机器学习算法与Python实践(8) - 稀疏约束 LASSO(L1)
稀疏约束-sklearn.Lasso() L1
功能:
Least Absolute Shrinkage and Selection Operator(LASSO)又称线性回归的L1正则,该方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。Lasso 在学习过程中可以直接将部分 feature 系数赋值为 0 的特点使其在调参时非常方便。
在 Python 中,Lasso 是 sklearn 包下的一个典型 Model。sklearn 中主要包含 Lasso 及 Ridge 模型。二者具体区别可参见此处。林轩田机器学习基石 14-4 General Regularizers(13-28)有具体讲解。
其中,主要关注参数为 alpha,其作用与 sklearn 包下的另一模型 Ridge 类似,是一个衡量模型灵活度的正则参数。正则度越高,越不可能 overfit。但是它也会导致模型灵活度的降低,可能无法捕捉数据中的所有信号。
通过 Lasso 自带的 CV(Cross Validation)设置,可以直接通过机器挑选最好的 alpha。
语法:
- 通过内置函数挑选 alpha:
model_lasso = LassoCV(alphas = [1, 0.1, 0.001, 0.0005]).fit(X_train, y) # 此处 alpha 为通常值 #fit 把数据套进模型里跑
- 通过 Lasso 选择 feature,并展示系数不为 0 的 feature 个数:
coef = pd.Series(model_lasso.coef_, index = X_train.columns)# .coef_ 可以返回经过学习后的所有 feature 的参数。
print("Lasso picked " + str(sum(coef != 0)) + " variables and eliminated the other " + str(sum(coef == 0)) + " variables")但这里有一点要注意:被选出来的 features 不一定是“正确”的 features——尤其是在这个数据集里有很多 features 是同线的。有一种做法是在 boostrapped samples 上多跑几次 Lasso,看 feature 选择的稳定程度。也可以直接看一下最重要的系数都是哪些:
imp_coef = pd.concat([coef.sort_values().head(10),
coef.sort_values().tail(10)])#选头尾各10条,.sort_values() 可以将某一列的值进行排序。
matplotlib.rcParams['figure.figsize'] = (8.0, 10.0)
imp_coef.plot(kind = "barh")
plt.title("Coefficients in the Lasso Model")下图为筛选后的 20 个 feature:(重要系数)
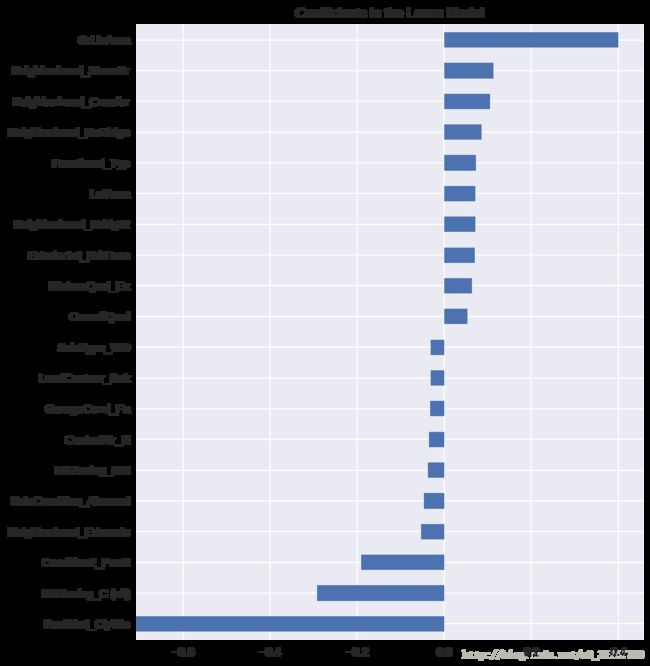
在房屋价格预测中,最重要的正向 feature 是 GrLivArea——地上部分的面积。这个肯定说得通。还有其他的地点和质量 feature 也是正向的。一部分负向的 feature 不太说得通,需要进一步观察——它们可能是由不平衡的分类型变量引起的。
还需要注意的是,不像 feature importance 可以直接从 random forest 里得到,这些参数是模型里真正的参数——所以你可以很明确地知道为什么预测出的会是这个价格。唯一的问题就是我们把目标和数字 feature 都 log 转换了,所以实际的数量级有点难判断。
- 检查 residuals(预测误差,预测值-实际值)
#let's look at the residuals as well:
matplotlib.rcParams['figure.figsize'] = (6.0, 6.0)#图片大小 6*6
preds = pd.DataFrame({"preds":model_lasso.predict(X_train), "true":y}) #.predict() 返回括号内输入的数据集的预测值。predict:预测结果,y:实际结果,二者之差为 residual
preds["residuals"] = preds["true"] - preds["preds"]
preds.plot(x = "preds", y = "residuals",kind = "scatter")
下图显示的是:residual plot
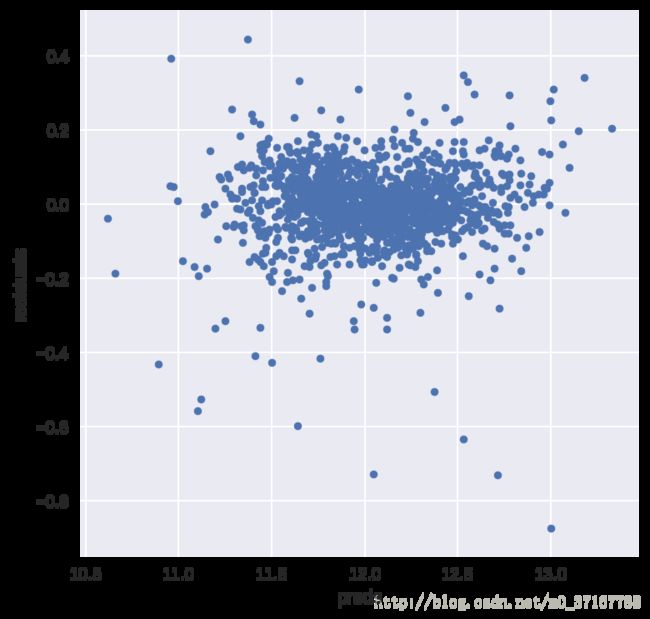
理想的所有残差应在 0 左右随机波动,并且变化幅度在一条带内。本图大致符合此特点,因此说明此次学习模型效果较好。
主要参数!
1.alpha : float, 可选,默认 1.0。
当 alpha 为 0 时算法等同于普通最小二乘法,可通过 Linear Regression 实现,因此不建议将 alpha 设为 0.2.fit_intercept : boolean
是否进行拦截计算(intercept)。若 false,则不计算(比如数据已经经过集中了)。此处不太明白,仿佛与偏度有关。3.normalize : boolean, 可选, 默认 False
若 True,则先 normalize 再 regression。若 fit_intercept 为 false 则忽略此参数。当 regressors 被 normalize 的时候,需要注意超参(hyperparameters)的学习会更稳定,几乎独立于 sample。对于标准化的数据,就不会有此种情况。如果需要标准化数据,请对数据预处理。然后在学习时设置 normalize=False。4.copy_X : boolean, 可选, 默认 True
若 True,则会复制 X;否则可能会被覆盖。5.precompute : True | False | array-like, 默认=False
是否使用预计算的 Gram 矩阵来加速计算。如果设置为 ‘auto’ 则机器决定。Gram 矩阵也可以 pass。对于 sparse input 这个选项永远为 True。6.max_iter : int, 可选
最大循环次数。7.tol : float, 可选
优化容忍度 The tolerance for the optimization: 若更新后小于 tol,优化代码检查优化的 dual gap 并继续直到小于 tol 为止。8.warm_start : bool, 可选
为 True 时, 重复使用上一次学习作为初始化,否则直接清除上次方案。9.positive : bool, 可选
设为 True 时,强制使系数为正。10.selection : str, 默认 重点内容= ‘cyclic’
若设为 ‘random’, 每次循环会随机更新参数,而按照默认设置则会依次更新。设为随机通常会极大地加速交点(convergence)的产生,尤其是 tol 比 1e-4 大的情况下。11.random_state : int, RandomState instance, 或者 None (默认值)
pseudo random number generator 用来产生随机 feature 进行更新时需要用的
seed。仅当 selection 为 random 时才可用。