《基于CUDA的并行程序设计》学习笔记(三)——下

第3章 CUDA编程基础
3.5 “HelloWorld”CUDA 编程实例
安装完Visual Studio 2013软件并配置好CUDA开发环境。本节我们正式CUDA编程。
首先我们打开vs2013,点击新建工程,选中CUDA 7.5的模板。输入工程名等信息,完成工程的创建。
创建完工程后,会默认有一个kernel.cu的文件,其实现的是矩阵相加,这时候可以直接调试运行,如果没有报错则证明可以进行CUDA编程了。

可能会出现,下面这种无法识别<<<符号的情况,但是目测不影响结果的输出。

运行结果如下:

如果想编写运行自己的程序,则需要先移除kernel.cu文件,不然会出现main函数重复声明。
我们现在开始编写自己的CUDA程序,首先移除原来的kernel.cu文件,然后右键工程名,选择添加新item。
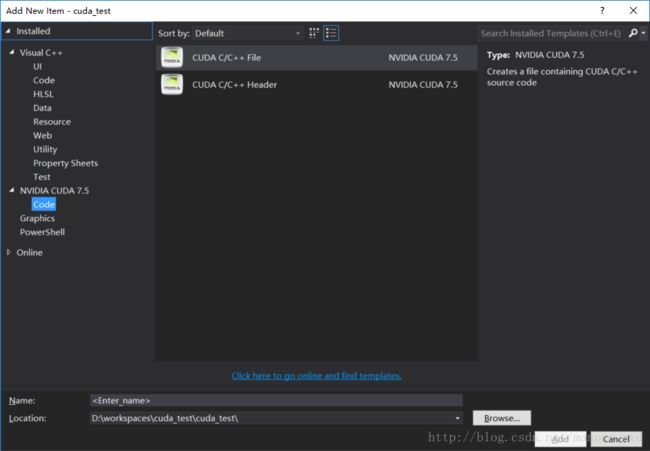
选择CUDA C/C++ File,然后输入文件名为main,就可以得到一个空的main.cu文件。在文件中输入如下代码:
#include InitCUDA()中会先呼叫 cudaGetDeviceCount 函式,取得支持 CUDA 的装置的数目。如果系统上没有支持 CUDA 的装置,则它会传回 1,而 device 0 会是一个仿真的装置,但不支持 CUDA 1.0 以上的功能。所以,要确定系统上是否有支持 CUDA 的装置,需要对每个 device 呼叫 cudaGetDeviceProperties 函式,取得装置的各项数据,并判断装置支持的 CUDA 版本(prop.major 和 prop.minor 分别代表装置支持的版本号码,例如 1.0 则 prop.major 为 1 而 prop.minor 为 0)。
透过 cudaGetDeviceProperties 函式可以取得许多数据,除了装置支持的 CUDA 版本之外,还有装置的名称、内存的大小、最大的 thread 数目、执行单元的频率等等。详情可参考 NVIDIA 的 CUDA Programming Guide。
在找到支持 CUDA 1.0 以上的装置之后,就可以呼叫 cudaSetDevice 函式,把它设为目前要使用的装置。
编译后输出如下:

能正确输出上述结果,则代表第一个完整的CUDA程序到此结束了。但是这个项目的结构看上去一点也不规范化,所有的代码都写到一个源文件里,这样的代码不易读懂,也不好定位程序的错误。CUDA程序一般可以进行如下图所示的文件结构管理。

如上图所示,编写CUDA程序过程中,若某个功能适合串行,则编写串行代码在CPU端执行,若适合并行,则编写CUDA并行代码在GPU端执行。CUDA并行代码的机构应进行如下分离:
(1) CUDA程序调用接口封装了和CUDA相关的函数,一般位于.cpp文件中。
(2) CUDA主机端代码的主要功能包括选择计算设备,进行GPU端存储器的分配、主机端与设备端直接的数据复制及调用kernel函数等准备工作,一般位于一个独立的.cu文件中。
(3) CUDA设备端代码主要指GPU端执行的核心代码kernel函数。kernel函数可能有多个,各个kernel函数各自放在一个单独的以kernel函数功能命名的.cu文件下,因此kernel函数相关的文件可能有多个。
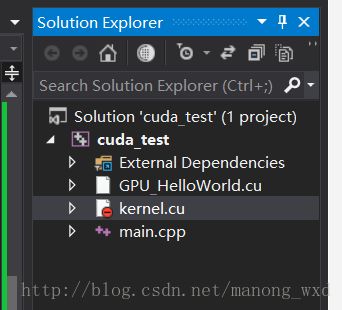
根据以上代码管理的方法,对HelloWordl程序改写如下:在源文件创建3个文件(main.cpp、kernel.cu和GPU_HelloWorld.cu)。main.cpp中调用核函数GPU_HelloWorld(host_str1, host_str2)相当于上述结构中的“GPU函数”,kernel.cu文件相当于上述结构中的“kernel函数”。
main.cpp文件主要包含了一个完整程序执行的主框架,其代码改写如下:
#includekernel.cu文件为GPU端执行函数的核心代码,其代码如下:
#include GPU_HelloWorld.cu文件作用是为kernel函数选择可用的计算设备并进行调用环境准备,其代码如下:
#include "kernel.cu"
#include 编译运行结构修改后的项目,将得到和修改前一样的运行结果。编译时需要将kernel.cu文件从项目生成中排除,否则编译连接时会出错。
注:如何从生成项目中移除
(1) 右键想要移除的文件,选择属性
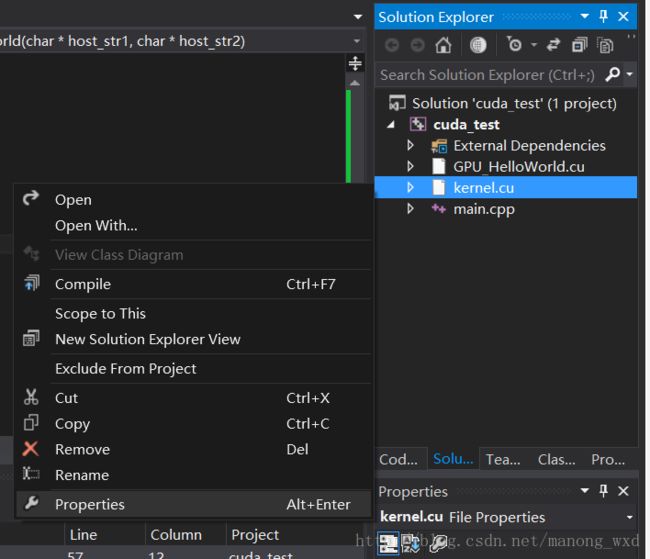
(2) 点击右侧的从从生成中移除的yes,然后点击确定
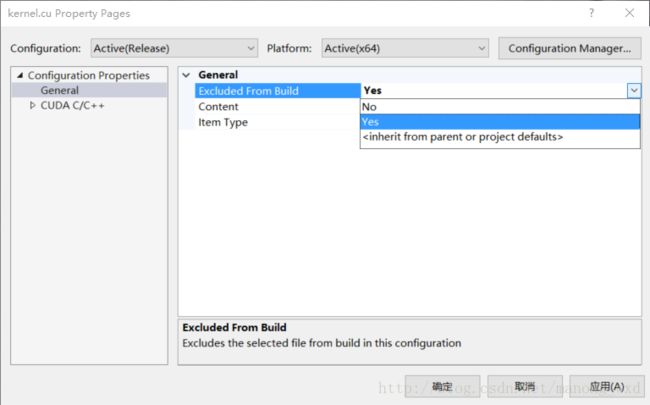
(3) 弄好了后看到之前选择文件上有一个红色提示符