C++11的6种内存序总结
对于C++11的6种并发查了不少相关资料,这里作一个总结和理解std::memory_order_relaxed,std::memory_order_consume,std::memory_order_acquire
std::memory_order_release,std::memory_order_acq_rel,std::memory_order_seq_cst
粗浅理解(了解大概)
编译器优化而产生的指令乱序,cpu指令流水线也会产生指令乱序,总体来讲,编译器优化层面会产生的指令乱序,cpu层面也会的指令流水线优化产生乱序指令。当然这些乱序指令都是为了同一个目的,优化执行效率
happens-before:按照程序的代码序执行
int a=0,int b=1;
void func(){
a=b+22;
b=22;
}代码没有被编译器优化,按照正常指令执行:
movl b(%rip), %eax ; 将 b 读入 %eax
addl $22, %eax ; %eax 加 22, 即 b + 22
movl %eax, a(%rip) ; % 将 %eax 写回至 a, 即 a = b + 22
movl $22, b(%rip) ; 设置 b = 22
优化后:
movl b(%rip), %eax ; 将 b 读入 %eax
movl $22, b(%rip) ; b = 22
addl $22, %eax ; %eax 加 22
movl %eax, a(%rip) ; 将 b + 22 的值写入 a,即 a = b + 2synchronized-with:不同线程间,对于同一个原子操作,需要同步关系,store()操作一定要先于 load(),也就是说 对于一个原子变量x,先写x,然后读x是一个同步的操作,读x并不会读取之前的值,而是当前写x的值。
6种memory_order 主要分成3类,relaxed(松弛的内存序),sequential_consistency(内存一致序),acquire-release(获取-释放一致性)
1、relaxed的内存序:
没有顺序一致性的要求,也就是说同一个线程的原子操作还是按照happens-before关系,但不同线程间的执行关系是任意。
#include 其中即使1先于2(同一个线程保证原子执行顺序)但是在不同线程间的执行顺序是没有约束的,所以#4也有可能是false
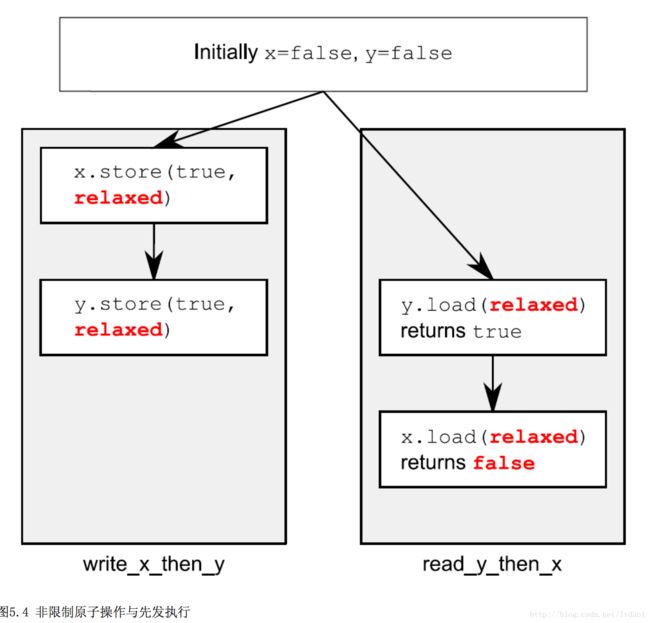
2、sequential consistency(内存一致性)
这个是以牺牲优化效率,来保证指令的顺序一致执行,相当于不打开编译器优化指令,按照正常的指令序执行(happens-before),多线程各原子操作也会Synchronized-with,(譬如atomic::load()需要等待atomic::store()写下元素才能读取,同步过程),当然这里还必须得保证一致性,读操作需要在“一个写操作对所有处理器可见”的时候才能读,适用于基于缓存的体系结构。
#include 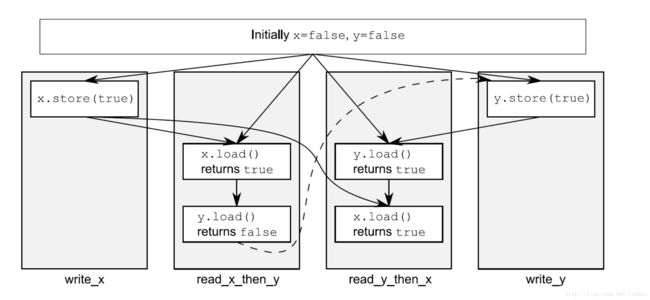
在同一个线程中,执行顺序,#1->#2 (原子操作),#3->#4(原子操作),指令序顺序执行,同时 保证Synchronized-with,#2->#3 必须要先store原子操作,然后在load原子操作。最终保证顺序一致性。这里z一定是1或者2,并不会出现0的情况,出现0的情况表示不一致。出现1 可能有2种,#3为false,说明x先于y写,此时y可能正在写。如果y写完了,#4是一定成功的,z=1,另一个z=1类似,y先于x写。当然还有x和y同时写完,则z=2;
当然要保证这种严格的顺序一致性,需要牺牲优化代价
1、在无缓存的体系结构下实现SC
- 带有读旁路的写缓冲(Write buffers with read bypassing)
读操作可以不等待写操作,导致后续的读操作越过前面的写操作,违反程序次序 - 重叠写(Overlapping writes)
对于不同地址的多个写操作同时进行,导致后续的写操作越过前面的读操作,违反程序次序 - 非阻塞读(Nonblocking reads)
多个读操作同时进行,导致后续的读操作越过前面的读操作先执行,违反程序次序
2、 在有缓存的体系结构下实现SC
对于带有缓存的体系结构,这种数据的副本(缓存)的出现引入了三个额外的问题:
- 缓存一致性协议(cache coherence protocols)
一个写操作最终要对所有处理器可见
对同一地址的写操作串行化
cache coherence的定义不能推出SC(不充分):SC要求对所有地址的写操作串行化。因此我们并不用cache coherence定义SC, 它仅作为一种传递新值(newly written value)的机制。 - 检查写完成(detecting write completion)
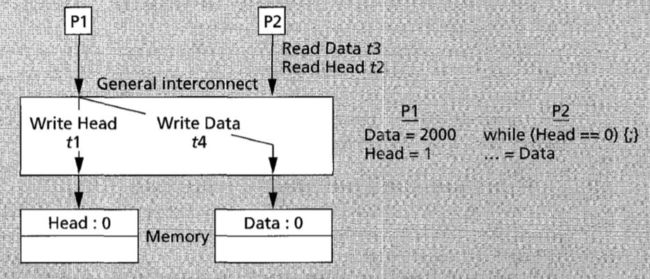
假设图中的处理器带有直写缓存(write through cache),P2 缓存了 Data. 违反SC的直写缓存
考虑如下执行次序:
P1 先完成了 Data 在内存上的写操作;
P1 没有等待 Data 的写结果传播到 P2 的缓存中,继续进行 Head 的写操作;P2 读取到了内存中 Head 的新值;
P2 继续执行,读到了缓存中 Data 的旧值。
这违反SC,因此我们需要延后每个处理器发布写确认通知的时间:直至别的处理器发回写确认通知,才发射下一个写操作。
- 维护写原子性(maintaining write atomicity):
“将值的改变传播给多个处理器的缓存”这一操作是非原子操作(非瞬发完成的),因此需要采取特殊措施提供写原子性的假象。因此我们提出两个要求,这两个要求将共同保证写原子性的实现。

要求1:针对同一地址的写操作被串行化(serialized). 上图阐述了对这个条件的需求:如果对 A 的写操作不是序列化的,那么 P3 和 P4 输出(寄存器 1,2)的结果将会不同,这违反了次序一致性。这种情况可以在基于网络(而不是总线)的系统中产生,由于消息可经不同路径传递,这种系统不 供它们传递次序的保证。
要求2:对一个新写的值的读操作,必须要等待所有(别的)缓存对该写操作都返回确认通知后才进行。

P2 读 A 为 1
“P2 对 B 的更新”先于“P1 对 A 的更新”到达 P3
P3 获得 B 的新值,获得 A 的旧值
这使得 P2 和 P3 看到的对值 A, B 的写操作次序不同,违反的了写原子性要求
3、acquire-release 获取-释放一致性
这个是对relaxed的加强,relax序由于无法限制多线程间的排序,所以引入synchronized-with,但并不一定意味着,统一的操作顺序
#include 如果是relax内存序,会出现z=0的情况,毕竟两个写x,y的线程以及两读x-y,读y-x的线程没有顺序一致性要求,可能出现
#1 写好x,y数据,但x还在缓冲中,并没有放入内存,这时候读x的数据#4为false,y写好数据,也放入缓冲,x也没有从内存读取新值,所以#3也为false,z=0;两个线程的x,y数据不一致,这种带有缓存违反顺序一致。
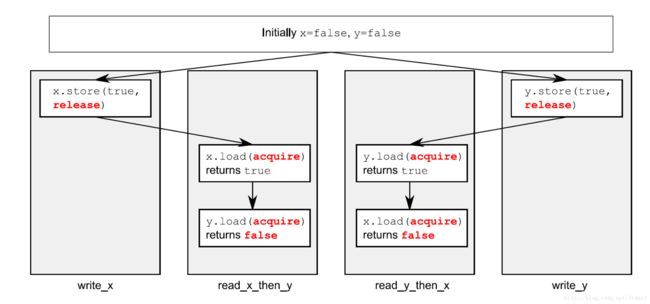
还是看例子:
#include 同一个线程 #1->#2, 由于acquire-release,#2->#3 ,又在同一个线程中,#3->#4,所以传递happens-before, #4一定能够获取#1的值,必然为true。
如果#3的while去掉,#3 可能由于#2还没有写入数据,导致为false, #4 和 #1 因为relaxed内存序,在不同线程,所以没有排序。release-acquire 对一般配对出现,如果都为release或者acquire,则无法同步。
例子:
std::atomic#1->#2 (循环一直到sync1被存储,sync1被存储,那么根据happened-before,前面的数组也设置了)->#3 (同一线程) ->#4
当然,在thread2中包含了 acquire-release,所以可以采用compare_exchange_strong()
std::atomic sync(0);
void thread_1()
{
// ...
sync.store(1,std::memory_order_release);
}
void thread_2()
{
int expected=1;
while(!sync.compare_exchange_strong(expected,2,
std::memory_order_acq_rel)) //执行acquire-release
expected=1;
}
void thread_3()
{
while(sync.load(std::memory_order_acquire)<2);
// ... } 锁住互斥量是一个获取操作,并且解锁这个互斥量是一个释放操作
4、memory_order_consume
这个内存序是 “获取-释放”的一部分,它依赖于数据,可以展示线程间的先行关系。
携带依赖:
int a=b+1;
int b=c+1;
a携带依赖于b,b携带依赖于c,a也就携带依赖c
struct X
{
int i;
std::string s;
};
std::atomic<X*> p;
std::atomic<int> a;
void create_x()
{
X* x=new X;
x->i=42;
x->s="hello";
a.store(99,std::memory_order_relaxed); // 1
p.store(x,std::memory_order_release); // 2
}
void use_x()
{
X* x;
while(!(x=p.load(std::memory_order_consume))) // 3
std::this_thread::sleep(std::chrono::microseconds(1));
assert(x->i==42); // 4
assert(x->s=="hello"); // 5
assert(a.load(std::memory_order_relaxed)==99); // 6
}
int main() {
std::thread t1(create_x);
std::thread t2(use_x);
t1.join();
t2.join(); }x是个指针,依赖2个数据,int i=42, string s=”hello” , #3循环,直到#2 x被store,那么在相应的依赖数据也设置好了,所以在#4,#5的断言也就可以通过。但a没有依赖,且是relaxed,无法判定断言
当然,你也可以使用kill_dependency()打破依赖链,在复杂代码中慎用。
int global_data[]={ ... }; std::atomic index;
void f() {
int i=index.load(std::memory_order_consume);
do_something_with(global_data[std::kill_dependency(i)]);
} 打破i与index的依赖链
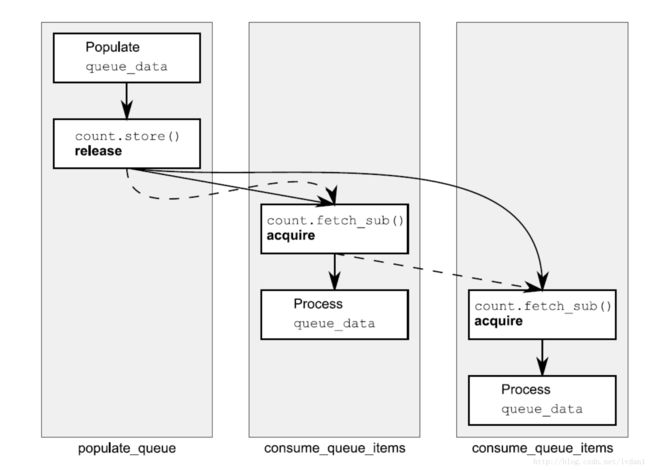
std::vector<int> queue_data;
std::atomic<int> _count;
void populate_queue() {
unsigned const number_of_items = 1000000;
queue_data.clear();
for (int i = 0; i < number_of_items; ++i) {
queue_data.push_back(i);
}
_count.store(number_of_items, std::memory_order_release); // 1 初始化存储
}
void consume_queue_items()
{
while(true)
{
int item_index;
if(0 >= (item_index=_count.fetch_sub(1, std::memory_order_acquire))) // 2 一个“读-改-写”操作
{
cout<":wait for more items"<// 3 等待更多元素
continue;
}
cout<":"<1]<// 4 安全读取queue_data
}
}
void play() {
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();
b.join();
c.join();
} 生产者,消费者模式。
如果fetch_sub采用std::memory_order_acq_rel (本机测试)
b c 的消费不一样,b大概每消费100个数据,c才消费一个数据 ?(不是很理解)
其他内存序都是交替消费.
实线是先行关系,虚线是释放顺序
5、栅栏
最后简单说下栅栏吧,栅栏相当于给内存加了一层栅栏,约束内存乱序。典型用法是和 relaxed一起使用。
栅栏操作让无序变有序
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
std::atomic_thread_fence(std::memory_order_release); // 2
y.store(true,std::memory_order_relaxed); // 3
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // 4
std::atomic_thread_fence(std::memory_order_acquire); // 5
if(x.load(std::memory_order_relaxed)) // 6
++z; }
int main() {
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 7
}在relaxed的例子中加了2道栅栏,#2,#5
栅栏#2同步与栅栏#5,所以 #1和#6就有了先行关系。 #7不会执行
栅栏也会让非原子操作有序
void write_x_then_y()
{
x=true; // 1 在栅栏前存储x std::atomic_thread_fence(std::memory_order_release);
y.store(true,std::memory_order_relaxed); // 2 在栅栏后存储y
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // 3 在#2写入前,持续等待
std::atomic_thread_fence(std::memory_order_acquire);
if(x) // 4 这里读取到的值,是#1中写入
++z; }
int main() {
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 5 断言将不会触发 }同上代码,断言不会触发,x的值一定是#1写入的
对非原子操作的排序,可以通过使用原子操作进行,这里“前序”作为“先行”的一部分,就显得十分重要 了。如果一个非原子操作是“序前”于一个原子操作,并且这个原子操作需要“先行”与另一个线程的一个操 作,那么这个非原子操作也就“先行”于在另外线程的那个操作了。
最后是互斥量的基本实现:
一般都是调用 具有std::memory_order_acquire语义的 lock操作
主要flag.test_and_set()上的循环 ,然后对数据进行修改,最后调用unlock(),相当于调用带有 语义的 flag.clear(),基本的互斥量都是这种类型,lock()作为一个获取操作存在,在同样的位置上unlock()作为一个释放操作存在。
参考文档资源:
https://github.com/forhappy/Cplusplus-Concurrency-In-Practice/blob/master/zh/chapter8-Memory-Model/web-resources.md
http://www.parallellabs.com/2011/08/27/c-plus-plus-memory-model/
https://www.zhihu.com/question/24301047
http://www.cnblogs.com/haippy/p/3412858.html
http://preshing.com/