新建一个hdp.repo文件,内容如下:
[HDP]
name=hdp Version - 2.5
baseurl=http://192.168.1.2[server-ip]/hdp
gpgcheck=0
enabled=1
priority=1其中参数说明:
- [HDP]表示该仓库的id为HDP,可通过yum repolist查看。出现了该id即配置正确
- baseurl表示仓库的根路径,这里如果是本地的话,可以输入:file:///var/www/html/hdp
- gpgcheck=0表示不进行签名检查
- enabled=1表示启用该仓库,如果为0则表示不使用该仓库
- priority=1表示优先级,如果一个软件包在多个仓库都有,会优先使用这个。
然后在其他机器上,通过运行以下命令,导入仓库配置:
# wget -nv http://192.168.1.2/hdp/hdp.repo -O /etc/yum.repo.d/hdp.repo之后进行仓库检测和缓存:
# yum repolist # 查看是否有HDP这个repo id
# yum makecache好了,这个还没开始安装,光搭环境就说半天了。之前在公司也是,搭个环境都要好几天了。下面开始真正的安装吧。
安装ambari
仓库都配置好了以后,我们可以选择一台服务器作为master主服务器,集群的配置可以在ambari web控制台进行添加。master服务器也要添加那个私有仓库,然后再安装ambari-server:
# yum install ambari-server -y安装成功以后。需要进行初始化配置,执行以下命令:
# ambari-server setup
进入交互式设置向导界面
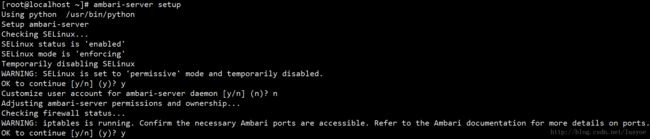
这里会提示要临时关闭SELinux和配置iptables运行ambari端口访问等等,嫌麻烦可以把这些防火墙都关掉,先Ctrl+C退出初始化向导,然后关闭防火墙。
关闭防火墙
# systemctl stop firewalld
# systemctl disable firewalld
# setenforce 0 # 临时关闭selinux
永久关闭selinux
编辑/etc/selinux/config
将SELINUX=enforcing改为
SELINUX=disabled
执行以下命令即可,重启生效
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config初始化ambari-server
关闭SELinux等防火墙重启后,继续执行ambari-server setup进行初始化:
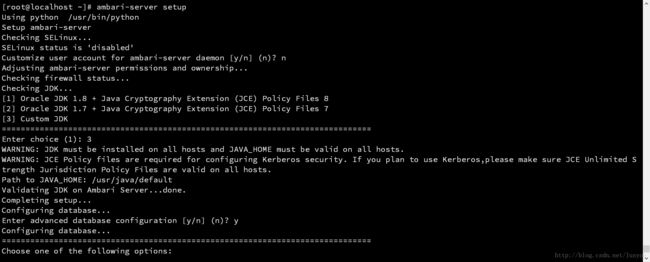
根据提示进行输入,jdk是通过从官网下的rpm包安装的,所以默认路径就是在/usr/java/default。
最下方是选择数据库的配置,因为默认是使用嵌入式的PostgreSQL,我们可以改为MySQL。

这里我们需要在数据库中分别创建ambari数据库和ambari用户,注意这里有一个坑:数据库密码只能输入字符数字和 _下划线,还有-减号。不能包含特殊字符,否则会报以下错误信息:
Enter Database Password (bigdata):
Invalid characters in password. Use only alphanumeric or _ or - characters而MySQL 5.7默认安全策略是中级的,需要有特殊字符,这个可以通过以下命令进行修改,
使用root用户登录mysql数据库服务器:
mysql> set global validate_password_policy=0;
mysql> flush privileges;这样密码策略就改为低级了,只需要符合8位长度即可。
最后根据提示还需要安装mysql java驱动,执行以下命令安装即可,如果是内网的话,将mysql驱动文件复制到/usr/share/java路径下即可:
# yum install mysql-connector-java -y安装好mysql驱动后,再次执行初始化操作:
# ambari-server setup
安装提示,配置完数据库后,会检测数据库的连接等,打印以下信息:

根据提示,表明初始化已成功了,但是在启动ambari-server之前需要在数据库服务器上运行/var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sqlSQL文件,主要是用于创建表约束的。
在远程创建好数据库后,本地执行以下命令即可:
# mysql -h 192.168.1.2 -uroot -p -Dambari < /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql启动ambari-server
导入表结构后就可以启动ambari-server了,注意一定要先导入表结构,因为在启动ambari-server的时候会去检查表约束的。检测失败就无法启动ambari-server了,具体的失败原因可通过查看以下两个文件分析:
/var/log/ambari-server/ambari-server.log
/var/log/ambari-server/ambari-server-check-database.log最后启动成功,打印如下信息:

然后通过web浏览器,可以访问ambari控制台了。地址为安装的服务器ip,端口8080:http://server-ip:8080
注意别让其他应用占用该端口了。
默认登录用户名和密码都为admin

配置集群服务
进入到首页,点击Launch Install Wizard,开始安装向导

这个配置步骤有点多,这里还是一步步列出来好了,方便供大家参考
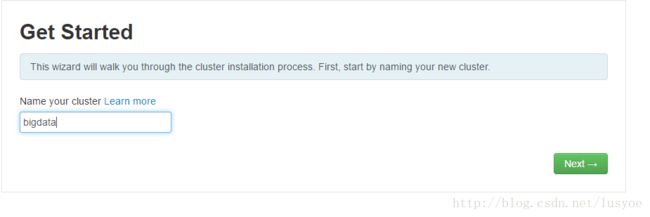
步骤一:
输入一个集群名称,这个随意就可以了。
步骤二:
挑选一个版本,这里选择HDP-2.5,还是下面的仓库配置,使用本地仓库,因为都是CentOS 7.x系统,所以只保留redhat7这个仓库选项就可以了,其他的都删除掉,点击右边Remove即可
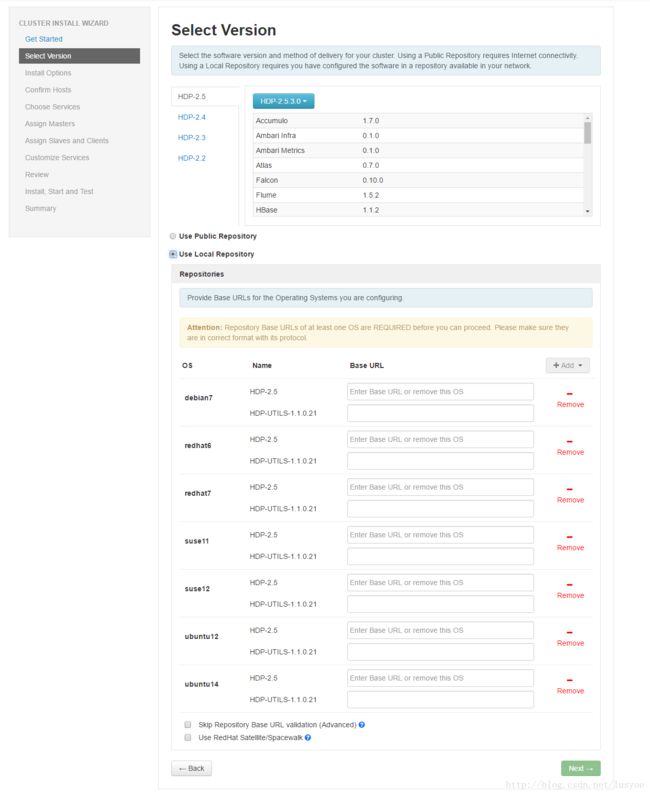
其中base url就是我们在hdp.repo等这些仓库文件中配置的base url地址,如下:

如果输入错误的话,会给予提示的,并无法进入下一步,正确之后点击Next,进入下一步
步骤三:
在这一步是配置集群机器的,还有私钥上传。注意是私钥id_rsa的文件。
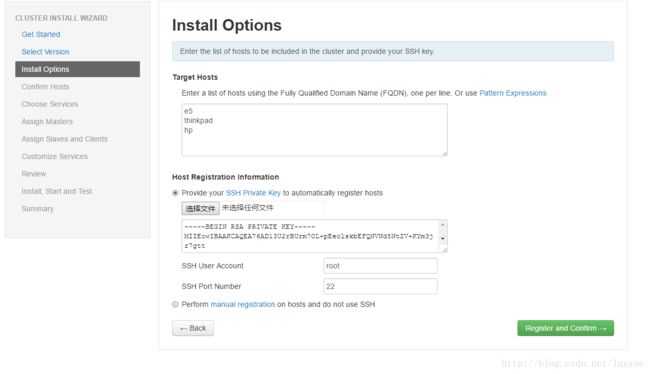
如果是多台机器的话,还要配置ssh无密码登录等等这里就不多说了。
如果是单台服务器的话,也需要将公钥导入到authorized_keys文件中。# ssh-keygen # 一直回车生成密钥对 # cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys如果是干净的服务器环境,就需要执行以上两步。
步骤四:
这一步就是确认主机的访问性,安装agent等
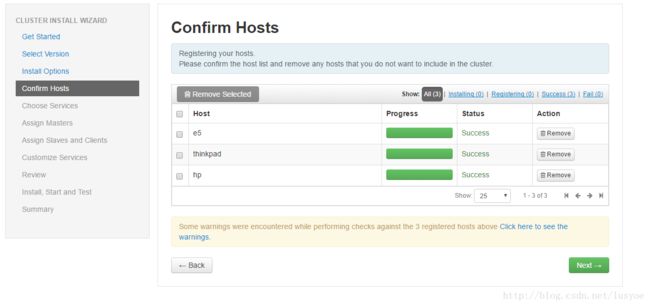
步骤五:
这一步是选择要安装的服务了,可以看到有非常多的服务可选,这里建议只选择少量的几个就可以了,加快安装时间。后面有需要可以再添加这些服务。

步骤六:
分配主机服务,比如哪些服务运行在哪个服务器上等等,可根据服务器的硬件配置进行相应的选择。

步骤七:
安装集群一些服务的客户端

步骤八:
定制服务,就是配置服务的一些属性,还有数据库连接配置等信息
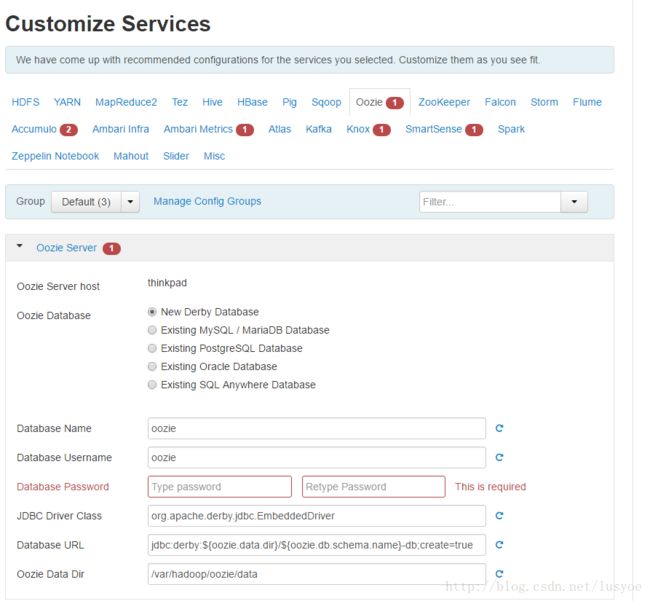
其中有红色小点的都是数据库未配置导致的,进行相应的配置即可。
配置,所有小红点都消失后就可以进入下一步了。步骤九:
这一步就是重新检查一下配置的一些属性。
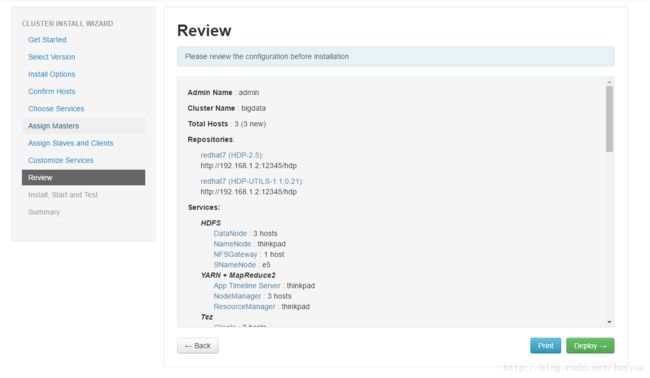
步骤十:
基本都配置完了,这一步就开始在集群中的所有机器上安装对应服务,并且启动服务。这一步有时候也会经常出问题的,比如安装失败了,启动失败了等等。后续会把一些错误总结单独写一篇吧。
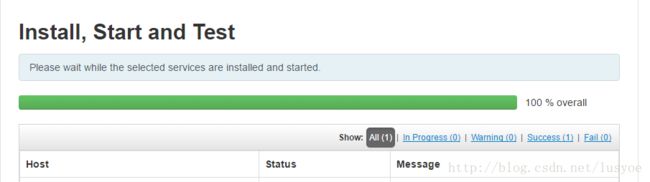
配置完成就可以进入控制台页面了。

后记
在公司在家里搭建这个环境差不多花了好几天吧,中间也遇到过很多的问题,很多坑。只想说大数据这东西要想玩起来,成本真不小,门槛也挺高的。起码至少就要Linux熟练精通了,否则出现一大堆问题都不知道怎么解决,得益于我早几年前就开始接触学习Linux了,真的对我帮助很大。
最后是对一些大数据新手的建议,不要把过多的时间花在集群环境的搭建上面了。要把精力更多的放在业务算法,逻辑处理,数据分析等等更好。这也正是我写这篇的原因,尽可能的减少环境搭建时间。
如果也有搞大数据这块的,可以一起交流学习哈。共勉~