利用OWASP Benchmark V1.2基准对国内静态检测工具的测评分析
笔者一直从事于软件测试、软件安全方面工作,跟踪国内外软件测试工具的使用和效果。最近笔者接触了CoBOT源代码缺陷检测工具,想验证一下该工具的检测效果,于是下载了OWASP Benchmark 1.2基准测评项目,通过CoBOT官网联系试用工具,看看这款工具到底如何。
OWASP Benchmark是OWASP(Open Web Application Security Project)下的一个开源项目,是OWASP提供静态扫描工具的免费基准测试项目。主要用来评估自动化安全扫描工具的速度、覆盖范围和准确性,从而了解工具的优点和缺点,并与其它工具进行对比。截止2019年7月最新版本为1.2版本,包括了2740个测试案例,每个案例都对应CWE编号,可以检测出扫描工具的误报率和漏报率。
之前对国内外其它工具也做过测评,V1.2版本中一共有2740个测试案例,真假漏洞详细统计情况表1。对于任何一款检测工具来说,要能发现真实漏洞,同时故意设置的假漏洞又不能误报。
在2740个测试案例中,部分存在真实安全漏洞,部分是假的安全漏洞。分别使用下面术语描述。
如果扫描工具正确识别了真实漏洞(True Positive,TP),称为真阳性。
如果扫描工具没有识别出真实漏洞(False Negative,FN),称为假阴性。
如果扫描工具没有对假的漏洞进行误报(True Negative,TN),称为真阴性。
如果扫描工具对假的漏洞进行误报(False Positive,FP),称为假阳性。
通过对使用扫描工具对2740个测试案例进行检测,检测结果通过Benchmark Accuracy Score(基准准确度得分),称为Youden Index(约登指数)。计算方法为:
(sensitivity + specificity) – 1
其中Sensitivity = TPR=TP/(TP+FN)
Specificity = 1-FPR=TN/(TN+FP)
Youden Index=(sensitivity + specificity) – 1 =(TPR+1-FPR)-1 =TPR-FPR
表1 OWASP Benchmark真假漏洞统计
2740个测试案例中真假漏洞详细统计情况如下:
表1 OWASP Benchmark真假漏洞统计
| 漏洞简称 |
漏洞全称 |
真漏洞 |
假漏洞 |
小计 |
| cmdi |
命令行注入 |
126 |
125 |
251 |
| crypto |
弱密码 |
130 |
116 |
246 |
| hash |
弱哈希 |
129 |
107 |
236 |
| ldapi |
LDAP注入 |
27 |
32 |
59 |
| pathtraver |
路径遍历 |
133 |
135 |
268 |
| securecookie |
不安全Cookie |
36 |
31 |
67 |
| sqli |
SQL注入 |
272 |
232 |
504 |
| trustbound |
不信任边界 |
83 |
43 |
126 |
| weakrand |
弱随机值 |
218 |
275 |
493 |
| xpathi |
xpath注入 |
15 |
20 |
35 |
| xss |
XSS攻击 |
246 |
209 |
455 |
| 总计 |
|
1415 |
1325 |
2740 |
打开CoBOT源代码缺陷检测工具,可以看到其支持Java语言的全部检测器, 大概296类,也就是能够检测296类缺陷和安全漏洞,对于是否支持上述11类安全漏洞,不想一个一个去对比了,直接先把OWASP Benchmark的测试案例让工具去检测吧。
检测过程很快,大概耗时20分钟左右,30多万的OWASP Benchmark源代码检测完成。逐一核对上述11类漏洞。比较麻烦的是这11类漏洞只是CoBOT支持检测器的很少一部分,需要逐一核对,才能确认检测出哪些漏洞。经过2个多小时核对,结果让我惊讶,CoBOT居然能够报出了所有的11类漏洞,2740个测试案例无一误报和漏报。各位,可以看看我整理的这个对应表2。
表2 CoBOT检测器与OWASP Benchmark基准11类安全漏洞对应关系
| 漏洞简称 |
漏洞全称 |
CWE编号 |
CoBOT检测器编号名称 |
| cmdi |
命令行注入 |
CWE-78 |
SE_05_03 潜在的命令行注入 |
| crypto |
弱密码 |
CWE-327 |
SE_01_02 使用弱密码哈希函数 |
| hash |
弱哈希 |
CWE-326 CWE-327 |
SE_01_02 使用弱密码哈希函数
|
| ldapi |
LDAP注入 |
CWE-90 |
SE_05_08 潜在的LDAP注入 |
| pathtraver |
路径遍历 |
CWE-22 |
SE_12_01 潜在的文件路径攻击 |
| securecookie |
不安全Cookie |
CWE614 |
SE_11_03 使用cookie存储敏感信息 SE_11_04 没有设置安全标志的cookie |
| sqli |
SQL注入 |
CWE-89 |
SE_05_10 潜在的SQL注入 |
| trustbound |
不信任边界 |
CWE-501
|
SE_05_11 应用程序在会话属性中混合可信和不可信数据 |
| weakrand |
弱随机值 |
CWE-79
|
SE_16_05 检测可预测伪随机生成器(PRG)的使用
|
| xpathi |
xpath注入 |
CWE-643 |
SE_17_05 来自ServletRequest和HttpServletRequest请求的参数值不安全 |
| xss |
XSS攻击 |
CWE-79 |
SE_10_03 Servlet中潜在的XSS |
CoBOT对OWASP 1.2基准所涉及的2740个测试案例进行检测,检测结果是100%的真阳性率,0%的假阳性率,故Youden指数(约登指数)结果为1。请看下面的结果,这个是我通过其OWASP Benchmark自带工具生成打分卡程序自动生成的。
CoBOT工具的检测结果如下:
表3 CoBOT的OWASP Benchmark的TPR和FPR
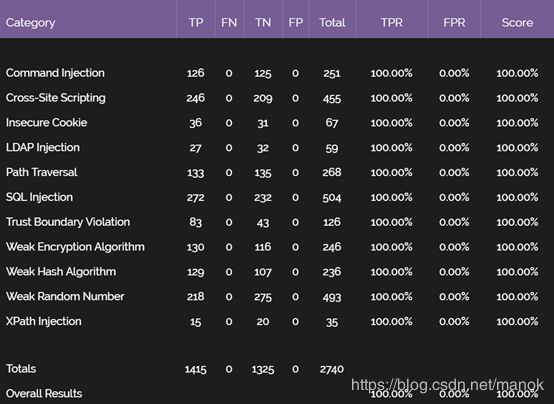
详细数据如下:
表4 CoBOT的OWASP Benchmark各指标数值统计表
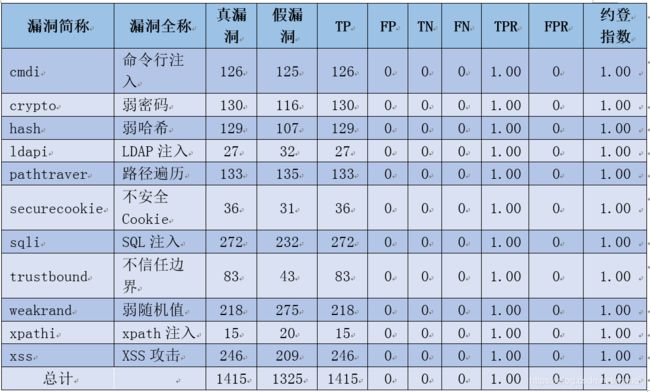
生成评分卡如下:
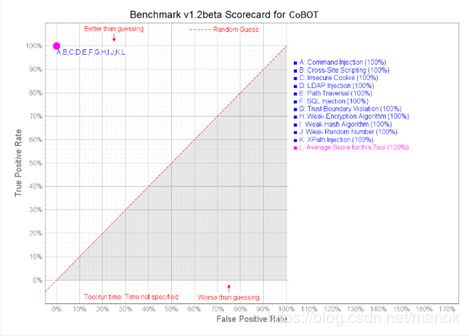
图一:CoBOT的Benchmark V1.2评分卡
通过仔细核对,CoBOT在进行OWASP Benchmark基准测试中对2740项测试的通过率是100%,获得了Youden(约登指数)指数1.00的好成绩,意味100%的TPR和0%的FPR,没有出现任何的假阴性或假阳性,也就是没有任何误报和漏报,远远超过了在OWASP网站公布的其它开源工具和商业工具的约登指数。 我把测评验证结果,与其它国内外同类工具公布的约登指数放在了一张表中,对比如下:
表5 10款静态分析工具的OWASP基准测试结果
| 检测工具 |
Benchmark 版本 |
TPR |
FPR |
约登指数 |
| CoBOT |
1.2 |
1.00 |
0.00 |
1.00 |
| ShiftLeft |
1.2 |
1.00 |
0.25 |
0.75 |
| FBwFindSecBugs |
1.2 |
0.97 |
0.58 |
0.39 |
| SonarQube |
1.2 |
0.50 |
0.17 |
0.33 |
| SAST-04 |
1.1 |
0.61 |
0.29 |
0.33 |
| SAST-06 |
1.1 |
0.85 |
0.52 |
0.33 |
| SAST-02 |
1.1 |
0.56 |
0.26 |
0.31 |
| SAST-03 |
1.1 |
0.46 |
0.21 |
0.25 |
| SAST-05 |
1.1 |
0.48 |
0.29 |
0.19 |
| SAST-01 |
1.1 |
0.29 |
0.12 |
0.17 |
| PMD |
1.2 |
0.00 |
0.00 |
0.00 |
注:已知商业SAST工具01-06包括Checkmarx、Fortify、Appscan、Coverity、Jtest、SourceMeter和Veracode Sast七款工具中的六款。
的确没有想到,国内研发的这款工具,取得如此好的测评结果。起码证明了国内具有自主知识产权的静态分析工具的检测能力已经达到或超过了国内外同类工具的水平。现在很多企业采用SonarQube的开源版本进行检测,会发现工具有很多的误报和漏报,开发人员或测试人员需要消耗大量时间去核对每一个检测出的漏洞或缺陷,这样一定程度上会影响工作效率。其实从上表可以看到,SonarQube的约登指数只有0.33,这说明SonarQube只能检测出50%的缺陷或漏洞,但是又会产生17%的误报。目前,代码安全审计越来越重要,通过CoBOT这样的检测工具肯定能提升检测效率。
有兴趣的朋友,可以去下载一份OWASP Benchmark,验证一下你采用工具的约登指数是什么水平。也欢迎研究这方面工具的同行一起交流。
https://github.com/OWASP/Benchmark
(完)