GAN系列:李宏毅老师GAN课程P7——Info GAN,VAE-GAN,BiGAN
Info GAN:
在GAN的生成器中,输入一个随机向量,可生成一副图像。向量和图像间的关系可以理解为某种映射,也可以视作向量是图像的特征(尽管可能是隐形的)。为了能找到向量中每个元素/特征和生成图像间的关系,希望元素的改变对图像的影响是有规律可循的,但是一般这种规律是不直观的,如下图所示:
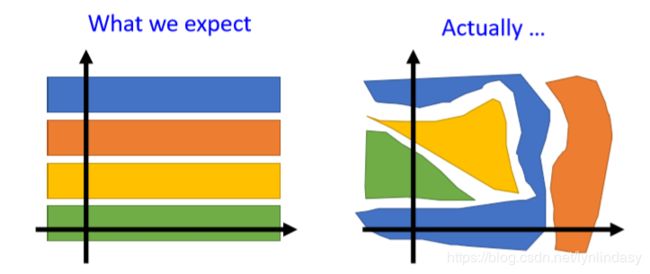
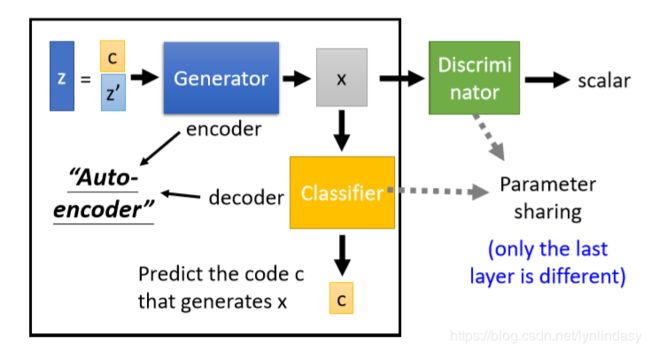
Info GAN就是针对该问题进行的改进:
1. 生成器![]() 的输入随机向量
的输入随机向量![]() 由两部分组成:
由两部分组成:![]() 和
和![]() (都是向量),生成器
(都是向量),生成器![]() 要学到
要学到![]() 中每一个元素对图像生成的影响(
中每一个元素对图像生成的影响(![]() 的每一个维度都表示图像的某个特征),
的每一个维度都表示图像的某个特征),![]() 就是纯随机向量;
就是纯随机向量;
2. 训练一个分类器![]() :根据生成器
:根据生成器![]() 的输出
的输出![]() 预测其对应的生成器
预测其对应的生成器![]() 的输入中的
的输入中的![]() ;
;
3. 生成器![]() 和分类器
和分类器![]() 构成一个
构成一个![]() ,和普通的
,和普通的![]() 功能刚好相反:从编码向量生成图像,再解码回向量;
功能刚好相反:从编码向量生成图像,再解码回向量;
4. 如果仅训练生成器![]() 和分类器
和分类器![]() ,生成器会将
,生成器会将![]() 直接附加到输出图像中(导致图像不真,质量有问题),便于分类器
直接附加到输出图像中(导致图像不真,质量有问题),便于分类器![]() 直接还原出
直接还原出![]() ,因此同时训练判别器监督生成图像的真实性。
,因此同时训练判别器监督生成图像的真实性。
VAE GAN:
VAE GAN可以看作用GAN加强VAE,也可以看作用VAE加强GAN,具体结构如下图:

1. 前半部分是一个VAE:数据集中图像向量![]() 通过编码器得到低维向量
通过编码器得到低维向量![]() ,再通过解码器还原为
,再通过解码器还原为![]() 。训练中要让还原尽可能接近,但对于图像向量
。训练中要让还原尽可能接近,但对于图像向量![]() ,单纯的VAE会导致生成的图像是模糊的;
,单纯的VAE会导致生成的图像是模糊的;
2. 后半部分是一个GAN:生成器从向量![]() 产生图像
产生图像![]() ,再由判别器进行真假判断;
,再由判别器进行真假判断;
3. VAE GAN将两者结合在一起,共用解码器/生成器,实现图像的生成。在该结构的训练中,判别器提供了图像真假的限制,使得VAE的重建能产生更清晰/真实的图像;而VAE中得到的![]() 使得生成器的输入不仅仅是完全随机的向量,而是由真实图像编码得到的,相当于多了一个监督信息(原本生成器是看不到真实图像的,只能通过判别器的输出来学习产生图像,而判别器的输出只是一个标量,用来指导高维向量的生成是很艰难的),因此在VAE的重建作用下生成器产生的向量
使得生成器的输入不仅仅是完全随机的向量,而是由真实图像编码得到的,相当于多了一个监督信息(原本生成器是看不到真实图像的,只能通过判别器的输出来学习产生图像,而判别器的输出只是一个标量,用来指导高维向量的生成是很艰难的),因此在VAE的重建作用下生成器产生的向量![]() 会更符合图像的结构。
会更符合图像的结构。
对于VAE GAN,其中三个组件的功能如下图:

编码器要minimize重建误差,同时令![]() 接近正太分布(因为GAN中的z就是从正态分布中取样的,编码器就需要学习将真实图像向量映射到一个服从正态分布的随机向量);解码器/生成器同时也要minimize重建误差,并且使得重建图像骗过判别器(让判别器给高分);判别器需要分辨真实图像,生成图像和重建图像(对判别器来说,重建图像也是假的)。VAE GAN的具体算法如下:
接近正太分布(因为GAN中的z就是从正态分布中取样的,编码器就需要学习将真实图像向量映射到一个服从正态分布的随机向量);解码器/生成器同时也要minimize重建误差,并且使得重建图像骗过判别器(让判别器给高分);判别器需要分辨真实图像,生成图像和重建图像(对判别器来说,重建图像也是假的)。VAE GAN的具体算法如下:

在上面的算法中,判别器仍然是一个二分类器,将![]() 和
和![]() 都视为假图像,给低分即可。另一种判别器结构如上图左边所示,判别器是一个三分类器,将
都视为假图像,给低分即可。另一种判别器结构如上图左边所示,判别器是一个三分类器,将![]() 和
和![]() 进行区分(其实
进行区分(其实![]() 和
和![]() 是不同的,
是不同的,![]() 是根据真实图像重建的,图像结构是更接近
是根据真实图像重建的,图像结构是更接近![]() 的)。可以在代码中改动一下,比较两者的效果。
的)。可以在代码中改动一下,比较两者的效果。
BiGAN:
BiGAN同样是在编码解码的基础上进行改动,不过编码器和解码器不再是串联的结构,如下图:
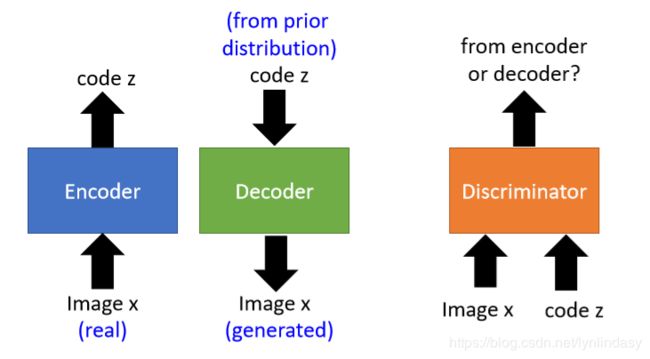
编码器输入真实图片向量,输出编码;解码器输入随机编码向量,输出图像向量。注意:上图中编码器和解码器对应的![]() 和
和![]() 是不同的。这样编码器和解码器其实并无关联,因此借用判别器:其输入是pairs,由图像向量和其对应的编码组成。把编码器和解码器中的
是不同的。这样编码器和解码器其实并无关联,因此借用判别器:其输入是pairs,由图像向量和其对应的编码组成。把编码器和解码器中的![]() 和
和![]() 都组合起来输入,判别器分辨pairs来自于编码器还是解码器(两者差异性可能是:编码器的pairs中,
都组合起来输入,判别器分辨pairs来自于编码器还是解码器(两者差异性可能是:编码器的pairs中,![]() 更符合图像向量的结构;解码器的pairs中,
更符合图像向量的结构;解码器的pairs中,![]() 更服从正态分布。但是判别器的输入是
更服从正态分布。但是判别器的输入是![]() 和
和![]() 啊,应该是会根据两者间的关系进行判别的。或许也可以尝试一下判别器分别判别
啊,应该是会根据两者间的关系进行判别的。或许也可以尝试一下判别器分别判别![]() 或
或![]() 的效果。到这里,感觉判别器之前用来单纯判别
的效果。到这里,感觉判别器之前用来单纯判别![]() ,现在 判别
,现在 判别![]() 和
和![]() 的pairs,能否用来判别
的pairs,能否用来判别![]() 或者其他东西呢?)。BiGAN的具体算法如下图:
或者其他东西呢?)。BiGAN的具体算法如下图:

两次采样:从真实图片数据集中采样![]() 个真实图像
个真实图像![]() ,输入编码器生成假编码
,输入编码器生成假编码![]() ;从先验分布
;从先验分布![]() 中采样
中采样![]() 个真实编码
个真实编码![]() ,输入解码器生成假图像向量
,输入解码器生成假图像向量![]() 。将图像向量和对应的编码组成pairs,输入判别器中。训练判别器令其给来自编码器的pairs高分,来自解码器的pairs低分(这个高低分的选择应该是随意的,感觉这里的编码器和解码器其实都是生成器的作用,不过一个是生成高维向量,一个生成低维向量。不过难易程度有没有区别呢,比如从高维生成低维更容易些?这可不可以作为判别器给谁高分低分的依据呢?)。然后再训练编码器和解码器,这里目标函数和判别器是相反的(为了骗过判别器)。
。将图像向量和对应的编码组成pairs,输入判别器中。训练判别器令其给来自编码器的pairs高分,来自解码器的pairs低分(这个高低分的选择应该是随意的,感觉这里的编码器和解码器其实都是生成器的作用,不过一个是生成高维向量,一个生成低维向量。不过难易程度有没有区别呢,比如从高维生成低维更容易些?这可不可以作为判别器给谁高分低分的依据呢?)。然后再训练编码器和解码器,这里目标函数和判别器是相反的(为了骗过判别器)。
那么BiGAN为什么如此设计呢?判别器的作用一直是用来找两个分布间的差异(真实图像和生成图像向量分布间的散度),在BiGAN中判别器的输入是来自两个地方(编码器和解码器)的pairs,就是在找这两个地方的pairs分别服从的分布间的差异,再让两者差异变小,分布逐渐接近(所谓的分布是pairs的分布,其实就是![]() 和对应的
和对应的![]() 的联合分布)。
的联合分布)。
不过为什么要靠近这两个联合分布呢?每个联合分布中都有一个变量是假的(编码器中![]() 是假的,解码器中
是假的,解码器中![]() 是假的),但是我们是没有真的
是假的),但是我们是没有真的![]() 和
和![]() 组成的pairs的,因为真实图像数据集和先验分布
组成的pairs的,因为真实图像数据集和先验分布![]() 的采样是不对应的。所以这个靠近两个联合分布的过程是不是相当于间接地组成比较真实合理的配对(
的采样是不对应的。所以这个靠近两个联合分布的过程是不是相当于间接地组成比较真实合理的配对(![]() ,
,![]() )呢?合理的
)呢?合理的![]() pairs其实就是好的生成器啊,就是GAN的目标。
pairs其实就是好的生成器啊,就是GAN的目标。
课程中的解释:
靠近两个联合分布,达到最优状态时的编码器和解码器功能如下图:
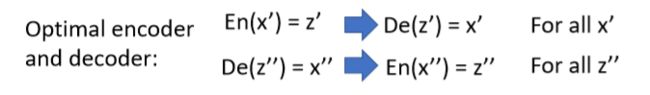
两者是完美的逆过程(训练中就相当于在训练一个![]() ,同时也训练其相反的结构,如下图左边所示),训练后就会得到一个完美的
,同时也训练其相反的结构,如下图左边所示),训练后就会得到一个完美的![]() ,那为什么不直接训练一个
,那为什么不直接训练一个![]() 呢?注意上面说的情况是达到最优状态时两者效果相当,即两者的全局最优值相同,如下图右边所示:
呢?注意上面说的情况是达到最优状态时两者效果相当,即两者的全局最优值相同,如下图右边所示:
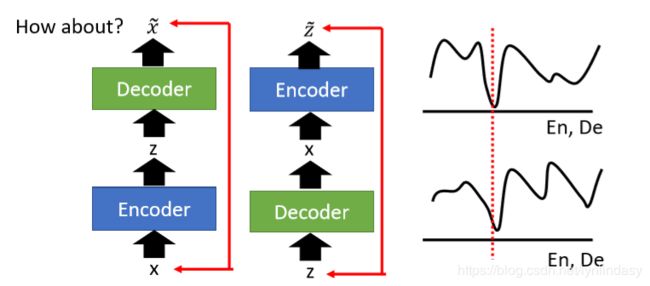
但是单纯的![]() 在训练中是无法达到最优值的,所以这两种方法的结果是不一样的:仅利用
在训练中是无法达到最优值的,所以这两种方法的结果是不一样的:仅利用![]() 重建的图像总是模糊的,而且语义内容是不变的;但BiGAN产生的结果就是清晰而且内容不同的图像(这才有生成的意义)。
重建的图像总是模糊的,而且语义内容是不变的;但BiGAN产生的结果就是清晰而且内容不同的图像(这才有生成的意义)。
可不可以理解为:![]() 训练只是找输入
训练只是找输入![]() 对应的
对应的![]() ,这个
,这个![]() 要能够最好地重建
要能够最好地重建![]() 。所以这个
。所以这个![]() 只是根据输入
只是根据输入![]() 产生的,完全依赖于该
产生的,完全依赖于该![]() ;而BiGAN中,编码解码分开,都加入了随机性(编码器中产生的
;而BiGAN中,编码解码分开,都加入了随机性(编码器中产生的![]() 是无限制的,解码器中产生的
是无限制的,解码器中产生的![]() 是没有真实图像限制的),随机性一定程度上是不是可以理解为“生成”。所以BiGAN既保留了随机性,又保证了编码解码的重建性。
是没有真实图像限制的),随机性一定程度上是不是可以理解为“生成”。所以BiGAN既保留了随机性,又保证了编码解码的重建性。
Triple GAN:
Triple GAN结构如下图:由生成器G,判别器D和分类器C组成。

如果没有分类器C,Triple GAN就是一个普通的Conditional GAN。Triple GAN是一个半监督学习(semi-supervised learning)模型:少量的标记数据,大量的无标签数据,对应到Conditional GAN中就是少量图像有condition,即上图中的pairs![]() ,大量数据无
,大量数据无![]() 。Triple GAN中,将少量的pairs用来训练分类器,使其学会给
。Triple GAN中,将少量的pairs用来训练分类器,使其学会给![]() 分类,得到标签
分类,得到标签![]() 。同时生成器可以从输入的pairs
。同时生成器可以从输入的pairs![]() 中得到该
中得到该![]() 对应的
对应的![]() ,也作为训练集训练分类器,相当于扩充数据。然后判别器将判别pairs来自于分类器,真实数据还是生成器。
,也作为训练集训练分类器,相当于扩充数据。然后判别器将判别pairs来自于分类器,真实数据还是生成器。
Domain-adversarial training:
假设训练集中的数据和测试集数据属于不同的Domain(有一些差别),可能我们的模型预测效果就会不理想,如下图所示:

训练集图片是黑白的,然而测试集却是彩色的,可以作如下改进:

加入生成器,将训练集和测试集的图像通过生成器提取特征,让特征服从相同的分布(有点common space的感觉),整体结构如下图:

首先生成器(感觉在这里就是个编码器)对输入的图像提取特征,特征输入Domain classifier(其实也是判别器)对所属Domain进行判断,训练中要让其分类准确度越来越高,同时特征也输入Label predictor预测图片标签,训练中让标签预测越来越准确。这样生成器就有两个目标,提取出的特征要保证图像语义信息保留(Label predictor的准确性),还要保证能够轻易区分出属于哪个Domain(Domain classifier的准确性)。