从头开始搭建 hadoop
所有参考 网址 均给出链接 请自行点击
主要参考
史上最详细的Hadoop环境搭建
https://blog.csdn.net/hliq5399/article/details/78193113
第一部分:Linux环境安装
Hadoop是运行在Linux,虽然借助工具也可以运行在Windows上,但是建议还是运行在Linux系统上,第一部分介绍Linux环境的安装、配置、Java JDK安装等。
1.安装jdk
https://www.cnblogs.com/renqiqiang/p/6822143.html
2.安装VMware虚拟机
https://blog.csdn.net/qq_40950957/article/details/80467513
新建虚拟机选择ios镜像文件后第一次打开虚拟机启动失败

解决方案 按Del 键进入 BIOS

3.Vmware虚拟机下三种网络模式配置
https://blog.csdn.net/collection4u/article/details/14127671
4. 虚拟机 安装成功后 开启 node01 CentOS 7的 网络配置 和 yum groupinstall -y "GNOME Desktop" 图形界面安装
https://blog.csdn.net/qq_42595443/article/details/81199621
5、修改Hostname
6、配置Host
7. 安装
Xshell
https://blog.csdn.net/Cgh_Baby/article/details/89028914
Xftp 360 软件安装
8. Xshell 和 Xftp 连接虚拟机 主机 Node01
如何使用Xshell连接VMware上的Linux虚拟机
https://www.cnblogs.com/shireenlee4testing/p/9469650.html
9. 解决 关闭防火墙出错

解决方案
https://www.cnblogs.com/lemon-flm/p/7608029.html
https://blog.csdn.net/hanszjt/article/details/84561892
10. 安装 JDK
如何在Oracle官网下载java的JDK最新版本和历史版本
https://www.cnblogs.com/wdh1995/p/7927590.html
注意:Hadoop机器上的JDK,最好是Oracle的Java JDK,不然会有一些问题,比如可能没有JPS命令。
如果安装了其他版本的JDK,卸载掉。
使用CentOS7卸载自带jdk安装自己的JDK1.8
https://blog.csdn.net/hui_2016/article/details/69941850
linux下用rpm 安装jdk 7的jdk-7u79-linux-x64.rpm
https://blog.csdn.net/csdnones/article/details/72911534
先执行以下命令给所有用户添加可执行的权限
#chmod +x jdk-7u79-Linux-x64.rpm
//重点是下面的命令
执行rpm -ivh 命令,安装jdk-7u79-linux-x64.rpm
#rpm -ivh jdk-7u79-linux-x64.rpm
出现安装协议等,按接受即可。
至此 完成 一台 虚拟机 的 Linux 的需要 搭建 Hadoop 的基本配置。
11. 克隆 另外两台 系统 完成 hadoop 的集群节点的配置
克隆VMware虚拟机及克隆后修改系统参数的全过程
https://blog.csdn.net/coder__cs/article/details/79178025
克隆虚拟机后,使两台虚拟机完全独立需要更改的配置
https://blog.csdn.net/zhang123456456/article/details/55815940
centOS 7 的版本 只需要 更改克隆后 虚拟机以下步骤
11.1. 生成新的 MAC 地址
查看新生成的MAC值。打开新克隆的虚拟机的网络适配器>高级>查看MAC值

11.2. 修改 网卡配置文件,更新 IPADDR 为 192.168.254.128
vi /etc/sysconfig/network-scripts/ifcfg-ens33 ,配置文件,更新 IP 地址
11.3.修改 hostname 和 host
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=Node02
vim /etc/hosts
192.168.254.128 Node02
11.4. 删除/etc/udev/rules.d/70-persistent-net.rules文件,重启系统后自动生成的,可以放心删除。 (新克隆的虚拟机删除)
rm -rf /etc/udev/rules.d/70-persistent-net.rules
以上步骤修改完成,重启系统。reboot
11.5. 关linux防火墙与selinux
[root@Node02 ~]# service iptables stop
11.6. 测试 ping 以及 Xshell 成功连接
12 . 保证3个节点间能相互ping 通
修改 vim /etc/hosts 把三个 Node01,Node02, Node03 对应IP 都配置
13. 虚拟机时间同步
在搭建集群环境时,需要各个节点的主机时间是一致的,否则会出现问题,连接时间相应不对。要进行是时间同步。
https://www.cnblogs.com/ljangle/p/9064551.html
14. 三台 节点 SSH 免密登录
虚拟机centos6.5 --ssh免密码登录
https://www.cnblogs.com/bookwed/p/4809390.html
在三台Centos虚拟机分主从机上设置SSH免密码登录
https://blog.csdn.net/xujing19920814/article/details/74942087
出现的错误
SSH 远程发送文件错误
[root@Node02 .ssh]# scp ./id_rsa.pub root@Node01:/root/.ssh/id_rsq.pub02
ssh: connect to host node01 port 22: No route to host
解决方法 :
查看 当前node节点 vi /etc/hosts
发现 Node01 对应的 IP 192.168.254.129 配置错误
导致SSH 连接 Node01 找不到正确的IP
第二部分:Hadoop模式安装
Hadoop本地模式只是用于本地开发调试,或者快速安装体验Hadoop,这部分做简单的介绍。
Hadoop伪分布式模式安装
1. 确保环境准备
JDK
Linux
准备至少3台机器(克隆虚拟机)配置好网络 时间同步 hosts 保证节点间能互ping通
时间同步 ntpdate time.nist.gov
ssh 免密钥登陆 两两互通免密钥
2.搭建步骤
2.1下载解压缩 Hadoop
2.2在 etc/hadoop/hadoop-env.sh 文件中配置
export JAVA_HOME=/usr/java/latest
2.3 配置 core-site.xml
fs.defaultFS 默认的服务端口 NameNode URI
hadoop.tmp.dir 是 hadoop文件系统依赖的基础配置,很多路径都它。如果 hdfs-site.xml中不配 置 namenode和 datanode的存放位置,默认就在这个路径中 的存放位置

2.4 配置 hdfs-site.xml

2.5 Masters: master 可以做主备的SNN
在/home/hadoop-2. 6.5/etc/hadoop/ 新建 master文件
写上 SNN 节 点名: node2
2.6 Slaves 填写DN节点
/home/hadoop-2.6.5/etc/hadoop/slaves DN 节点名 一行一个
2.7 配置Hadoop 环境变量 /bash_profile 并通过scp 命令发送给其他节点
export HADOOP_HOME=/home/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/BIN:$HADOOP_HOME/sbin
不建议使用 全局hadoop环境变量 应该配置局部环境变量
环境变量的配置文件:
全局:/etc/profile
局部:~/.bash_profile
2.8 source ~/.bash_profile
2.9 根目录下对 NN节点格式化
hdfs namenode -formate
2.10 关闭防火墙
service iptables stop
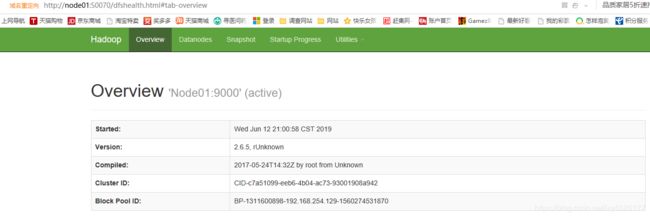
3 . 启动HDFS
start-dfs.sh
浏览器输入 node01:50070
4. 相关 hdfs 命令

安装过程中,加入自己遇到的问题及解决方案。希望能对大家有所帮助。