【python】linux下自制简易爬虫开发总结(持续更新中)
【1.我为什么选择以爬虫入门python】
首先python开发爬虫的优越性我自不多说,对于深受C++语法折磨的初级程序员来说,想要快速实现功能,选择python妥妥的。同时python的爬虫库也是非常便利(除了安装库时稍费点事),如Scrapy、urllib 。但为了实现功能的同时,顺便熟悉Python语言,这里我们用基本的request+beautifulsoap来编写爬虫。
【2.request是什么,beautifulsoap又是什么】
结合今天要讲的爬虫,就两句话解释(具体请自行百度):
request:能够解析绝大部分http的请求
beautifulsoap:提供丰富的库函数支持你从网页抓取数据
【3.开发环境】
本文中的开发环境是linux,python包是python3.5。(安装的方法请自行百度)
【4.简易爬虫的开发思路】
简易的爬虫分为三个部分:
第一,创建连接,登录,有些网站需要你伪装成浏览器登录,并将第一个url放入待抓取的队列。
第二,扫描网页,解析并抓取数据,根据你的需要,将不同的数据放入到不同的已抓取队列中。循环往复,注意判断抓取到的数据是否已经在队列中存在,避免重复抓取。
第三,处理队列中的数据,如下载图片,存日志等,(该步骤可以放在第二步中,如果爬大站点,这样做会让你实时看到抓取的数据,但同时也会影响爬虫的效率。)
大概的思路很简单易懂,自己做的话封函数可能会稍稍费点事。
【5.爬虫中涉及到的几个小点】
这部分是写给初学者看的,对于一些未接触过的库和api,这里写了几个小demo进行测试,毕竟没有测过直接整合到一起,到最后疯狂的报错会让人抓狂。
5.1 日志模块
python有一些让我很疑惑的地方,也希望又看到的朋友帮忙解答:
槽点!!!为什么有些模块,单个入参很简单,多个入参的时候却显得有些繁琐。日志模块就是其中之一。
当你的程序中只有一个日志输出的时候。可以直接定义如下:
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(name)-12s %(levelname)-8s %(message)s',
datefmt='%m-%d %H:%M',
filename='myapp.log',
filemode='w'
)
定义日志的输出格式,内容,级别,名字和读写权限。
定义多个日志输出时,这种方法就不适用了,代码如下:
5.2 下载网络图片到本地
这里主要是要利用os设置文件的路径,同时这里添加了判断是否已存在该文件路径。
5.3 线程池
如果有兴趣,可以尝试一下,使用线程池和不使用线程池的差别。
(由于多参数的情况还没研究出来,搞得没耐心了,就直接用for循环创造线程了)
5.4 beautifulsoap测试
from bs4 import BeautifulSoup
import requests
import logging
#定义线程爬取网址
logging.info('开始爬虫了')
#建立一个永久会话
my_session = requests.session()
#定义初始网址
initial_page = "http://wufazhuce.com/one/1293"
#定义一个伪装成浏览器的头
my_header = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0"
#使用get方法发生请求,post方式可以添加header伪装登录方式
try:
result_get = my_session.get(initial_page)
except:
print("这个网址访问异常==============" + current_url)
try:
soup = BeautifulSoup(result_get.text, "html.parser")
except :
print("构建beautifulSoup失败===========" + initial_page)
Soup_f_b = soup.find('body')
if Soup_f_b == None:
logging.info("该Url没有body属性============" + current_url)
#list_img = Soup_f_b.findAll('img', attr = {'src',True})
list_img = Soup_f_b.select("img[alt]")
for meta in list_img:
print(meta.get('src'))
#url_list = Soup_f_b.findAll('a', attrs = {'href':True})
#url_list = Soup_f_b.select("a")
#for meta in url_list:
# print(meta.get('href'))
#print(url_list)
#name_list = soup.select("meta[itemprop='description']")
#name_content = name_list[0].get('content')
#for meta in Soup_f_b.select('meta'):
# if meta.get('name') == 'description':
#print(name_content)
print(soup.title)
本次程序爬行的是ONE,测试结果如下所示:

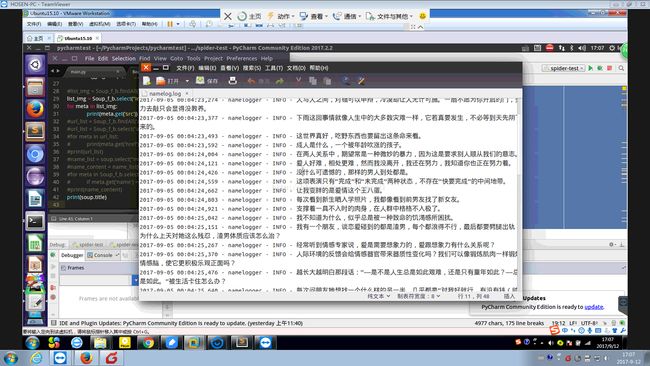
其实把上面的几个demo凑在一起,爬虫的大致框架就出来了,但有几点需要注意一下:
1.在使用多线程的时候,注意在操作队列时,要加锁,防止多线程同时写操作。
2.注意python2.x和python3.x的区别,类似SyntaxError: invalid syntax,这种错误可能是版本差别引起。
【说在最后】
第一个版本详细代码我会放在github上,会持续修补,地址稍后补上。
对于文章提到的吐槽点,也请各位看到的朋友,帮忙解答,不胜感激。
运行效率上我还没有做优化,因此后续也希望各位牛人提供宝贵意见。