Python自然语言处理—词嵌入 word2vec
Python自然语言处理这本书后几章感觉更偏向一些文法知识,我简单读了一下放弃了。现在开始学
https://github.com/yandexdataschool/nlp_course,本章将介绍第一周的内容——词嵌入。
一 Word Embedding
词如何转为向量呢?最简单的方法就是维护一个长的词典,使用one-hot来表示一个词,吃饭 [0,0,0,0,1,...,0,0,0]。基于这样的词向量,句子向量可以通过简单的词向量累加获得,接着就可以用句向量去做一些文本分类。
one-hot的词向量有两个缺点
1,矩阵稀疏,如果词典长100,000,那么每个词向量其实长度是10万,能否找到一种方法将长度10万的词向量嵌入到低纬度的空间中呢?这也是词嵌入名字的由来。
2,忽视了词与词之间的关系。例如番茄和西红柿其实是一个意思,英国+首都和伦敦是一个意思。如何将这种关系体现在词向量中呢?
词嵌入的方法有很多,可以通过矩阵分解来完成也可以通过机器学习来完成,下面介绍Google推出的word2vec的词嵌入方法。
二 word2vec
1. 分布相似性原理
首先模型是建立在分布相似性理论上的,即相似的词上下文也是相似的。所以‘喜欢’和‘讨厌’最终训练的词向量是相似的,当然数据量足够大,数据样本质量足够高可以训练出 ‘喜欢’和‘讨厌’的词向量之间差一个否定词的向量,就是这么神奇。网上常用的例子是国王-男性+女性 = 王后。
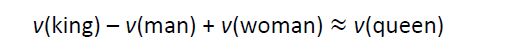
2. word2vec有两种模型SG和CBOW
Skip-gram的核心思想是用当前词预测上下文,如下图所示。有人会问input是词,output是上下文,那么我们需要的词向量呢?
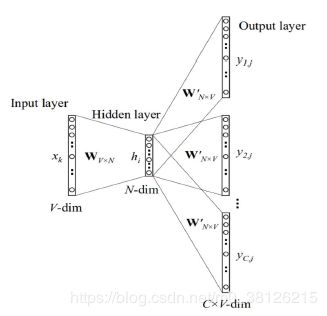
词向量就是图中的Wv*n,我们仔细梳理一下该模型的各个层(我用的矩阵维度和图中的不太一样)
第一层:X 是 1*V的one hot向量
第二层:X*W 是(1*V) * (V*N)=1*N 是当前词的词向量 ,W就是所有词的词向量,整个模型反馈操作都在修正这个W,让最终的词向量可以做到 利用当前词 预测上下文
第三层: h*W' 是(1*N) * (N*V)=1*V 是当前词和所有其他词的相似度向量,!!其实W'也是一个词向量的集合哦!!为了便于计算,每个词在充当当前词和上下文词的时候用的是不同的词向量!!
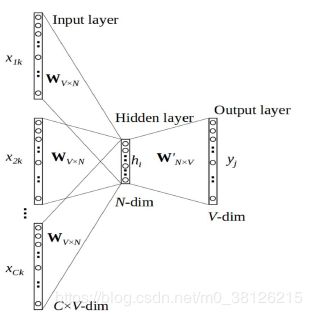
Continuous Bag of Words的核心思想是通过上下文预测当前词,不详细介绍了
3. 其他
看完两个模型大家可能有一个问题,那就是上下文指的是什么?上下文对应就是当前词前后k个长度内的词。
优化方法,我没有深入研究,基于上述知识我们已经可以开始使用word2vec来构造我们自己的词向量了。不过我还是抄了一段优化讲解,来源于https://blog.csdn.net/u010159842/article/details/80334324
1.Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。一开始我们可以用以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。从根节点出发,到达指定叶子节点的路径是的。Hierarchical Softmax正是利用这条路径来计算指定词的概率,而非用softmax来计算。 即Hierarchical Softmax:把 N 分类问题变成 log(N)次二分类
2.Negative Sampling(简写NEG,负采样),这是Noise-Contrastive Estimation(简写NCE,噪声对比估计)的简化版本:把语料中的一个词串的中心词替换为别的词,构造语料 D 中不存在的词串作为负样本。在这种策略下,优化目标变为了:较大化正样本的概率,同时最小化负样本的概率。
三 Seminar
让我们开始使用吧!
下载数据集https://yadi.sk/i/BPQrUu1NaTduEw
导入数据
import numpy as np
data = list(open(r"C:\Users\BF\Desktop\机器学习\nlp_course-master\week1_embeddings\quora.txt","r",encoding='utf-8'))
data[50]文本分析第一步分词,由于是英文语料直接用NLTK分词就好,记得在分词前把把所有字母改成小写哦
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
data_tok = [tokenizer.tokenize(lines.lower()) for lines in data] # 列表解析,一句代码完成分词
print(data_tok[50])开始使用word2vec吧!
from gensim.models import Word2Vec
model = Word2Vec(data_tok,
size=32, # 设置结果词向量的长度,长度越高保留的信息越多。size足够大的情况,甚至一词多义也是可以解决的
min_count=5, # 去除低频词汇
window=5).wv # 定义窗口大小,也就是上下文的范围 5是一个不错的数字
model.get_vector('good') # 获取当前词的词向量,如果词未出现会报错
model.most_similar('bread') # 找出相似词来看看bread的相似词把,结果是不是很好!

当然我们也可以加载一些已经训练好的模型,如何把高纬度词向量展现到二维平面呢?可以使用主成分分析,也可以使用t-SNE
有了词向量,让我们开始计算句向量!句子向量=词向量的累加平均,在前面文章介绍过,句子向量可以用词频或tf-idf的形式展现,其实也就是one-hot的词向量简单的累加而组成的句向量(tf-idf考虑了词的重要性)。所以现在我们用word2vec的结果简单累加成句子向量也就不奇怪了。
def get_phrase_embedding(phrase):
token = tokenizer.tokenize(phrase.lower()) # 第一步分词
veclist =[]
for word in token: # 第二步,获取每个词的词向量,请注意获取不到的词跳过
try:
veclist.append(model.get_vector(word))
except:
pass
if len(veclist) != 0: # 第三步词向量求平均
vector = np.array(veclist).mean(axis = 0)
else:
vector = np.zeros([model.vector_size], dtype='float32') # 如果这句话每个词都没见过返回0向量
return vector
vector = get_phrase_embedding("I'm very sure. This never happened to me before...")
print(vector)获取每句话的句向量,找出相似的句子!句子之间的相似度建议使用余弦夹角来衡量!!
data_vectors = np.array([get_phrase_embedding(l) for l in data])
def find_nearest(query, k=10): # 水平有限,只能写出这么复杂的找相似句子的代码
wordvec = np.array(get_phrase_embedding(query)) # 计算当前句子的句向量
coslist = [np.dot(wordvec,v)/(np.linalg.norm(wordvec)*(np.linalg.norm(v))) for v in data_vectors] #计算每个句子与现有文本集中句子的相似度
coslist = sorted(list(enumerate(coslist)), key=lambda vec: vec[1], reverse = True) # 排序
results = [data[i[0]] for i in coslist[:k] ] # 找出前k个句子的index
return results
find_nearest(query="How does Trump?", k=10)
结果如下,请注意我最终使用的word2vec的模型并非自己训练的,而是用的已经训练好的模型
import gensim.downloader as api
model = api.load('glove-twitter-100')

词嵌入还是非常有用的,词嵌入的结果基本上是你建模的input,无论是你准备用cnn做分类还是rnn做分类,都需要词嵌入的支持!
重新申明一下本文是 https://github.com/yandexdataschool/nlp_course的学习笔记!第二周是用cnn做文本分类!!继续学习