数据仓库详细介绍
-
目录
数据仓库和数据集市
数据仓库(Data Warehouse)
数据集市(Data Market)
数据仓库与数据集市的区别
维度和度量
维度(Dimension)
度量(Measure)
Cube、 Cuboid和Cube Segment
数据立方体(Data Cube)
长方体Cuboid
Cube Segment
事实表和维度表
事实表(FactTable)
维度表(DimensionTable)
数据仓库和数据集市
数据仓库(Data Warehouse)
-
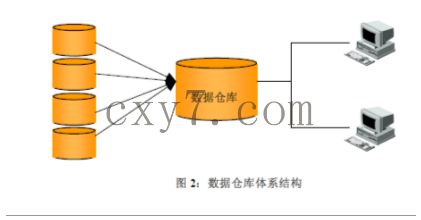
数据仓库(Data Warehouse) 是一种信息系统的资料储存理论, 此理论强调的是利用某些特殊的资料储存方式, 让所包含的资料特别有利于分析和处理, 从而产生有价值的资讯,并可依此做出决策。
-
数据仓库是面向主题的、集成的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集合,用以支持经营管理中的决策支持系统(DDS:Decision Support System,主要是报表系统)
-
利用数据仓库的方式存放的资料, 具有一旦存入, 便不会随时间发生变动的特性, 此外, 存入的资料必定包含时间属性, 通常一个数据仓库中会含有大量的历史性资料, 并且它可利用特定的分析方式, 从其中发掘出特定的资讯。
数据集市(Data Market)
是一个小型的部门或工作组级别的数据仓库

数据仓库与数据集市的区别

维度和度量
维度和度量是数据分析中的两个基本概念。
维度是指审视数据的角度,它通常是数据记录的一个属性,例如时间、地点等。
度量是基于数据所计算出来的考量值;它通常是一个数值,如总销售额、不同的用户数等。 分析人员往往要结合若干个维度来审查度量值,以便在其中找到变化规律。
一个SQL查询中,GroupBy的属性通常就是维度,而所计算的值则是度量。如下面的示例:
SELECT
part_dt,
lstg_site_id,
sum(price) AS total_selled,
count(DISTINCT seller_id) AS sellers
FROM
kylin_sales
GROUP BY
part_dt,
lstg_site_id上面的这个查询中,part_dt和lstg_site_id是维度,sum(price)和count(distinctseller_id)是度量
维度(Dimension)
维度一般是一组离散的值, 比如时间维度上的每一个独立的日期, 或者商品维度上的每一件独立的商品。 因此统计时可以把维度值相同的记录聚合在一起, 然后应用聚合函数做累加、 平均、 去重复计数等聚合计算
度量(Measure)
度量就是被聚合的统计值,也是聚合运算的结果,它一般是连续的值,如图1-2中的销售额,抑或是销售商品的总件数。
通过比较和测算度量,分析师可以对数据进行评估,比如今年的销售额相比去年有多大的增长,增长的速度是否达到预期,不同商品类别的增长比例是否合理等

Cube、 Cuboid和Cube Segment
给定一个数据模型,我们可以对其上的所有维度进行组合。对于N个维度来说,组合的所有可能性共有2N种。
对于一种维度的组合,将度量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid。
所有维度组合的Cuboid作为一个整体,被称为Cube。所以简单来说,一个Cube就是许多按维度聚合的物化视图的集合

数据立方体(Data Cube)
数据立方体,是一种常用于数据分析与索引的技术;它可以对原始数据建立多维度索引。通过Cube对数据进行分析,可以大大加快数据的查询效率
数据立方体只是多维模型的一个形象的说法。立方体其本身只有三维,但多维模型不仅限于三维模型,可以组合更多的维度
一方面是出于更方便地解释和描述,同时也是给思维成像和想象的空间;另一方面是为了与传统关系型数据库的二维表区别开来

-
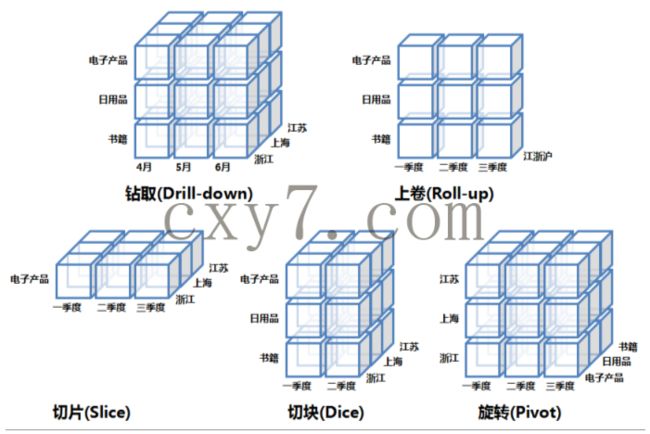
钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图; 当然也可以钻取浙江省来查看杭州市、波市、温州市……这些城市的销售数据。
-
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
-
(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
-
块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
-
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
长方体Cuboid
在Kylin中特指在某一种维度组合下所计算的数据
计算Cuboid, 即按维度来聚合销售额。 如果用SQL语句来表达计算Cuboid[Time, Location], 那么SQL语句如下:
SELECT
Time,
Location,
Sum(GWV) AS GWV
FROM
Sales
GROUP BY
Time,
LocationCube Segment
是指针对源数据中的某一个片段, 计算出来的Cube数据。 通常数据仓库中的数据数量会随着时间的增长而增长, 而Cube Segment也
事实表和维度表
事实表(FactTable)
事实表(FactTable)是指存储有事实记录的表,包含了每个事件的具体要素,以及具体发生的事情,如系统日志、销售记录等;
事实表的记录在不断地动态增长,所以它的体积通常远大于其他表。
发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。从最低的粒度级别来看,事实表行对应一个度量事件,反之亦然。
在事实表里没有存放实际的内容,他是一堆主键的集合,这些ID分别能对应到维度表中的一条记录
维度表(DimensionTable)
维表,有时也称查找表(LookupTable),是对事实表中事件的要素的描述信息;
它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。
常见的维度表有:日期表(存储与日期对应的周、月、季度等的属性)、地点表(包含国家、省/州、城市等属性)等
每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表的外键,当然,维度表行的描述环境应与事实表行完全对应。 维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。

【注】文章转自:http://cxy7.com/articles/2017/06/23/1498211944874.html