K-means & Mean shift algorithm
个人理解的简单思想,很多改进的或变形的还没有来得及看!
K-means:
1.先确定好分类数目K,并选取这K个类的中心点。
2.对任一点求它到这K个目标点的距离,离谁最近就划为该类。
3.更新这个类的中心,即所有点的均值。
4.直至这些中心点不再更新。
Meanshift:
1.选取好特征空间(特征及度量?),任意找一个种子点,设定好窗口。
2.找这个窗口的密度中心。若种子点与它不重合,则更新为当前点(即密度中心作为新的种子点)。
3.以新种子点作为窗口中心重复上面的步骤直至收敛。
以下是英文的一些解释
K-means clustering:
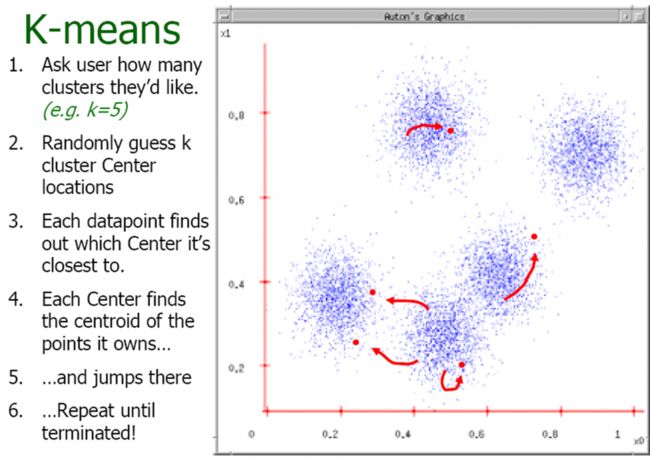
•Basic idea: randomly initialize thekcluster centers, and iterate between the two steps we just saw.
1.Randomly initialize the clustercenters, c1, ...,cK
2.Given cluster centers, determinepoints in each cluster
•For each point p, find the closestci. Put p into clusteri
3.Given points in each cluster, solveforci
•Set ci to be the mean of points inclusteri
4.If ci have changed, repeat Step 2
Properties
•Will always converge tosome solution
•Can be a “local minimum”
•does not always find the globalminimum of objective function:
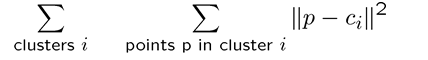
Meanshift algorithm:
•
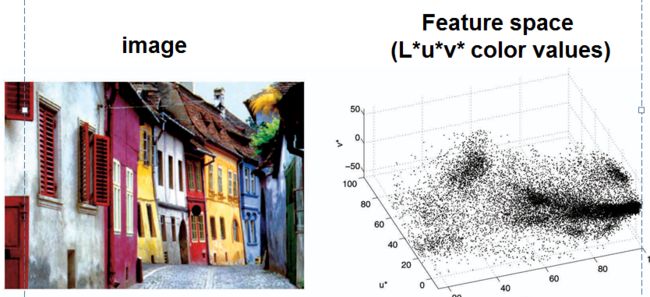
The mean shift algorithm seeks
modes
or local maxima of density in the feature space
•
Cluster: all data points in theattraction basin of a mode
•
Attraction basin: the region for whichall trajectories lead to the same mode
•
Find features (color, gradients, texture,
etc
)
•
Initialize windows at individual featurepoints
•
Perform mean shift for each window untilconvergence
•
Merge windows that end up near the same“peak” or mode

•
Pros
:
–
Does not assume shape on clusters
–
One parameter choice (window size)
–
Generic technique
–
Find multiple modes
•
Cons
:
–
Selection of window size
–
Does not scale well with dimensionof feature space