python-爬虫(1)requests模块
什么是爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
爬虫的基本架构
Python爬虫架构
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
浏览网页的过程中发生了什么
- 浏览器输入http://www.baidu.com/bbs/;
- 1). 根据配置的DNS获取www.baidu.com对应的主机IP;
- 2). 根据端口号知道跟服务器的那个软件进行交互。
- 3). 百度的服务器接收客户端请求:
- 4). 给客户端主机一个响应(html内容) ----- html, css, js
- 5). 浏览器根据html内容解释执行, 展示出华丽的页面;
简单爬虫
url规律:
https://tieba.baidu.com/p/5752826839?pn=1
https://tieba.baidu.com/p/5752826839?pn=2
https://tieba.baidu.com/p/5752826839?pn=3
图片html分析:
< img class=“BDE_Image” src=“https://imgsa.baidu.com/forum/w%3D580/sign=8be466fee7f81a4c2632ecc1e7286029/bcbb0d338744ebf89d9bb0b5d5f9d72a6259a7aa.jpg"size="350738” changedsize="true"width=“560” height=“995”>
通过对url的规律进行分析,和图片的html进行分析,查找到关键需要爬取的关键信息
from urllib.request import urlopen
from urllib.error import URLError
import re
def get_page(url):
"""
获取页面内容
:param url:
:return:
"""
try:
urlObj = urlopen(url)
except URLError as e:
print("爬取%s失败...." % (url))
else:
# 默认是bytes类型, 需要的是字符串, 二进制文件不能decode
content = urlObj.read()
return content
def parser_content(content):
"""
解析页面内容, 获取所有的图片链接
:param content:
:return:
"""
content = content.decode('utf-8').replace('\n', ' ')
pattern = re.compile(r') ')
imgList = re.findall(pattern, content)
return imgList
def get_page_img(page):
url = "https://tieba.baidu.com/p/5752826839?pn=%s" %(page)
content = get_page(url)
print(content)
# with open('tieba.html', 'w') as f:
# f.write(content)
if content:
imgList = parser_content(content)
for imgUrl in imgList:
# 依次遍历图片的每一个链接, 获取图片的内容;
imgContent = get_page(imgUrl)
# https://imgsa.baidu.com/forum/w%3D580/sign=a05cc58f2ca446237ecaa56aa8237246/94cd6c224f4a20a48b5d83329c529822700ed0e4.jpg
imgName = imgUrl.split('/')[-1]
with open('img/%s' %(imgName), 'wb') as f:
f.write(imgContent)
print("下载图片%s成功...." %(imgName))
if __name__ == '__main__':
for page in range(1, 11):
print("正在爬取第%s页的图片...." %(page))
get_page_img(page)
')
imgList = re.findall(pattern, content)
return imgList
def get_page_img(page):
url = "https://tieba.baidu.com/p/5752826839?pn=%s" %(page)
content = get_page(url)
print(content)
# with open('tieba.html', 'w') as f:
# f.write(content)
if content:
imgList = parser_content(content)
for imgUrl in imgList:
# 依次遍历图片的每一个链接, 获取图片的内容;
imgContent = get_page(imgUrl)
# https://imgsa.baidu.com/forum/w%3D580/sign=a05cc58f2ca446237ecaa56aa8237246/94cd6c224f4a20a48b5d83329c529822700ed0e4.jpg
imgName = imgUrl.split('/')[-1]
with open('img/%s' %(imgName), 'wb') as f:
f.write(imgContent)
print("下载图片%s成功...." %(imgName))
if __name__ == '__main__':
for page in range(1, 11):
print("正在爬取第%s页的图片...." %(page))
get_page_img(page)

反爬虫第一步
在我们进行爬取数据时会遇到爬取不到的情况,是因为有些网站的反爬虫要求必须是浏览器才能访问,所以我们需要进行模拟浏览器
from urllib.error import URLError
from urllib.request import urlopen
from urllib import request
url = "http://www.cbrc.gov.cn/chinese/jrjg/index.html"
user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
reqObj = request.Request(url, headers={'User-Agent': user_agent})
content = urlopen(reqObj).read().decode('utf-8')
print(content)
在网页的审查元素中找到User-Agent
反爬虫模拟浏览器-实现爬取银行信息
为防止一个浏览器访问频繁被封掉,我们可以在网上查找一些浏览器信息
import random
import re
from urllib.request import urlopen, Request
from urllib.error import URLError
def get_content(url):
"""获取页面内容, 反爬虫之模拟浏览器"""
# 防止一个浏览器访问频繁被封掉;
user_agents = [
"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0",
"Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19",
"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0",
]
try:
# reqObj = Request(url, headers={'User-Agent': user_agent})
reqObj = Request(url)
# 动态添加爬虫请求的头部信息, 可以在实例化时指定, 也可以后续通过add—header方法添加
reqObj.add_header('User-Agent', random.choice(user_agents))
except URLError as e:
print(e)
return None
else:
content = urlopen(reqObj).read().decode('utf-8').replace('\t', ' ')
return content
def parser_content(content):
"""解析页面内容, 获取银行名称和官网URL地址"""
pattern = r'\s+(.*)\s+'
bankinfos = re.findall(pattern, content)
if not bankinfos:
raise Exception("没有获取符合条件的信息")
else:
return bankinfos
def main():
url = "http://www.cbrc.gov.cn/chinese/jrjg/index.html"
content = get_content(url)
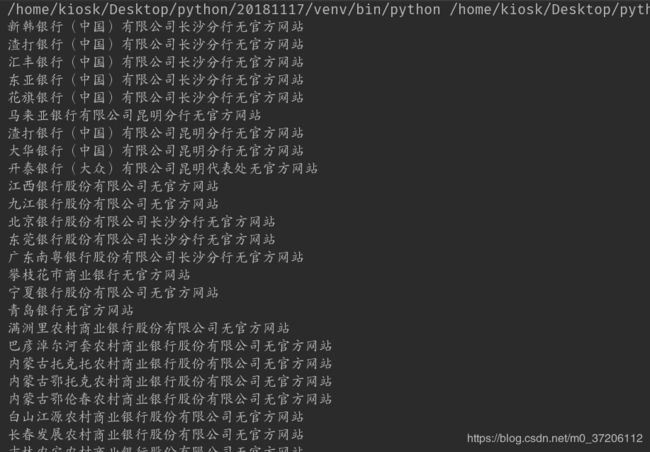
bankinfos = parser_content(content)
with open('doc/bankinfo.txt', 'w') as f:
# ('http://www.cdb.com.cn/', '国家开发银行\r')
for bank in bankinfos:
name = bank[1].rstrip()
url = bank[0]
# 根据正则判断银行的url地址是否合法, 如果合法才写入文件;
pattern = r'^((https|http|ftp|rtsp|mms)?:\/\/)\S+'
if re.search(pattern, url):
f.write('%s: %s\n' %(name, url))
else:
print("%s无官方网站" %(name))
print("写入完成....")
if __name__ == '__main__':
main()


反爬虫设置代理
Ip代理
1.为什么?
2. 如何防止IP被封?
- 设置延迟: time.sleep(random.randint(1,3))
- 使用IP代理, 让其他的IP代替你的IP访问页面;
- 如何获取代理IP?
https://www.xicidaili.com/ (西刺代理网站提供)
#ProxyHandler ======> Request()
#Opener ====== urlopen()
#安装Opener
#4. 如何检测代理是否成功? http://httpbin.org/get
选择代理IP时 要选择的存活时间长的IP 否则可能会失败
from urllib.request import ProxyHandler, build_opener, install_opener, urlopen
from urllib import request
def use_proxy(proxies, url):
# 1. 调用urllib.request.ProxyHandler
proxy_support = ProxyHandler(proxies=proxies)
# 2. Opener 类似于urlopen
opener = build_opener(proxy_support)
# 3. 安装Opener
install_opener(opener)
# user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
# user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
user_agent = 'Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3'
# 模拟浏览器;
opener.addheaders = [('User-agent', user_agent)]
urlObj = urlopen(url)
content = urlObj.read().decode('utf-8')
return content
if __name__ == '__main__':
url = 'http://httpbin.org/get'
proxies = {'https': "111.177.178.167:9999", 'http': '114.249.118.221:9000'}
use_proxy(proxies, url)
保存cookie信息
cookie是某些网站为了辨别用户身份, 只有登陆某个页面才可以访问;
登陆信息保存方式: 进行一个会话跟踪(session),将用户的相关信息保存到本地的浏览器中;
from collections import Iterable
from urllib.parse import urlencode
from urllib.request import HTTPCookieProcessor
from http import cookiejar
from urllib import request
**************************1. 获取cookie信息保存到变量**********************
# CookieJar ------> FileCookieJar ---> MozilaCookie
# 1. 声明一个类, 将cookie信息保存到变量中;
cookie = cookiejar.CookieJar()
# 2. 通过urllib.request的 HTTPCookieProcessor创建cookie请求器;
handler = HTTPCookieProcessor(cookie)
# 3). 通过处理器创建opener; ==== urlopen
opener = request.build_opener(handler)
# 4). 打开url页面
response = opener.open('http://www.baidu.com')
# print(cookie)
print(isinstance(cookie, Iterable))
for item in cookie:
print("Name=" + item.name, end='\t\t')
print("Value=" + item.value)
**************************2. 获取cookie信息保存到本地文件**********************
# 1). 指定年cookie文件存在的位置;
cookieFilenName = 'doc/cookie.txt'
# 2). 声明对象MozillaCookieJar, 用来保存cookie到文件中;
cookie = cookiejar.MozillaCookieJar(filename=cookieFilenName)
# 3). 通过urllib.request的 HTTPCookieProcessor创建cookie请求器;
handler = HTTPCookieProcessor(cookie)
# 4). 通过处理器创建opener; ==== urlopen
opener = request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
#保存到本地文件中;
cookie.save(cookieFilenName)
*****************3. 从文件中获取cookie并访问********************************
#1). 指定cookie文件存在的位置;
cookieFilenName = 'doc/cookie.txt'
#2). 声明对象MozillaCookieJar, 用来保存cookie到文件中;
cookie = cookiejar.MozillaCookieJar()
#*****添加一步操作, 从文件中加载cookie信息
cookie.load(cookieFilenName)
# 3). 通过urllib.request的 HTTPCookieProcessor创建cookie请求器;
handler = HTTPCookieProcessor(cookie)
#4). 通过处理器创建opener; ==== urlopen
opener = request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
#**********************************4. 利用cookie模拟登陆网站的步骤**********************************
#*******************模拟登陆, 并保存cookie信息;
cookieFileName = 'cookie01.txt'
cookie = cookiejar.MozillaCookieJar(filename=cookieFileName)
handler = HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
#这里的url是教务网站登陆的url;
loginUrl = 'xxxxxxxxxxxxxx'
postData = urlencode({
'stuid': '1302100122',
'pwd': 'xxxxxx'
})
response = opener.open(loginUrl, data=postData)
cookie.save(cookieFileName)
#bs4
#******************根据保存的cooie信息获取其他网页的内容eg: 查成绩/选课
gradeUrl = ''
response = opener.open(gradeUrl)
print(response.read())
案例–利用cookie信息登录chinaunix网站
from http import cookiejar
from urllib import request
from urllib.parse import urlencode
from urllib.request import HTTPCookieProcessor
cookieFileName = 'doc/chinaUnixCookie.txt'
cookie = cookiejar.MozillaCookieJar(filename=cookieFileName)
handler = HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
# 这里的url是chinaunix登陆的url;
loginUrl = 'http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=La2A2'
# 易错: POST data should be bytes, an iterable of bytes, or a file object.
postData = urlencode({
'username': '*****',
'password': '*************'
}).encode('utf-8')
print(type(postData))
response = opener.open(loginUrl, data=postData)
print(response.code)
with open('doc/chinaunix.html', 'wb') as f:
f.write(response.read())
# cookie.save(cookieFileName)
这里的用户名和密码均为自己设置的,打开是生成的html文件,即有如下显示


urllib模块里面的异常
pyhton3中把urllib2里面的方法封装到urllib.request;
https://docs.python.org/3/library/urllib.html
HTTP常见的状态码有哪些:
2xxx: 成功
3xxx: 重定向
4xxx: 客户端的问题
5xxxx: 服务端的问题
404: 页面找不到
403: 拒绝访问
200: 成功访问
1 消息
▪ 100 Continue
▪ 101 Switching Protocols
▪ 102 Processing
2 成功
▪ 200 OK
▪ 201 Created
▪ 202 Accepted
▪ 203 Non-Authoritative Information
▪ 204 No Content
▪ 205 Reset Content
▪ 206 Partial Content
▪ 207 Multi-Status
3 重定向
▪ 300 Multiple Choices
▪ 301 Moved Permanently
▪ 302 Move temporarily
▪ 303 See Other
▪ 304 Not Modified
▪ 305 Use Proxy
▪ 306 Switch Proxy
▪ 307 Temporary Redirect
4 请求错误
▪ 400 Bad Request
▪ 401 Unauthorized
▪ 402 Payment Required
▪ 403 Forbidden
▪ 404 Not Found
▪ 405 Method Not Allowed
▪ 406 Not Acceptable
▪ 407 Proxy Authentication Required
▪ 408 Request Timeout
▪ 409 Conflict
▪ 410 Gone
▪ 411 Length Required
▪ 412 Precondition Failed
▪ 413 Request Entity Too Large
▪ 414 Request-URI Too Long
▪ 415 Unsupported Media Type
▪ 416 Requested Range Not Satisfiable
▪ 417 Expectation Failed
▪ 421 too many connections
▪ 422 Unprocessable Entity
▪ 423 Locked
▪ 424 Failed Dependency
▪ 425 Unordered Collection
▪ 426 Upgrade Required
▪ 449 Retry With
▪ 451Unavailable For Legal Reasons
5 服务器错误
▪ 500 Internal Server Error
▪ 501 Not Implemented
▪ 502 Bad Gateway
▪ 503 Service Unavailable
▪ 504 Gateway Timeout
▪ 505 HTTP Version Not Supported(http/1.1)
▪ 506 Variant Also Negotiates
▪ 507 Insufficient Storage
▪ 509 Bandwidth Limit Exceeded
▪ 510 Not Extended
▪ 600 Unparseable Response Headers
from urllib import request
from urllib import error
try:
url = 'http://www.baidu.com/hello.html'
response = request.urlopen(url, timeout=0.01)
except error.HTTPError as e:
print(e.code, e.headers, e.reason)
except error.URLError as e:
print(e.reason)
else:
content = response.read().decode('utf-8')
print(content[:5])
requests模块
requests模块爬取页面内容
import requests
from urllib.error import HTTPError
def get_content(url):
try:
response = requests.get(url)
response.raise_for_status() # 如果状态码不是200, 引发HttpError异常
# 从内容分析出响应内容的编码格式
response.encoding = response.apparent_encoding
except HTTPError as e:
print(e)
else:
print(response.status_code)
# print(response.headers)
return response.text
if __name__ == '__main__':
url = 'http://www.baidu.com'
get_content(url)
状态码正常

requests模块之京东商品信息的爬取
import requests
from urllib.error import HTTPError
def get_content(url):
try:
response = requests.get(url)
response.raise_for_status() # 如果状态码不是200, 引发HttpError异常
# 从内容分析出响应内容的编码格式
response.encoding = response.apparent_encoding
except HTTPError as e:
print(e)
else:
print(response.status_code)
# print(response.headers)
# return response.text # 返回的是字符串
return response.content # 返回的是bytes类型, 不进行解码
if __name__ == '__main__':
url = 'https://item.jd.com/6789689.html'
content = get_content(url)
with open('doc/jingdong.html', 'wb') as f:
f.write(content)
爬取成功后打开生成的html文件

requests模块之亚马逊商品页面信息的爬取
import random
import requests
from urllib.error import HTTPError
# 如何去模拟浏览器访问?
def get_content(url):
try:
user_agents = [
"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0",
"Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19",
"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0",
]
response = requests.get(url, headers={'User-Agent': random.choice(user_agents)})
response.raise_for_status() # 如果状态码不是200, 引发HttpError异常
# 从内容分析出响应内容的编码格式
response.encoding = response.apparent_encoding
except HTTPError as e:
print(e)
else:
print(response.status_code)
# print(response.headers)
# return response.text
return response.content
if __name__ == '__main__':
# url = 'https://www.amazon.cn/dp/B01ION3VWI'
url = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
content = get_content(url)
with open('doc/bank.html', 'wb') as f:
f.write(content)
运行程序后打开生成的html文件

requests模块提交数据到服务器
import requests
# Http常见的请求方法:
# GET:
# post:
# 1.
response = requests.get('http://www.baidu.com')
print(response.text)
# 2.
# # http://httpbin.org/post
response = requests.post('http://httpbin.org/post',
data={'name':'fentiao', 'age':10})
print(response.text)
# 3.
response = requests.delete('http://httpbin.org/delete', data={'name':'fentiao'})
print(response.text)
# 4. GET方法:带参数get请求
# url1 = 'https://movie.douban.com/subject/4864908/comments?start=20&limit=20&sort=new_score&status=P'
url = 'https://movie.douban.com/subject/4864908/comments'
data = {
'start':20,
'limit':40,
'sort':'new_score',
'status': 'P'
}
response = requests.get(url, params=data)
print(response.text)
print(response.url)
百度和360搜索关键字的提交
import requests
def keyword_post(url, data):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, params=data, headers={'User-Agent': user_agent})
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
print(response.url)
print("爬取成功!")
return response.content
def baidu():
url = "https://www.baidu.com/s"
keyword = input("请输入搜索的关键字:")
# wd是百度需要
data = {
'wd': keyword
}
keyword_post(url, data)
def search360():
url = "https://www.so.com/s"
keyword = input("请输入搜索的关键字:")
# wd是百度需要
data = {
'q': keyword
}
content = keyword_post(url, data)
with open('360.html', 'wb') as f:
f.write(content)
if __name__ == '__main__':
search360()
baidu()


re quests解析json格式
import json
import requests
# 解析json格式
ip = input('IP:')
url = "http://ip.taobao.com/service/getIpInfo.php"
data = {
'ip': ip
}
response = requests.get(url, params=data)
# 将响应的json数据编码为python可以识别的数据类型;
content = response.json()
print(content)
print(type(content))
country = content['data']['country']
print(country)
# response.content: 返回的是bytes类型, 比如: 下载图片, 视频;
# response.text: 返回的是str类型, 默认情况会将bytes类型转成str类型;

下载指定视频
import requests
def get_content(url):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, headers={'User-Agent': user_agent})
print('a')
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
# print(response.url)
print("爬取成功!")
return response.content # 下载视频需要的是bytes类型
if __name__ == '__main__':
url = 'https://gss0.bdstatic.com/-4o3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=4f7bf38ac3fc1e17fdbf8b3772ab913e/d4628535e5dde7119c3d076aabefce1b9c1661ba.jpg'
# url = "http://gslb.miaopai.com/stream/sJvqGN6gdTP-sWKjALzuItr7mWMiva-zduKwuw__.mp4"
movie_content = get_content(url)
print("正在下载....")
with open('doc/movie.jpg', 'wb') as f:
f.write(movie_content)
print("下载电影完成.....")
因为网速较慢 下载视频需要时间很长 我们用图片做了测试

requests的常见使用
import requests
# # 1). 上传文件files: 指定的文件的内容
data = {
'name':'fentiao'
}
files = {
# 二进制文件需要指定rb
'file': open('doc/movie.jpg', 'rb')
}
response = requests.post(url='http://httpbin.org/post', data = data, files=files)
print(response.text)
# 2). 设置代理
proxies = {
'http':'116.209.58.116:9999',
'https':'115.151.5.40:53128'
}
response = requests.get('http://httpbin.org/get', proxies=proxies, timeout=2)
print(response.text)
# 3). cookie信息的保存, 加载====== 客户端的缓存, 保持客户端和服务端连接会话seesion
seesionObj = requests.session()
# 专门用来设置cookie信息的,
response1 = seesionObj.get('http://httpbin.org/cookies/set/name/westos')
# 专门用来查看cookie信息的网址
response2 = seesionObj.get('http://httpbin.org/cookies')
print(response2.text)
# 专门用来设置cookie信息的,
response1 = requests.get('http://httpbin.org/cookies/set/name/westos')
# 专门用来查看cookie信息的网址
response2 = requests.get('http://httpbin.org/cookies')
print(response2.text)