深度学习小白——DenseNet学习
原论文地址:https://arxiv.org/abs/1608.06993
用Keras写的pre-model代码地址:https://github.com/flyyufelix/DenseNet-Keras
一、主要原理
其借鉴了ResNet的思想,用dense connectivity的方式更加缩短了头尾之间层的连接,使得
在前向传播过程中,每一层都与其他所有层相连
于是一个有L层的DenseNet就有L(L+1)/2个连接,每一层都将之前所有层输出的feature map 连结起来作为自己的输入,然后再把自己的输出输送给之后的所有层

这个网络的优点如下:
1.减轻了梯度弥散的问题,使模型不容易过拟合
2.增强了特征在各个层之间的流动,因为每一层都与初始输入层还有最后的由loss function得到的梯度直接相连
3.大大减少了参数个数,提高训练效率
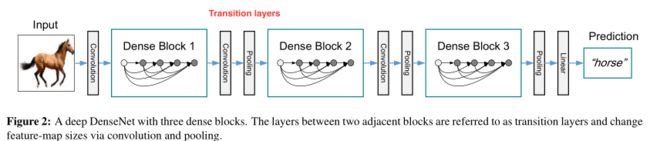
【与ResNet比较】
ResNet是引入了一个skip-connection使得每一层的输出为经过非线性变化的结果加上恒等于输入的函数![]()
而DenseNet为了更加提高信息在层与层之间的流动,它将每一层都与之后的每一层相连 ![]()
H括号里的就是0到 l-1层的所有feature maps的连结,这里的H是指BN+ReLU+3*3卷积的组合(同ResNet)
【几个特殊的地方】
1.Transition layers
由于在dense block中每经过一个conv_block,就要增加growth_rate个feature map,所以需要在一个dense block后加入transition layers来压缩一定数量的feature maps,保证训练的高效性。
2.在一个dense block里,每个conv_block的输出会与输入接在一起传递给下一个Conv block,以此类推,使得每个conv_block都彼此相连,且把feature map都连结起来,而不是加起来
【代码的研读】
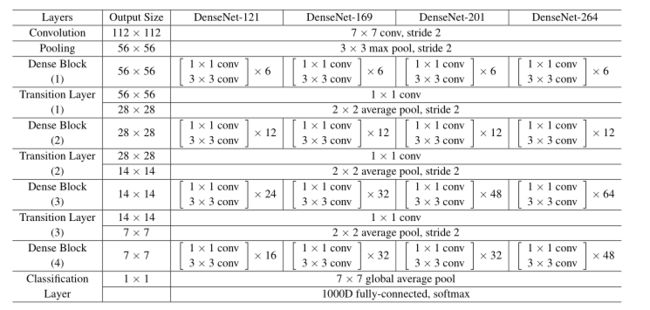
这里是训练ImageNet用的121层的网络结构,各个层配置如下:
from keras.models import Model
from keras.layers import Input, merge, ZeroPadding2D
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.convolutional import Convolution2D
from keras.layers.pooling import AveragePooling2D, GlobalAveragePooling2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
import keras.backend as K
from custom_layers import Scale
def DenseNet(nb_dense_block=4, growth_rate=32, nb_filter=64, reduction=0.0, dropout_rate=0.0, weight_decay=1e-4, classes=1000, weights_path=None):
'''Instantiate the DenseNet 121 architecture,
# Arguments
nb_dense_block: number of dense blocks to add to end
growth_rate: number of filters to add per dense block
nb_filter: initial number of filters
reduction: reduction factor of transition blocks. 1-theta
dropout_rate: dropout rate
weight_decay: weight decay factor
classes: optional number of classes to classify images
weights_path: path to pre-trained weights
# Returns
A Keras model instance.
'''
eps = 1.1e-5
# compute compression factor
compression = 1.0 - reduction
# Handle Dimension Ordering for different backends
global concat_axis
if K.image_dim_ordering() == 'tf':
concat_axis = 3# 通道数在第三维
img_input = Input(shape=(224, 224, 3), name='data')
else:
concat_axis = 1
img_input = Input(shape=(3, 224, 224), name='data')
# From architecture for ImageNet (Table 1 in the paper)
nb_filter = 64
nb_layers = [6,12,24,16] # For DenseNet-121
# Initial convolution
x = ZeroPadding2D((3, 3), name='conv1_zeropadding')(img_input)
x = Convolution2D(nb_filter, 7, 7, subsample=(2, 2), name='conv1', bias=False)(x)
x = BatchNormalization(epsilon=eps, axis=concat_axis, name='conv1_bn')(x)
x = Scale(axis=concat_axis, name='conv1_scale')(x)
x = Activation('relu', name='relu1')(x) #(?,112,112,64)
x = ZeroPadding2D((1, 1), name='pool1_zeropadding')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), name='pool1')(x) #(?,56,56,64)
# Add dense blocks
for block_idx in range(nb_dense_block - 1):
stage = block_idx+2
x, nb_filter = dense_block(x, stage, nb_layers[block_idx], nb_filter, growth_rate, dropout_rate=dropout_rate, weight_decay=weight_decay)
# Add transition_block
x = transition_block(x, stage, nb_filter, compression=compression, dropout_rate=dropout_rate, weight_decay=weight_decay)
nb_filter = int(nb_filter * compression)
final_stage = stage + 1
x, nb_filter = dense_block(x, final_stage, nb_layers[-1], nb_filter, growth_rate, dropout_rate=dropout_rate, weight_decay=weight_decay)
x = BatchNormalization(epsilon=eps, axis=concat_axis, name='conv'+str(final_stage)+'_blk_bn')(x)
x = Scale(axis=concat_axis, name='conv'+str(final_stage)+'_blk_scale')(x)
x = Activation('relu', name='relu'+str(final_stage)+'_blk')(x)
x = GlobalAveragePooling2D(name='pool'+str(final_stage))(x)
x = Dense(classes, name='fc6')(x)
x = Activation('softmax', name='prob')(x)
model = Model(img_input, x, name='densenet')
if weights_path is not None:
model.load_weights(weights_path)
return model
def conv_block(x, stage, branch, nb_filter, dropout_rate=None, weight_decay=1e-4):
'''Apply BatchNorm, Relu, bottleneck 1x1 Conv2D, 3x3 Conv2D, and option dropout
# Arguments
x: input tensor
stage: index for dense block
branch: layer index within each dense block
nb_filter: number of filters
dropout_rate: dropout rate
weight_decay: weight decay factor
'''
eps = 1.1e-5
conv_name_base = 'conv' + str(stage) + '_' + str(branch)
relu_name_base = 'relu' + str(stage) + '_' + str(branch)
# 1x1 Convolution (Bottleneck layer)
inter_channel = nb_filter * 4
x = BatchNormalization(epsilon=eps, axis=concat_axis, name=conv_name_base+'_x1_bn')(x)
x = Scale(axis=concat_axis, name=conv_name_base+'_x1_scale')(x)
x = Activation('relu', name=relu_name_base+'_x1')(x)
x = Convolution2D(inter_channel, 1, 1, name=conv_name_base+'_x1', bias=False)(x)
if dropout_rate:
x = Dropout(dropout_rate)(x)
# 3x3 Convolution
x = BatchNormalization(epsilon=eps, axis=concat_axis, name=conv_name_base+'_x2_bn')(x)
x = Scale(axis=concat_axis, name=conv_name_base+'_x2_scale')(x)
x = Activation('relu', name=relu_name_base+'_x2')(x)
x = ZeroPadding2D((1, 1), name=conv_name_base+'_x2_zeropadding')(x)
x = Convolution2D(nb_filter, 3, 3, name=conv_name_base+'_x2', bias=False)(x)
if dropout_rate:
x = Dropout(dropout_rate)(x)
return x
def transition_block(x, stage, nb_filter, compression=1.0, dropout_rate=None, weight_decay=1E-4):
''' Apply BatchNorm, 1x1 Convolution, averagePooling, optional compression, dropout
# Arguments
x: input tensor
stage: index for dense block
nb_filter: number of filters
compression: calculated as 1 - reduction. Reduces the number of feature maps in the transition block.
dropout_rate: dropout rate
weight_decay: weight decay factor
'''
eps = 1.1e-5
conv_name_base = 'conv' + str(stage) + '_blk'
relu_name_base = 'relu' + str(stage) + '_blk'
pool_name_base = 'pool' + str(stage)
x = BatchNormalization(epsilon=eps, axis=concat_axis, name=conv_name_base+'_bn')(x)
x = Scale(axis=concat_axis, name=conv_name_base+'_scale')(x)
x = Activation('relu', name=relu_name_base)(x)
x = Convolution2D(int(nb_filter * compression), 1, 1, name=conv_name_base, bias=False)(x)
if dropout_rate:
x = Dropout(dropout_rate)(x)
x = AveragePooling2D((2, 2), strides=(2, 2), name=pool_name_base)(x)
return x
def dense_block(x, stage, nb_layers, nb_filter, growth_rate, dropout_rate=None, weight_decay=1e-4, grow_nb_filters=True):
''' Build a dense_block where the output of each conv_block is fed to subsequent ones
# Arguments
x: input tensor
stage: index for dense block
nb_layers: the number of layers of conv_block to append to the model.
nb_filter: number of filters
growth_rate: growth rate
dropout_rate: dropout rate
weight_decay: weight decay factor
grow_nb_filters: flag to decide to allow number of filters to grow
'''
eps = 1.1e-5
concat_feat = x
for i in range(nb_layers):
branch = i+1
x = conv_block(concat_feat, stage, branch, growth_rate, dropout_rate, weight_decay)
concat_feat = merge([concat_feat, x], mode='concat', concat_axis=concat_axis, name='concat_'+str(stage)+'_'+str(branch))
if grow_nb_filters:
nb_filter += growth_rate
return concat_feat, nb_filter
1.keras.layers.convolutional.ZeroPadding2D(padding=(1,1), data_format=None)
对2D输入(如图片)的边界填充0,以控制卷积以后特征图的大小
-
padding:整数tuple,表示在要填充的轴的起始和结束处填充0的数目,这里要填充的轴是轴3和轴4(即在'th'模式下图像的行和列,在‘channels_last’模式下要填充的则是轴2,3
-
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
-
filters:卷积核的数目(即输出的维度)
-
kernel_size:单个整数或由两个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
-
strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
-
padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
-
activation:激活函数,如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
-
dilation_rate:单个整数或由两个个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
- axis: 整数,指定要规范化的轴,通常为特征轴。例如在进行
data_format="channels_last"的2D卷积后,一般会设axis=3。 - momentum: 动态均值的动量
- epsilon:大于0的小浮点数,用于防止除0错误
- center: 若设为True,将会将beta作为偏置加上去,否则忽略参数beta
- scale: 若设为True,则会乘以gamma,否则不使用gamma。当下一层是线性的时,可以设False,因为scaling的操作将被下一层执行。
这里作者自己编写Scale层用于scaling the input data:out=in*gamma+beta 用于接在BN之后,具体看custom_layers.py
注意,编写自己的层一般框架如下:
from keras import backend as K
from keras.engine.topology import Layer
import numpy as np
class MyLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
# Create a trainable weight variable for this layer.
self.kernel = self.add_weight(name='kernel',
shape=(input_shape[1], self.output_dim),
initializer='uniform',
trainable=True)
super(MyLayer, self).build(input_shape) # Be sure to call this somewhere!
def call(self, x):
return K.dot(x, self.kernel)
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)-
build(input_shape):这是定义权重的方法,可训练的权应该在这里被加入列表`self.trainable_weights中。其他的属性还包括self.non_trainabe_weights(列表)和self.updates(需要更新的形如(tensor, new_tensor)的tuple的列表)。你可以参考BatchNormalization层的实现来学习如何使用上面两个属性。这个方法必须设置self.built = True,可通过调用super([layer],self).build()实现 -
call(x):这是定义层功能的方法,除非你希望你写的层支持masking,否则你只需要关心call的第一个参数:输入张量 -
compute_output_shape(input_shape):如果你的层修改了输入数据的shape,你应该在这里指定shape变化的方法,这个函数使得Keras可以做自动shape推断
x:输入的tensor
stage:dense block的id
branch: 一个dense block 里layer的id
nb_filter:number of filters,这里就是growth_rate(32)
一个Conv Block里包含 一个Bottleneck layer(BN+relu+1*1conv), 然后是 BN+relu+zeropadding+3*3conv
其中1*1卷积的滤波器个数为4*nb_filter
6.Dense Block(x, stage, nb_layers, nb_filter, growth_rate, dropout_rate=None, weight_decay=1e-4, grow_nb_filters=True)
Arguments
x: input tensor
stage: index for dense block
nb_layers: the number of layers of conv_block to append to the model.
nb_filter: number of filters
growth_rate: growth rate
dropout_rate: dropout rate
weight_decay: weight decay factor
grow_nb_filters: flag to decide to allow number of filters to grow
如论文中图示,在一个dense block里,每一个conv_block的输出都要送到之后的每个conv_block里
在得到每个conv_block的输出后,将输入的特征图与输出的连结在一起
【merge】--keras.layers.Merge类下的方法
concat_feat=merge([concat_feat, x], mode='concat', concat_axis=concat_axis, name='concat_'+str(stage)+'_'+str(branch))
输入(?,56,56,64)维的tensor,然后经过一次conv_block,输出(?,56,56,32)维的tensor,连结起来就是
(?,56,56,96)维的tensor,第一个dense block里有6个conv_blocks所以增加了6*32=192个feature map,加上最初输入的64维,最终第一个dense_block输出为(?,56,56,256)
7.Transition Block
transition_block(x, stage, nb_filter, compression=1.0, dropout_rate=None, weight_decay=1E-4):
compression: 意思是1-reduction(0.5)
为了进一步压缩模型,在transition block要减少feature map的个数
transition block包括:BN+ relu + 1*1conv + average pooling,其中1*1conv的filter数为nb_filter*compression
最后输出(?,28,28,128)维tensor
8.GlobalAveragePooling2D()--为时域信号施加全局平均值池化
输入(?,7,7,1024),输出(?,1024)
9.优化器--SGD
keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False)
decay:每一次更新后的学习率衰减值
此处momentum=0.9,nesterov=True,所以是采用nesterov动量更新的方式