《百面机器学习——学习笔记》2、模型评估
前言
“没有测量,就没有科学。” ——门捷列夫
1、评估指标的局限性
奢侈品广告投放问题,训练奢侈品用户数据模型,准确率高,但非奢用户仍被投广告
问题1 准确率的局限性。难度:★☆☆☆☆
解答:
准确率(Accuracy):分类正确的样本占总样本个数的比例
缺点:当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
改进:平均准确率(每个类别下的样本准确率的算术平均)
模糊搜索排序返回top5精确率高,但用户找不到想要的视频(尤其一些冷门剧集)
问题2 精确率与召回率的权衡。难度:★☆☆☆☆
解答:
精确率(Precision):分类正确的正样本个数占分类器判定为正样本的样本个数的比例。
召回率(Recall):分类正确的正样本个数占真正的正样本个数的比例。
综合指标:
P-R曲线Precision-Recall):横轴是召回率,纵轴是精确率。
F1 score:精准率和召回率的调和平均值F1 = 2×p×r / (p+r)
ROC曲线
预测某部美剧的流量趋势,但结果RMSE都非常高,在95%的时间区间内预测误差小于1%
问题3 RMSE指标居高不下的原因是什么?平方根误差的“意外”。难度:★☆☆☆☆
解答:
均方根误差(Root Mean Square Error,RMSE):用来衡量回归模型的好坏,能够很好地反映回归模型预测值与真实值的偏离程度。
![]()
其中,yi是第i个样本点的真实值, ![]() 是第i个样本点的预测值,n是样本点的个数。
是第i个样本点的预测值,n是样本点的个数。
缺点:
如果存在个别偏离程度非常大的离群点(Outlier)时,即使离群点数量非常少,也会让RMSE指标变得很差。
解决方法:
- 若离群点是噪声点,数据与处理阶段过滤噪声
- 若离群点不是噪声点,将离群点机制建模进去
- 更换鲁棒性更好的评估指标,如平均绝对百分比误差(Mean Absolute Percent Error,MAPE)
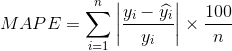
MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响。
2、ROC曲线
问题1 什么是ROC曲线?难度:★☆☆☆☆
解答:ROC曲线是Receiver Operating Characteristic Curve,受试者工作特征曲线,横坐标为假阳性率(False Positive Rate,FPR);纵坐标为真阳性率(True Positive Rate,TPR)。
FPR=FP/N,TPR=TP/P
P是真实的正样本的数量,N是真实的负样本的数量,TP是P个正样本中被分类器预测为正样本的个数,FP是N个负样本中被分类器预测为正样本的个数。
问题2 如何绘制ROC曲线?难度:★★☆☆☆
解答:
通过不断移动分类器的“截断点”来生成曲线上的一组关键点的。
问题3 如何计算AUC?难度:★★☆☆☆
解答:
AUC指的是ROC曲线下的面积大小,能够量化地反映基于ROC曲线衡量出的模型性能。AUC的取值一般在0.5~1之间。由于R
OC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成1−p就可以得到一个更好的分类器),所以AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
问题4 ROC曲线相比P-R曲线有什么特点?难度:★★★☆☆
解答:
当正负样本的分布发生变化时,ROC曲线的形状能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。
ROC曲线能够尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能。
3、余弦距离的应用
问题1 结合你的学习和研究经历,探讨为什么在一些场景中要使用余弦相似度而不是欧氏距离?难度:★★☆☆☆
解答:
余弦相似度关注的是向量之间的角度关系,并不关心它们的绝对大小,其取值范围是[−1,1]
欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
模型评估中不同的指标用在什么场景中?
(模型评估:分为离线评估与在线评估两阶段)
分类、 排序、 回归、序列预测等问题,指标不同。
即使评估指标选择对了, 仍会存在模型过拟合或欠拟合、 测试集和训练集划分不合理、 线下评估与线上测试的样本分布存在差异等一系列问题, 但评估指标的选择是最容易被发现, 也是最可能影响评估结果的因素。
分类:(用户分类)准确率、平均准确率(样本比例不均衡)
排序:(搜索排序返回TOP N)精确率、召回率、P-R(PrecisionRecall) 曲线、F1 score、ROC曲线
回归:(预测流量趋势)均方根误差RMSE、平均绝对百分比误差MAPE
每个评估指标都有其价值, 但如果只从单一的评估指标出发去评估模型, 往往会得出片面甚至错误的结论; 只有通过一组互补的指标去评估模型, 才能更好地发现并解决模型存在的问题, 从而更好地解决实际业务场景中遇到的问题。