机器人意图识别和词槽抽取RasaNLU解析

AI深入浅出
数据驱动 算法护航
关注

智能机器人的关键核心有二,语义理解和对话管理。在一堆开源项目中,同时具备的并不多见。Rasa项目囊括了这二者,Rasa NLU主要功能是用户问句的意图识别和关键要素抽取(也叫词槽抽取,或实体提取),Rasa Core提供了机器学习策略处理的对话管理。本文主要是使用层面实践Rasa NLU的魅力。Rasa NLU是做智能机器人的语义理解的不二选择。
Ⅰ、使用对象:智能机器人的开发者
可以作为wit、luis、Dialogflow的替代品,唯一更改代码的地方就是发送请求到localhost。
Ⅱ、为什么使用Rasa而不是使用wit、luis、dialogflow这些服务?
(1)不必把数据交给FackBook/MSFT/Google;
(2)不必每次都做http请求;
(3)你可以在特殊的场景中调整模型,保证更有效。
Ps:以上几点都详细的记录到了blog post里(博客打不开)
Ⅲ、使用Rasa NLU的方法
除了可以通过Http服务的形式运行Rasa NLU,也可以通过python程序直接使用。Rasa NLU支持python2和python3。构建交互会话聊天,在Context-aware Dialogue章节中描述的更详细。
实践内容和解释
Ⅳ、Getting Started
1、Installation 安装
2、Tutorial:A simple restaurant search bot 教程:一个简单的餐馆搜索机器人
Ⅴ、User Documentation
1、Configuration 配置
2、Migrating anexisting app 迁移到一个已经存在的APP
3、Training and DataFormat 训练、数据格式
4、Using Rasa NLU asa HTTP server 将Rasa NLU作为http server使用
5、Using Rasa NLUfrom python 直接用python使用Rasa NLU
6、Entity Extraction 实体提取
7、Improving yourmodels from feedback 从反馈日志中改善自己的模型
8、Model Persistence 模型存储
9、Language Support 支持的语言
10、processingPipeline pipeline处理
11、Evaluation 评估
12、Context-aware Dialogue 上下文感知的对话
13、Frequently Asked Questions 常见问题
14、Migration Guide 版本迁移指南
15、License 许可
一、Installation 安装
见《Rasa-nlu部署》。因为安装过程文档略长,有需要的朋友可以后台留言,单独发送Linux、Windows、Ubuntu的实践过的安装文档。也可以按照如下过程:

如果想使用所有组件,就一次安装全部。

针对Pipeline:
与pipeline相关的需要安装spaCy,sklearn或者MITIE(提供了NLP和ML)。
(1)最适合的:spaCy+sklearn
前两者是首选,但是在很多领域MITIE效果也一样好甚至会更好,并且MITIE安装很快,训练速度也更快。
pip install -U scikit-learn sklearn-crfsuite
pip install git+https://github.com/mit-nlp/MITIE.git
(2)第一选择:MITIE
下载MITIE的模型。需要配置的pipeline:

注意:意图稍多,训练速度就会减慢。解决办法有两种,一种是使用sklearn+MITIE;另一种是用作者提供的github上MITIE训练。
(3)另一个选择:sklearn+MITIE
综合上面两种的优点:
1、sklearn快速而良好的意图分类
2、MITIE生成的良好的特征向量和实体识别
如果超出10个意图,MITIE训练会花费很长时间。
综合sklearn和MITIE的pipeline配置:

Ⅳ、Getting Started
二、Tutorial:A simple restaurant search bot 教程:一个简单的餐馆搜索机器人
(可以从wit/luis/dialgueflow里拉取已有的样例数据)
1、准备数据,数据包含text、intent、entities(start,end,value,entity,confidence)

训练数据可视化:提供了github上一个工具RasaHQ/rasa-nlu-trainer。这对于检查和修改数据很有帮助。
可视化效果如下:【建议在训练前先检视数据】

选择一种后端pipeline方式(spacy_sklearn,mitie,sklearn_mitie)。
2、训练
(1)训练模型
python -mrasa_nlu.train -c sample_configs/config_jieba_mitie_sklearn.yml --datadata/examples/rasa/demo-rasa_zh.json --path models
config:配置ML模型。数据可以-data也可以-url。
(2)模型应用,启动服务
python -mrasa_nlu.server -c sample_configs/config_jieba_mitie_sklearn.yml --path models
【models是指使用的是最新一次的训练模型】
(3)使用【怎样使用某个模型】
浏览器访问 localhost:5000/parse?q=I amlooking for Mexican food
终端上访问 curl -XPOST localhost:5000/parse-d '{"q":"I am looking for Mexican food","model": "model_20170921-170911"}' | python -mjson.tool
返回结果
{
"intent": {
"name": "restaurant_search",
"confidence": 0.8231117999072759
},
"entities": [
{
"start": 17,
"end": 24,
"value": "mexican",
"entity": "cuisine",
"extractor": "ner_crf",
"confidence": 0.875
}
],
"intent_ranking": [
{
"name": "restaurant_search",
"confidence": 0.8231117999072759
},
{
"name": "affirm",
"confidence": 0.07618757211779097
},
{
"name": "goodbye",
"confidence": 0.06298664363805719
},
{
"name": "greet",
"confidence": 0.03771398433687609
}
],
"text": "I am looking for Mexican food"
}
注意:如果换成spacy_sklearn效果不佳,那是因为数据太少了。
意图分类和实体提取是分开实现的功能,所以有时候会意图分类正确但实体提取错误或不存在。
使用不同的pipeline后端模式,产生结果中可能会包含其他属性或者少一些属性。比如,mitie的pipeline的结果里没有“intent_ranking”,spacy_sklearn的pipeline的结果里却包含。
Ⅴ、User Documentation
一、Configuration 配置
RasaNLU参数配置方式有三种:
(1)yaml(yml)格式的配置文件;
(2)环境变量;
(3)命令行参数。
三者的关系,环境变量可以重写配置文件中的,命令行可以重写任何指定的选项。环境变量的写法一般带着RASA_前缀。
Ⅴ、User Documentation
二、Migrating an existing app 迁移到一个已经存在的APP
可以复用wit、luis、dialogueflow的数据和数据格式。
Ⅴ、User Documentation
三、Training and Data Format 训练、数据格式
训练数据构造成不同的部分,common_examples、entity_synonyms和regex_features。最主要的是common_examples。
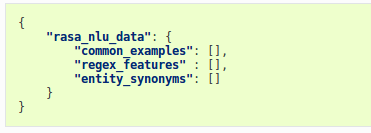
common_examples用来训练实体和意图模型。
regex_features是个帮助分类器检测实体或意图的工具,以此来提供性能。
你可以使用Chatito,是一个可以通过简单的DSL或Tracy生成rasa格式的训练数据的工具,有个简单的GUI来创建训练数据。
1、common examples

2、Entity Synonyms
使用同义词,在配置文件中必须引用ner_synonyms组件。

也可以增加“entity_synonyms”实体名称的同义词数组。

注意:添加上述同义词并不能改善模型对于这些实体的分类。在替换同义词之前,必须对实体进行适当的分类。
3、Regular Expression Features
正则表达式可以帮助意图分类和实体提取。

正则表达式不定义实体或者意图,就是一类规则表述。可以使用正则表达式提高意图分类性能。
正则表达式只用于ner_crf组件,ner_mitie和ner_spacy不用。现在,所有意图分类均使用可用的正则表达特征。
训练数据除了以上方式,也可以使用markdown。但是不支持json和mk混合的。
ps:训练数据可以存放在一个文件里也可以分到不同的文件。对于大量的训练样本,训练数据分割成不同的文件。每个意图一个,增加可维护性。

Ⅴ、User Documentation
四、Using Rasa NLU as a HTTP server 将Rasa NLU作为http server使用
可以把训练train作为服务请求,没有试用成功。
POST:Train - parse-evaluate-status
GET: version-config-models
Ⅴ、User Documentation
五、Using Rasa NLU from python 直接用python使用Rasa NLU
1、训练(training time)
为了创建模型,可以像非python编码人员一样使用。或者直接在python中使用脚本(例如spacy)【需要安装spacy】

运行测试:python tests/selfTest/trainTest.py
相应路径下产生模型。
2、预测(Prediction Time)
可以直接从python 脚本调用 Rasa NLU。为此,需要加载模型的元数据并实例化解释器。
模型路径下的metadata.json包含着recover模型所需的基本信息。

如果创建多个模型,则在不同模型之间共享组件是合理的。
Ⅴ、User Documentation
六、实体提取(Entity Extraction)
有很多不同的实体提取的组件,我们通过一些用例,提出使用的建议。
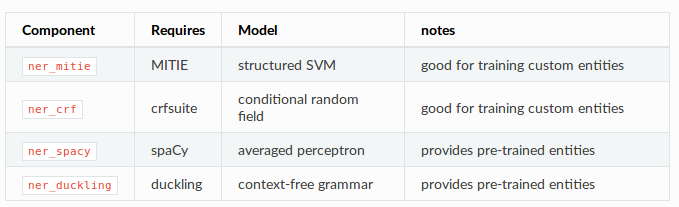

还可以用正则的方式补充实体抽取。

(1)地方、日期、人、组织(places,dates,people,organisations)
spaCy包含了很多优秀的训练好的明名实体识别模型。不建议用spaCy训练自己的ner,除非有大量的数据和明确的目的。有些spaCy的模型是高度区分大小写的。
(2)日期,金额,持续时间,距离,序数(dates,amountsof money,durations,distances,ordinals)
duckling包,会把“下星期四晚上8点”转化成实际的日期对象。还可以处理时间段,比如“两小时”,金钱,距离等。duckling有个python安装包(github上)。你可以通过PyPI安装ducklingpackage并且添加ner_duckling到pipeline就可以使用该组件了。
(3)定制的、特定领域的实体(custom,domain-specificentities)
在教程里,以构建一个餐厅机器人为例,创建了位置location和菜肴cuisine两类实体。用于训练这些特定领域的实体识别器的是ner_mitie和ner_crf组件。建议同时使用这两种方法效果最佳。
返回实体对象(returned entities object)
在返回的解析结果中,有两个字段显示了pipeline返回结果的来源。
一个是extractor:告诉你哪个实体识别器抽取的该实体
一个是processors:包含更改特定实体的组件名称
同义词的使用会造成字段值与文本里内容不匹配,值可能是已经训练的同义词。
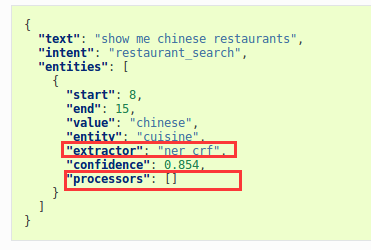
注意:ner_crf组件会返回实体识别结果的置信度confidence,duckling实体识别返回的都是1.ner_spacy没有这个信息,返回的都是null。
Ⅴ、User Documentation
七、从反馈中优化模型(improving your models from feedback)
当rasa_nlu服务开始运行后,它会跟踪所有的预测,并将结果保存到日志里。默认的日志存储在logs/里。这个目录下的文件中每行包含一条json对象。你可以修复任何错误的预测,并将它们添加到你的训练集中,以改进解析器。在将这些数据添加到训练数据之后,但在重新训练模型之前,强烈建议使用可视化工具发现错误。
Ⅴ、User Documentation
六、model persistence
RasaNLU支持Amazon S3 storage 、GCS(google cloud storage)和Azure Storage。
Ⅴ、User Documentation
七、语言支持Language Support

新增一种新的语言的步骤(需要新增某种语言的训练语料):
(1)spacy-sklearn
spaCy已经提供了添加新语言的文档。这个可以帮助你训练新语言的分词器和词汇。
(2)MITIE
(3)jieba-MITIE
Ⅴ、User Documentation
十一、常见问题frequently asked questions
1、训练需要多少样本?
没有明确答案,这取决于意图和实体。如果有容易混淆的意图,还是需要更多的训练数据。当有很多意图时,每个意图下也需要添加很多训练数据。20~30个独特的表达式。
同样,对于实体也是,取决于不同实体类型之间的紧密关联程度和实体在用例中与其他实体的区别。
2、可以支持python2 python3.5 python3.6任何一个版本;
3、能支持任何的语言类型;
4、Rasa NLU的版本
Python -c"import rasa_nlu;print(rasa_nlu.__version__)"
5、错误:

如果有这个错误,是因为缺乏训练数据造成的。(在训练过程中,数据集将被多次分割,如果意图有很少的训练样本,则分列可能导致不包含任何用于此意图的数据。)
解决方法就是增加更多的训练样本。由于这只是一个警告,所以训练仍会成功,但所得到的预测模型在缺乏训练样本的意图上是很薄弱的。
此文作为学习笔记记录了,记录比较粗糙,还请见谅,不过确实是实践过的。有什么问题,还请各位看官不吝赐教。期待大家的私信或留言。
![]() 加入Python学习微信交流群
加入Python学习微信交流群
请添加微信:AI_doer
备注:姓名-单位-研究方向
搞算法的我们,不知道这些算法怎么行
一招搞定Windows与Linux间Python交互编程
语义分析的方法简述之文本基本处理
语义分析的方法简述二
今日头条算法原理(全)
高盛:79页区块链报告-《从理论到实践》(附下载)

所见即可问~

欢迎转发到朋友圈或分享给好友