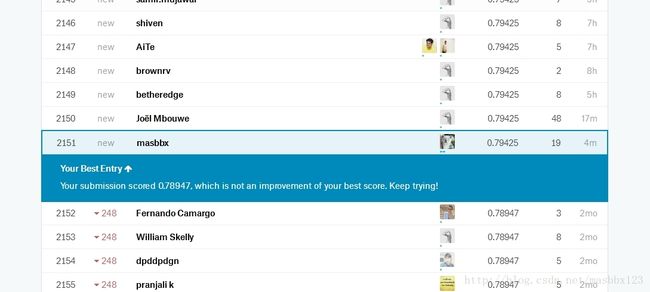
Kaggle中Titanic项目简单入门
首先,再kaggle注册帐号,找到Titanic项目,9659个队伍,估计全部都是菜鸟:
下载train和test集,提交的文件:
首先,二话不说,先把下载的《gender_submission.csv》直接提交上去:

这样,我们就得到了第一个成绩:0.76555,还行,好歹比2xxx多个队伍强。
再看看说明,最终评价的标准是ACC
下面开始正式干活了:
先导入各种库,读取训练集。
#coding=utf-8
import pandas as pd
from pandas import Series,DataFrame
import random
import numpy as np
from datetime import date
import datetime as dt
from numpy import nan as NA
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingRegressor
import warnings
warnings.filterwarnings("ignore")
#读取数据
traindata = pd.read_csv("train.csv",header=0)
testdata = pd.read_csv("test.csv",header=0)
print(traindata.shape)
print(traindata.head(5))下面开始数据清理了,
首先看看哪里有缺失值:(Age,Cabin,Embarked,Fare
print(traindata.isnull().any())
print(testdata.isnull().any())最终输出:
PassengerId False
Survived False
Pclass False
Name False
Sex False
Age True
SibSp False
Parch False
Ticket False
Fare False
Cabin True
Embarked True
dtype: bool
PassengerId False
Pclass False
Name False
Sex False
Age True
SibSp False
Parch False
Ticket False
Fare True
Cabin True
Embarked False
dtype: bool
下面我们一个一个变量看过去:
和下列代码类似:
print(traindata.Survived.describe())PassengerId没啥好说的,就是个ID号,
Survived是否生存的标记,0,1
Pclass票价等级,1、2、3
Name姓名,为了简单起见,我们先不使用这个特征
Sex,性别,我们转换为0、1(乘客男的更加多点)
traindata.Sex[traindata.Sex=='male'] = 0
traindata.Sex[traindata.Sex=='female'] = 1
print(traindata.Sex.describe())
testdata.Sex[testdata.Sex=='male'] = 0
testdata.Sex[testdata.Sex=='female'] = 1
print(testdata.Sex.describe())Age年龄,train和test集都有很多缺失值,均值都是30左右
所以,我们使用30来替换缺失值(train和test集的分布都差不多)
traindata.Age[traindata.Age.isnull()] = 30
print(traindata.Age.describe())
testdata.Age[testdata.Age.isnull()] = 30
print(testdata.Age.describe())SibSp,Parch,没看明白什么意思,反正都是数据
Ticket,票的编号,这个似乎没有什么用吧,先不管了
Fare,票价,其中test集有缺失值,为了简单起见,直接用均值35代替
testdata.Fare[testdata.Fare.isnull()]=35
print(testdata.Fare.describe())Cabin,船仓,为简单起见,不考虑了
Embarked,上船港口,为简单起见,也不考虑了
数据清理就先这样了,下面开始建立模型:
UseFlag = traindata['Survived'].values
#print(UseFlag)
UseFeature = traindata[['Pclass','Sex','Age','SibSp','Parch','Fare']].values
#print(UseFeature)
rf=RandomForestClassifier()#这里使用了默认的参数设置
rf.fit(UseFeature,UseFlag)#进行模型的训练
temp = rf.predict(UseFeature)
#print(temp)
from sklearn.metrics import accuracy_score
accuracy_score(UseFlag, temp)输出测试集合的ACC:0.969696
下面我们预测test集
TestFeature = testdata[['Pclass','Sex','Age','SibSp','Parch','Fare']].values
temp = rf.predict(TestFeature)
testdata['Survived']=temp
outdata = testdata[['PassengerId','Survived']]#提取出需要的列
outdata.to_csv("test_2018_2_11.csv",index=False,header=True)#保存数据集搞定了,直接提交数据:0.73684,比默认的还差,晕倒了!
修改参数,改成100棵数,0.74162
加入PCA:0.56459
from sklearn.decomposition import PCA
pca = PCA(n_components=4)
pca.fit(UseFeature)
UseFeature = pca.transform(UseFeature)加入数据归一化,0.73205
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(UseFeature)
scaler.transform(UseFeature)逻辑回归,0.75119
from sklearn.linear_model import LogisticRegression
LC = LogisticRegression()
LC.fit(UseFeature,UseFlag)#进行模型的训练 SVM,0.75119
from sklearn import svm
rf = svm.SVC(gamma=0.001, C=100.)
rf.fit(UseFeature,UseFlag)#进行模型的训练 SVM RF LR加一起投票:0.76076
为什么都这么弱爆了……我需要静静……
ps:后来查询了别人写的文章,当时0.76还能排名到2000名左右的,说明本文的步骤和结果是没有问题的,就是入门级别的最简单的模型。
2018-2-12
使用了GBDT,发现GBDT很不错,0.78947
然后SVM RF LR GBDT加一起投票:0.79425
今天机会用完了,好歹差不多2000名了,就这样吧,不搞了: