Hadoop及Hbase安装介绍
Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式基础结构,主要包括HDFS和MapReduce两部分,HDFS是分布式文件系统,MapReduce是一个用于大数据计算的编程模型。从Hadoop 2.0开始,资源调度统一由Yarn进行管理,Yarn由ResourceManager和NodeManager两部分组成。
Hadoop发行版本,主要有Apache发行版和第三方发行版本,比如CDH等,第三方发行版可以很好地兼容其他Hadoop生态圈软件,比如Spark、Hive、HBase等。
生产环境中,我们一般会选择CDH Manager搭建集群,它可以很方便地搭建一个Hadoop集群,易于监控集群,扩展节点方便。
基础环境准备
- 下载JDK8安装包,解压至/usr/java目录下,并设置好环境变量:
vi ~/.bash_profile
export JAVA_HOME=/usr/java/jdk1.8.0_111
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$HOME/bin:$PATH
- 将MySQL驱动拷贝至/usr/share/java目录下,并重命名为mysql-connector-java.jar
- 配置NTP时间同步
yum -y install ntp —— 安装NTP
chkconfig ntpd on —— 开启启动
ntpdate -u s2c.time.edu.cn —— 时间同步
cp -f /usr/share/zoneinfo/Asia/Shanghai /etc/localtime —— 时间设置为东八区
date -R —— 查看当前时区
时间同步配置存在一些问题,并未配置从master同步时间,导致集群环境频繁出现“时钟偏差”异常,这部分后续细化。
- 修改/etc/hosts,设置集群机器别名,例如:
192.168.0.0 master
192.168.0.1 slave1
192.168.0.2 slave2
配置生效:
service network restart - 配置免密登录
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
ssh-copy-id master
以上都在master上操作,然后分发至其他机器,分发实例:
scp /etc/hosts slave1:/etc/
scp ~/.bash_profile slave1:~/
scp ~/.ssh/authorized_keys root@slave1:~/.ssh
scp /usr/share/java/mysql-connector-java.jar slave1:/usr/share/java/
scp –r /usr/java/jdk1.8.0_111 slave1:/usr/java/
- Linux服务器调优
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
sysctl -w vm.swappiness=0 —— 临时调整
cat /proc/sys/vm/swappiness —— 查看结果
echo 'vm.swappiness=0'>> /etc/sysctl.conf —— 重启生效
Cloudera Manager安装
安装指南:https://www.cloudera.com/documentation/enterprise/latest/topics/cm_ig_install_path_b.html
1) 下载cloudera-manager.repo,并拷贝至/etc/yum.repos.d目录下
wget https://archive.cloudera.com/cm5/redhat/7/x86_64/cm/cloudera-manager.repo
2) Master上安装Server
sudo yum -y install cloudera-manager-daemons cloudera-manager-server
vi /etc/default/cloudera-scm-server
export JAVA_HOME=/usr/java/jdk1.8.0_111
3) 安装Agent(所有机器)
sudo yum -y install cloudera-manager-agent cloudera-manager-daemons
vi /etc/cloudera-scm-agent/config.ini
配置server_host and server_port
4) 初始化数据库
/usr/share/cmf/schema/scm_prepare_database.sh mysql -uroot -p123456 --scm-host master scm scm scm
查看数据库配置:
cat /etc/cloudera-scm-server/db.properties
5) 上传CDH parcel至/opt/cloudera/parcel-repo目录
下载地址:https://archive.cloudera.com/cdh5/parcels/5.14.2/
以CentOS7.X为例,下载以下文件:
CDH-5.14.2-1.cdh5.14.2.p0.3-el7.parcel
CDH-5.14.2-1.cdh5.14.2.p0.3-el7.parcel.sha1
manifest.json
并将CDH-5.14.2-1.cdh5.14.2.p0.3-el7.parcel.sha1重命名为
CDH-5.14.2-1.cdh5.14.2.p0.3-el7.parcel.sha
6) 启动Cloudera Manager
启动Cloudera Server:sudo service cloudera-scm-server start(master)
启动Cloudera Agent:sudo service cloudera-scm-agent start(all)
对于Cloudera Server,默认7180为管理端口,7182为和Agent通信端口
管理台地址:http://master:7180 账户/密码:admin/admin
7) 日志调试
Cloudera Server日志:
tail –n 200 /var/log/cloudera-scm-server/cloudera-scm-server.log
Cloudera Agent日志:
tail -n 200 /var/log/cloudera-scm-agent/cloudera-scm-agent.log
安装CDH及Hadoop
预先创建好相关数据库:
create database rm DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
然后登录集群管理台,根据页面进行相关操作:
1) 集群服务器接受Cloudera Manager管理
2) 分发和激活CDH parcel
3) 安装hadoop相关服务,包括ZooKeeper、HDFS、YARN、Hive
4) 配置Hadoop高可用
http://master:50070 —— Hadoop管理台
http://master:8088 —— YARN管理台
Hbase 相关命令
HBase管理页面:http://master:60010
Region Server页面:http://master:60030
hbase shell 进入交互环境
查看所有表:
list
删除表:
disable 't1'
drop 't1'
查看表结构:
describe 't1'
修改表结构:
disable 't1'
alter 'test1',****
enable 't1'
添加数据:
put 'user','100','info:username','bwton'
获取一行数据:
get 'user','6'
get 'user','6','info:password','info:create_time'
或 get 'user','6', {COLUMN=>'info:password'}
扫描表:
scan 'user'
scan 'user',{LIMIT=>5}
查询数据行数:
count 'user', {INTERVAL => 100, CACHE => 500}
INTERVAL :多少行显示一次
CACHE :缓存大小
删除数据:
delete 'user','100','info:username'(删除列)
deleteall 'user','99999'(删除行)
truncate 'user'(删除所有数据)
多版本:
alter 'user',{NAME=>'info',VERSIONS=>3} —— 默认为1
put 'user','100','info:username','lianggl'
put 'user','100','info:username','liuhao'
put 'user','100','info:username','wangqiang'
get 'user','100' —— 显示最新数据
get 'user','100',{COLUMN=>'info:username',VERSIONS=>3}
命名空间:
ist_namespace
list_namespace_tables 'default'
create_namespace 'msx_online'
describe_namespace 'msx_online'
drop_namespace 'msx_online'
Hbase映射到Hive:
CREATE EXTERNAL TABLE sl_station_info(
STATION_ID BIGINT,
STATION_NAME STRING,
CITY_ID INT
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key, info:STATION_NAME , info:CITY_ID")
TBLPROPERTIES("hbase.table.name" = "sl_station_info");
Phoenix安装使用
- 下载对应版本的phoenix parcel,下载http://archive.apache.org/dist/phoenix/apache-phoenix-4.14.0-cdh5.14.2/parcels/
APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3-el7.parcel
manifest.json
新建APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3-el7.parcel.sha
并将manifest.json中相应的hash复制到该文件中
将文件一并上传到/opt/cloudera/parcel-repo目录
然后重启Cloudera Manager Server:
service cloudera-scm-server restart
将phoenix parcel分发至各节点并激活 - HBase配置
hbase.table.sanity.checks false
将phoenix JAR包拷贝至HBase lib目录(所有节点):
cp /opt/cloudera/parcels/APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3/lib/phoenix /opt/cloudera/parcels/CDH/lib/hbase/lib
重启HBase - 拷贝phoenix至其他目录并设置环境变量
cp -r /opt/cloudera/parcels/APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3/lib/phoenix
/opt/app/
vi ~/.bash_profile
export PHOENIX_HOME=/opt/app/phoenix - 进入phoenix
$PHOENIX_HOME/bin/sqlline.py master,slave1,slave2:2181 - HBase表映射到phoenix
在phoenix中创建同名表
create view
create table - 常用命令
!tables —— 查询所有表
!describe table_name —— 查询表结构
!quit —— 退出 - 删除phoenix映射(不影响Hbase)
DELETE from SYSTEM.CATALOG where TABLE_NAME =‘mapped_table_name’ - 执行计划
| Name | Description |
|---|---|
| AGGREGATE INTO ORDERED DISTINCT ROWS | aggregates the returned rows using an operation such as addition. When ORDERED is used, the GROUP BY operation is applied to the leading part of the primary key constraint, which allows the aggregation to be done in place rather than keeping all distinct groups in memory on the server side |
| AGGREGATE INTO SINGLE ROW | aggregates the results into a single row using an aggregate function with no GROUP BY clause. For example, the count() statement returns one row with the total number of rows that match the query |
| CLIENT | the operation will be performed on the client side. It’s faster to perform most operations on the server side, so you should consider whether there’s a way to rewrite the query to give the server more of the work to do |
| FILTER BY | expression—returns only results that match the expression |
| FULL SCAN OVER | tableName—the operation will scan every row in the specified table |
| INNER-JOIN | the operation will join multiple tables on rows where the join condition is met |
| MERGE SORT | performs a merge sort on the results |
| RANGE SCAN OVER tableName [ … ] | The information in the square brackets indicates the start and stop for each primary key that’s used in the query |
| ROUND ROBIN | when the query doesn’t contain ORDER BY and therefore the rows can be returned in any order, ROUND ROBIN order maximizes parallelization on the client side |
| x-CHUNK | describes how many threads will be used for the operation. The maximum parallelism is limited to the number of threads in thread pool. The minimum parallelization corresponds to the number of regions the table has between the start and stop rows of the scan. The number of chunks will increase with a lower guidepost width, as there is more than one chunk per region |
| PARALLELx-WAY | describes how many parallel scans will be merge sorted during the operation |
| SERIAL | some queries run serially. For example, a single row lookup or a query that filters on the leading part of the primary key and limits the results below a configurable threshold |
| EST_BYTES_READ | provides an estimate of the total number of bytes that will be scanned as part of executing the query |
| EST_ROWS_READ | provides an estimate of the total number of rows that will be scanned as part of executing the query |
| EST_INFO_TS | epoch time in milliseconds at which the estimate information was collected |
Squirrel安装
从http://www.squirrelsql.org/下载squirrel-sql-3.8.1-standard.jar
Widnow控制台输入java -jar squirrel-sql-3.8.1-standard.jar进行安装
安装路径不允许包含空格,安装完成后将相关phoenix包放入lib目录下:
/opt/cloudera/parcels/APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3/lib/phoenix
phoenix-core-4.14.0-cdh5.14.2.jar
phoenix-4.14.0-cdh5.14.2-client.jar
phoenix-4.14.0-cdh5.14.2-thin-client.jar
双击squirrel-sql.bat启动
点击左侧Drivers,添加Driver,填入如下信息:
Name:phoenixDriver
Example URL:jdbc:phoenix:10.10.0.87,10.10.2.110,10.10.2.111:2181
Class Name:org.apache.phoenix.jdbc.PhoenixDriver
点击左侧Aiiasses,添加Alias,填入如下信息:
Name:phoenixAlias
Driver:下拉框选择phoenixDriver
User Name:root
Password:目标机器密码
勾选自动登录
点击“test”测试连接,连接成功后保存
双击phoenixAlias连接phoenix进行操作
注:确保本机配置了HOSTS,否则可能连接不上,本实例为:
10.10.0.87 master
10.10.2.110 slave1
10.10.2.111 slave2
Hbase配置调优
Phoenix配置说明:http://phoenix.apache.org/tuning.html
HBase Server-Side(HBase服务范围):
phoenix.query.maxGlobalMemoryPercentage 50 —— Percentage of total heap memory that all threads may use
HBase Client-Side(Gateway):
phoenix.query.maxServerCacheBytes 1048576000 —— Maximum size (in bytes) of a single sub-query result (usually the filtered result of a table) before compression and conversion to a hash map
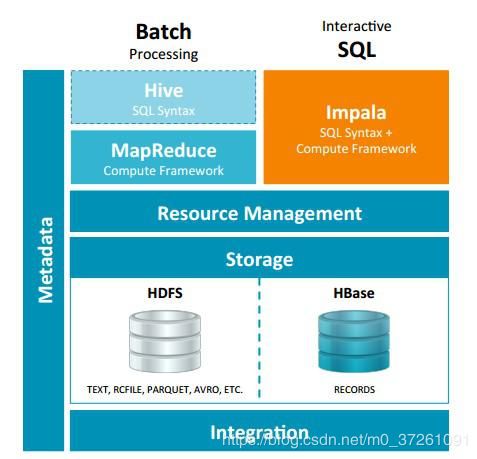
Sqoop导入导出
- Sqoop安装
wget http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.6-cdh5.14.2.tar.gz
vi ~/.bash_profile
export SQOOP_HOME=/opt/app/sqoop
export PATH=$SQOOP_HOME/bin:$PATH
将MySQL驱动包上传至$SQOOP_HOME/lib
- Sqoop配置
cd $SQOOP/conf
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/cloudera/parcels/CDH/lib/Hadoop
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/cloudera/parcels/CDH/lib/Hadoop
#set the path to where bin/hbase is available
export HBASE_HOME=/opt/cloudera/parcels/CDH/lib/hbase
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/opt/cloudera/parcels/CDH/lib/zookeeper
- Sqoop命令
查看MySQL数据库列表:
sqoop list-databases --connect jdbc:mysql://10.10.2.110:3306/test --username root --password root
查看MySQL数据库表:
sqoop list-tables --connect jdbc:mysql://10.10.2.110:3306/test --username jjuj root --password root
MySQL导入HBase:
sqoop import -D sqoop.hbase.add.row.key=true --connect jdbc:mysql://10.10.0.87:3306/msx_online --username root --password 123456 --table pay_detail --hbase-create-table --hbase-table pay_detail --column-family pay --hbase-row-key PAY_DETAIL_ID --where "pay_time> '2018-05-01'" -m 1
MySQL导入Hive:
sqoop create-hive-table --connect jdbc:mysql://10.10.2.110:3306/test --table dim_bank --username root --password root --hive-table dim_bank --fields-terminated-by "\0001" --lines-terminated-by "\n";(创建表结构)
sqoop import --connect jdbc:mysql://10.10.2.110:3306/test --username root --password root --table dim_bank --hive-import --hive-table dim_bank -m 1 --fields-terminated-by "\0001"(导入数据)
参数说明:
--fields-terminated-by "\0001" 是设置每列之间的分隔符,"\0001"是ASCII码中的1,它也是hive的默认行内分隔符, 而sqoop的默认行内分隔符为","
--lines-terminated-by "\n" 设置的是每行之间的分隔符,此处为换行符,也是默认的分隔符
MySQL导入HDFS:
sudo -u hdfs sqoop import -m 1 --connect jdbc:mysql://10.10.2.110:3306/test --username root --password root --table dim_bank --target-dir /test/bank
查看HDFS内容:hdfs dfs -cat /test/bank/part-m-00000
Spark2安装配置
1) 安装
安装文档:https://www.cloudera.com/documentation/spark2/latest/topics/spark2_packaging.html#packaging
下载2.3 Release 2版本CSD 和 Parcel:
CSD:http://archive.cloudera.com/spark2/csd/SPARK2_ON_YARN-2.3.0.cloudera2.jar
Parcel:http://archive.cloudera.com/spark2/parcels/2.3.0.cloudera2/
SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel
SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel.sha1
manifest.json
CSD上传至/opt/cloudera/csd
Parcel上传至/opt/cloudera/parcel-repo
chgrp cloudera-scm SPARK2_ON_YARN-2.3.0.cloudera2.jar
chown cloudera-scm SPARK2_ON_YARN-2.3.0.cloudera2.jar
重启Cloudera Manager Server
根据向导Parcel分发、激活并添加Spark2服务。
2) 配置
将hive-hbase-handler-1.1.0-cdh5.14.2.jar复制到$SPARK_HOME/jars
创建/var/log/spark2/lineage目录
3) 测试
a) spark-shell
spark-shell --master yarn --deploy-mode client
spark.sql("show tables").show()
spark.sql("select count(1) from sl_station_info").show()
spark.sql("select count(1) from pay_detail").show()
退出shell::q
b) spark-submit
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --num-executors 2 --executor-memory 2G --executor-cores 2 --driver-memory 1G --conf spark.default.parallelism=10 $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.cloudera2.jar 10
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \
--deploy-mode client $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.cloudera2.jar 10
Spark History Server:http://master:18089/
4) 其他
Cloudera parcel安装的spark2默认不包含spark-sql和thrift-server,现从
官网下载对应版本的spark2,并补全如下内容。
假设SPARK_HOME=/opt/cloudera/parcels/SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101 /lib/spark2
a) bin/spark-sql拷贝到$SPARK_HOME/bin
spark-hive-thriftserver_2.11-2.3.0.jar
hive-cli-1.2.1.spark2.jar
./spark-sql
b) 拷贝到$SPARK_HOME /jars
sbin/start-thriftserver.sh
sbin/stop-thriftserver.sh
拷贝到$SPARK_HOME/sbin
./start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10008 \
--hiveconf hive.server2.thrift.bind.host=master \
--master yarn-client
beeline
!connect jdbc:hive2://master:10008(这部分有些问题)
5) Spark性能调优
参考文章:https://blog.csdn.net/lingbo229/article/details/80729068
https://bbs.csdn.net/topics/392153088
num-executors:executor进程总数
executor-memory:每个executor内存
executor-cores:每个executor CPU cores
driver-memory:driver进程内存
spark.default.parallelism:每个stage默认task数量
spark.storage.memoryFraction:持久化数据在executor内存占比(0.6)
spark.shuffle.memoryFraction:shuffle聚合操作使用内存占比(0.2)
对应关系:
spark.executor.instances / —-num-executors
spark.executor.memory / —-executor-memory
spark.driver.memory / —-driver-memory
spark.default.parallelism / —conf spark.default.parallelism=n
spark.storage.memoryFraction / —conf spark.storage.memoryFraction=n
spark.shuffle.memoryFraction / —conf spark.shuffle.memoryFraction=n
Hadoop运维及调优
- MapReduce测试
sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 100 - Hadoop运维命令
hadoop job -list —— 任务列表
hadoop job -kill job_1528791645461_0001 —— 杀掉任务
- HDFS命令
hdfs dfs -ls -R / —— 查看文件列表
hdfs dfs –mkdir /test —— 创建目录
hdfs dfs –put ./people.txt /res —— 上传文件
hdfs dfs -get /test/bank/part-m-00000 ./bank —— 下载文件
hdfs dfs -cat /res/people.txt —— 查看内容
hdfs dfs –rm /res/people.txt —— 删除文件
hdfs dfs –rm –r /res —— 删除目录
hdfs dfsadmin –report —— 查看节点状态
hdfs dfsadmin –refreshNodes —— 刷新节点
hdfs dfsadmin -printTopology
hdfs balancer —— 均衡block
hdfs fsck /test/bank/part-m-00000 –files —— 检测文件
- YARN命令
yarn application -kill application_1528791645461_0061 —— kill yarn app
yarn logs -applicationId application_1528791645461_0061 —— app logs
参考资料
https://hbase.apache.org/1.2/book.html
https://hbase.apache.org/book.html#schema.ops
http://www.yunweipai.com/