二次线上JVM调优(上线GC次数过多和promotion failed)
先说明一下环境:
外网20台机器:4核8G JDK8
内网1台机器:32核128G JDK8
上线GC次数超大
线上的机器每次在上线的时候都会爆出来大量的GC,这按说是一个正常的现象,但是GC的次数明显超过了报警的阈值,所以找了一下原因,在这里记录一下这次解决问题的步骤
1、首先根据以下两个方式找到相应的进程号
top | grep java
ps -ef |grep java2、然后根据进程号去heap一下
jmap -heap 20563
打印出以下的数据结果
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1431633920 (332.75MB)
MaxNewSize = 1431633920 (332.75MB)
OldSize = 2863333376 (3230.6875MB)
NewRatio = 2
SurvivorRatio = 3
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)jmap -histo 20563 输出信息包括类名,对象数量,对象占用大小
num #instances #bytes class name
----------------------------------------------
727: 47 1880 com.ServiceMetadata
728: 78 1872 com.servcicel$12
729: 78 1872 redis.clients.jedis.Tuple
730: 33 1848 com.yammer.metrics.core.Meter
731: 115 1840 java.util.concurrent.atomic.AtomicLongArray
jstat -gcutil 20563 1000 5 查看GC的情况 后边三个参数分别是次数,间隔的毫秒
[]$ jstat -gcutil 20563 2000 10
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 46.48 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 46.73 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 46.81 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 46.88 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 47.16 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 47.23 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 47.31 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 47.36 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 47.41 1.43 97.26 95.40 100 2.951 8 0.807 3.758
0.00 0.00 47.47 1.43 97.26 95.40 100 2.951 8 0.807 3.758
// 参数解释:
Options — 选项,我们一般使用 -gcutil 查看gc情况
vmid — VM的进程号,即当前运行的java进程号
interval– 间隔时间,单位为秒或者毫秒
count — 打印次数,如果缺省则打印无数次
S0 — Heap上的 Survivor space 0 区已使用空间的百分比
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
E — Heap上的 Eden space 区已使用空间的百分比
O — Heap上的 Old space 区已使用空间的百分比
P — Perm space 区已使用空间的百分比
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
jps -v
JVM的配置情况
jvm_args="-Xmx4096m -Xms4096m -verbose:gc -Xloggc:${logPath}/gc-${MOAPort}.log -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:MaxTenuringThreshold=15 -XX:-UseAdaptiveSizePolicy -XX:PermSize=256M -XX:MaxPermSize=512M -XX:SurvivorRatio=3 -XX:+PrintGCDateStamps -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+AlwaysPreTouch "通过对比参数我们发现一个问题就是新生代分别的值不和常规,常理情况下,newRatio默认值应该是2,也就是说老年代占整个内存的三分之二,年轻代是三分之一,差不多1G多了,上边heap出来的值远不是这样的;然后就开始查原因是为什么?最后在Oracle官网找到了这个:
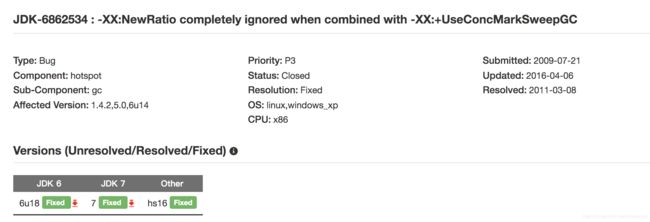
newRatio参数在1.4.2,5.0,6u14这几个版本号在CMS中默认是完全失效的,解决的版本是6u18和7,按说我们用的8也是OK的呀,但是依旧是有问题的,接着查,然后找到了这个: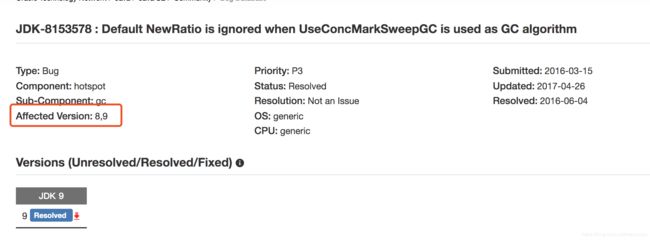
在JDK8和9这两个大版本CMS使用GC算法的时候又是默认忽略的,那我们就找到原因了,怎么解决这个问题的,官方给了三个方案:
1、Option #1 : Default GC (-XX:+UseParallelGC) : PSYoungGen,不用CMS
2、Option #2 : UseConcMarkSweepGC only (-XX:+ UseConcMarkSweepGC) : par new generation total 153344K = 149.75 MB 继续使用,但是年轻代比较小
3、UseConcMarkSweepGC along with NewRatio=2 显示的的指定newRatio这个参数
OK,按照第三种方案修改了一下配置上线,heap以下发现确实OK了,上线时候大量GC的问题也解决了,下边列一下heap出来的参数:
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1431633920 (1365.3125MB)
MaxNewSize = 1431633920 (1365.3125MB)
OldSize = 2863333376 (2730.6875MB)
NewRatio = 2
SurvivorRatio = 3
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 1145307136 (1092.25MB)
used = 684326048 (652.6241760253906MB)
free = 460981088 (439.6258239746094MB)
59.75043955370937% used
Eden Space:
capacity = 858980352 (819.1875MB)
used = 670442392 (639.3836898803711MB)
free = 188537960 (179.8038101196289MB)
78.0509577942011% used
From Space:
capacity = 286326784 (273.0625MB)
used = 13883656 (13.240486145019531MB)
free = 272443128 (259.82201385498047MB)
4.848884832234207% used
To Space:
capacity = 286326784 (273.0625MB)
used = 0 (0.0MB)
free = 286326784 (273.0625MB)
0.0% used
concurrent mark-sweep generation:
capacity = 2863333376 (2730.6875MB)
used = 36032104 (34.362892150878906MB)
free = 2827301272 (2696.324607849121MB)
1.258397094170567% used
20852 interned Strings occupying 2125696 bytes.后台陆陆续续的发现我的其他项目也有这些问题,然后尝试了其他的解决方案,用了G1,这个更牛逼,上线GC的总次数由原来的5000左右,直接下降到60左右,平时GC的次数由原来的20左右降到4左右,提升效果非常的明显,至于G1为什么这么厉害,自行度娘就可以了。上边的问题没有完,我在内网看了一下这个机器的内存分配情况,发现新生的内存大小不是300多M,而是正常的这是为什么呢?继续看上边JDK8中bug指出的 when UseConcMarkSweepGC is used as GC algorithm,也就是说CMS在8和9中使用的年轻代的内存分配算法,而没有使用默认的newRatio参数,那我们就来看一下这个算法是什么?计算内存有两种方式:
第一种是max_heap/(NewRatio+1),也就是我们常用的熟悉的,然后默认失效的那种 4096/(2+1)= 1365.34
第二种是ScaleForWordSize(young_gen_per_worker * parallel_gc_threads) ,具体算法是64M * 32 * 13 / 10 = 2662.4M,具体怎么个过程我们看这篇文章,或者这里
总体算法是:
MIN2(max_heap/(NewRatio+1), ScaleForWordSize(young_gen_per_worker * parallel_gc_threads))也就是取第一种和第二种最小的那个,也就是我们看到的正常分配的情况了。至此我们的所有疑问都解决了。
promotion failed
CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行旧生代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。
promotion failed是在进行Minor GC时,survivor space放不下、对象只能放入旧生代,而此时旧生代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入旧生代,而此时旧生代空间不足造成的。
以上是原因,明显是代码有问题,然后通过果然发现有大对象,优化就是了,每次用完null
jmap -histo 20563 输出信息包括类名,对象数量,对象占用大小
num #instances #bytes class name
----------------------------------------------
727: 47 1880 com.service.ServiceMetadata
728: 78 1872 com.serivce$12
729: 78 1872 redis.clients.jedis.Tuple
730: 33 1848 com.yammer.metrics.core.Meter
731: 115 1840 java.util.concurrent.atomic.AtomicLongArray参考:
一次耗时的排查
https://www.jianshu.com/p/1a7b2d141611
长耗时
http://www.importnew.com/22886.html
降低新生代GC的时间
https://hllvm-group.iteye.com/group/topic/42357
显著降低的一次分析
https://www.cnblogs.com/sunzhenchao/p/6711275.html
full gc频繁
https://blog.csdn.net/varyall/article/details/80517977
比较系统的介绍GC调优
https://juejin.im/post/59f02f406fb9a0451869f01c
关于GC日志的解读
https://blog.csdn.net/renfufei/article/details/49230943
一次内存分配的堆的大小,模拟分配的实战性比较
https://www.ibm.com/developerworks/cn/java/j-lo-jvm-optimize-experience/index.html
几种fullGC的原因
https://blog.csdn.net/endlu/article/details/51144918