【CVPR2019】超分辨率文章,SRFBN: Feedback Network for Image Super-Resoluition
论文地址
代码
CVPR的单图像超分辨率文章,主要是用回传机制来提高超分辨率的效果,且不引入过多的参数。
主要是设计了一个feedback模块,多次回传,如下图所示:
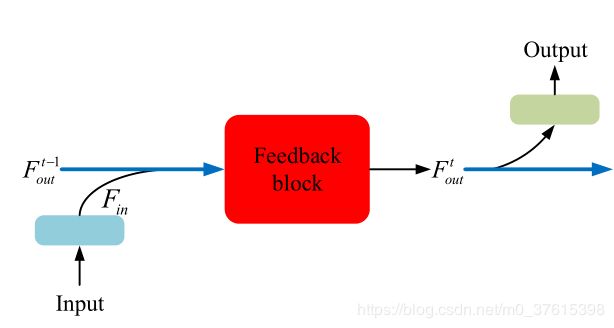
上一次feedback的输出和整个网络的input一起重新输入(代码里是concat一起)到FB模块,不断地回传,达到一定次数后经过tail输入SR图像。
更加形式化地图述:

这样回传的好处就在于,不会增加额外的参数,并且多次回传相当于加深了网络,不断地refine生成的SR图像。虽然像DRRN和DRCN也是采用了recurrent的结构,但是这些网络没办法做到前面层从后面层中得到有用的信息,所以说recurrent结构和feedback结构还是有一定的差别的。
其中,本文还讲到的基于课程学习的训练策略,就是将训练集的图片按难易程度排序,再进行训练。
Feedback Network for Image SR
在一个回传系统中,有两个requirements:迭代和重路由。
在SRFBN中,有三个不可缺少的部分:
- 每次的迭代都会计算loss,迫使网络每次迭代都重建图像。
- 使用recurrent结构,从而达到迭代的目的
- 在每次迭代中都提供LR图像的输入(和上一轮的输出做一个concat,提供低层信息)

网络结构如上图所示,SRFBN可以迭代多次,展开后如右图所示
可以看到,LR先经过两个3x3卷积,这两个卷积是特征提取模块,一个是conv(3,4m),一个是conv(3, m),3是卷积核大小,m是base卷积核数量。
FB的形式化表示是

以上一次的输出和输入的LR图像作为本次迭代的输入。
下面是pytorch代码中的上述操作
x = torch.cat((x, self.last_hidden), dim=1)
x = self.compress_in(x) #这步是降通道数为base通道数
最后,SR的图像由最后一次迭代的输出+up(LR)生成
![]()
Feedback block
现在我们具体来看FB模块是怎么样的

其实思想很简单,就是前面的conv的输出是一定会加到后面的conv的输入中,前面Deconv的输出也是加到后面Deconv的输入中,有点类似densenet的做法,防止梯度消失。
我们来看一下pytorch代码中FB模块的定义
for idx in range(self.num_groups):
self.upBlocks.append(DeconvBlock(num_features, num_features,
kernel_size=kernel_size, stride=stride, padding=padding,
act_type=act_type, norm_type=norm_type))
self.downBlocks.append(ConvBlock(num_features, num_features,
kernel_size=kernel_size, stride=stride, padding=padding,
act_type=act_type, norm_type=norm_type, valid_padding=False))
if idx > 0:
self.uptranBlocks.append(ConvBlock(num_features*(idx+1), num_features,
kernel_size=1, stride=1,
act_type=act_type, norm_type=norm_type))
self.downtranBlocks.append(ConvBlock(num_features*(idx+1), num_features,
kernel_size=1, stride=1,
act_type=act_type, norm_type=norm_type))
可以看到,实际上就是将前面的输出concat起来作为后面的输入
接下来看forward里面的pytorch的代码:
for idx in range(self.num_groups):
LD_L = torch.cat(tuple(lr_features), 1) # when idx == 0, lr_features == [x]
if idx > 0:
LD_L = self.uptranBlocks[idx-1](LD_L)
LD_H = self.upBlocks[idx](LD_L)
hr_features.append(LD_H)
LD_H = torch.cat(tuple(hr_features), 1)
if idx > 0:
LD_H = self.downtranBlocks[idx-1](LD_H)
LD_L = self.downBlocks[idx](LD_H)
lr_features.append(LD_L)
Curriculum learning strategy
课程学习,就是将训练集的图像按照困难程度排序,loss函数还是l1loss

W t W^t Wt是一个常量,用来衡量第T轮迭代对输出值的影响。(实际上论文里每一轮都置为1了……)
实验
用PRelu作为激活函数,训练集是Div2K和Flickr2K,测试仅在Y通道(基本上所有工作都是这样的)。
其中,patch size每一个scale factor都是不一样的

performance and parameters

compard with SOFT
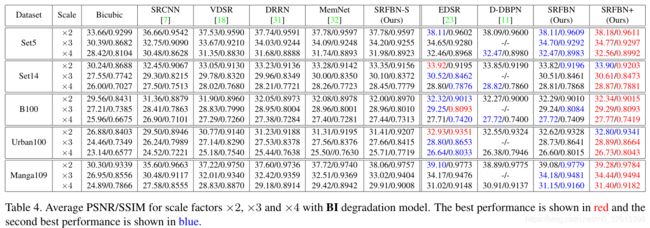
这里没用放RCAN和RDN的数据,实际上SRFBN没达到SOFT,现在最好的还是RCAN

最后,放几张效果图

