FCN语义分割——训练自己的数据
前言
前段时间研究了下FCN的语义分割,并且将其成功运用在了自己的数据集上,现在分割出来的结果不是很满意,期待后期的调试将其提升。这里就将这个过程记录下来,希望对各位看官有所帮助
1. 数据集处理
在VOC2012的那个数据集中包含了做好的分割数据集,但是要自己制作数据集的时候就需要注意下了。首先,VOC2012分割数据集中的分割好的图像数据是8位的,不要看着是彩色的就认为是3通道的RGB图像,如下图例子所示

查看该图像的属性,可以看到是8位的图像
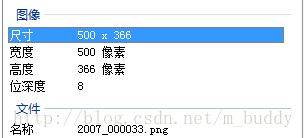
这里为什么将其弄成为彩色的是为了给人看的,并不是真正的彩色图像。所以,在制作数据集的时候我们需要分析我们的数据集,需要将那些物体进行分割得到一张表格,将每个物体用一个颜色去表示,比如我的

这里的特征值代表的是像素值(灰度值),每一个级别的值代表一个类,因而0~255就可以代表256个分类。
这是我制作的数据集(方便观看)

而实际用于训练的,全是黑的是因为我每个分类的像素值取得小-_-。。

然后其他的比如图像列表文件啦,各位看官按照自己的数据集分析整理就好了,若有不清楚的欢迎留言或是私信交流。好了,这下数据集准备好了,那就开始训练了
2. 数据训练
2.1 修改网络路径
修改solver.prototxt文件中训练和测试网络的地址

修改train.prototxt和val.prototxt中的dataset参数地址

PS: 这里需要说明一下,在训练自己的数据的时候,定义的类数目跟原始网络的类数目不相同就需要将train.prototxt和val.prototxt中num_output为21的改为num_output加上你的分类数目,因为这里是用别人的模型进行再训练。
2.2 修改solver.py
我这里将solver.py修改了增加了些绘制曲线
# -*- coding=utf-8 -*-
import os
import matplotlib.pyplot as plt
import sys
sys.path.append('/home/sucker/Desktop/caffe-1.0/python')
sys.path.append('/home/sucker/Desktop/caffe-1.0/python/caffe')
sys.path.append('/home/sucker/Desktop/caffe-1.0/build/lib')
import caffe
import surgery, score
import numpy as np
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
weights = 'fcn8s-heavy-pascal.caffemodel'
# init
caffe.set_device(0)
caffe.set_mode_gpu()
solver = caffe.SGDSolver('solver.prototxt')
vgg_net = caffe.Net('deploy_21.prototxt', weights, caffe.TRAIN)
surgery.transplant(solver.net, vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# init net_show
m_show = net_show.Net_Show(solver.net)
m_show.ShowLayer_Info()
# scoring
val = np.loadtxt('../MRI_Seg/seg11valid.txt', dtype=str)
all_acc = []
mean_acc = []
n_iter = 25
n_step = 500
for _ in range(n_iter):
solver.step(n_step)
acc, m_acc = score.seg_tests(solver, False, val, layer='score')
all_acc.append(acc)
mean_acc.append(m_acc)
train_loss = np.array(all_acc)
test_loss = np.array(mean_acc)
# 绘制train loss、test loss和accuracy曲线
print '\nplot the train loss and test accuracy\n'
_, ax1 = plt.subplots()
ax2 = ax1.twinx()
# train loss -> 绿色
ax1.plot(n_step * np.arange(len(train_loss)), train_loss, 'g')
# test loss -> 黄色
ax1.plot(n_step * np.arange(len(test_loss)), test_loss, 'y')
# test accuracy -> 红色
# ax2.plot(test_interval * np.arange(len(test_acc)), test_acc, 'r')
plt.show()
2.3 修改score.py文件
这里只是将函数里面运算得到的数据返回回去,你可以根据自己的需求选择修改或是不修改
修改seg_tests函数
def seg_tests(solver, save_format, dataset, layer='score', gt='label'):
print '>>>', datetime.now(), 'Begin seg tests'
solver.test_nets[0].share_with(solver.net)
hist, loss, acc, m_acc, m_iu = do_seg_tests(solver.test_nets[0], solver.iter, save_format, dataset, layer, gt)
return acc, m_acc
修改do_seg_tests函数
def do_seg_tests(net, iter, save_format, dataset, layer='score', gt='label'):
n_cl = net.blobs[layer].channels
if save_format:
save_format = save_format.format(iter)
hist, loss = compute_hist(net, save_format, dataset, layer, gt)
# mean loss
print '>>>', datetime.now(), 'Iteration', iter, 'loss', loss
# overall accuracy
acc = np.diag(hist).sum() / hist.sum()
print '>>>', datetime.now(), 'Iteration', iter, 'overall accuracy', acc
# per-class accuracy
acc = np.diag(hist) / hist.sum(1)
print '>>>', datetime.now(), 'Iteration', iter, 'mean accuracy', np.nanmean(acc)
# per-class IU
iu = np.diag(hist) / (hist.sum(1) + hist.sum(0) - np.diag(hist))
print '>>>', datetime.now(), 'Iteration', iter, 'mean IU', np.nanmean(iu)
freq = hist.sum(1) / hist.sum()
print '>>>', datetime.now(), 'Iteration', iter, 'fwavacc', \
(freq[freq > 0] * iu[freq > 0]).sum()
return hist, loss, acc, np.nanmean(acc), np.nanmean(iu)
2.4 修改voc_layer.py文件
修改这个文件主要是为了让它可以直接支持图片加载进来,具体可以参考之前的博文:FCN语义分割——直接加载图像数据
后记
运行起来了,但是结果没有达到需求,后面再改进吧
