算法与数据结构(1),List
算法与数据结构(2),Map
算法与数据结构(3),并发结构
睡了不到六个小时,被一个很奇葩又很奇怪的梦吓醒,以最快的速度穿好衣服,跑下楼去买了杯咖啡上来,文字没写多少,咖啡倒是一饮而尽。
Map是一种非常有用的数据结构。先为大家画一张简单的Map类族图。
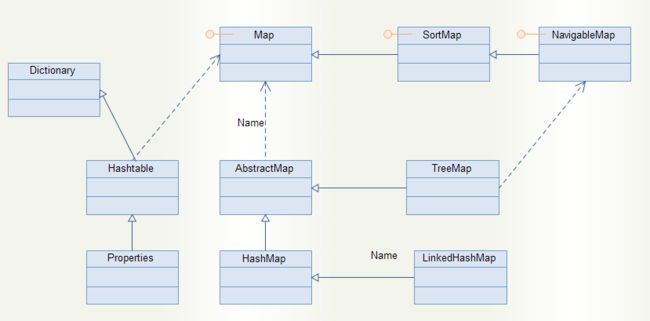
上图表示,Map类族中主要实现类有Hashtable,HashMap,LinkedHashMap,TreeMap。在Hashtable子类中,还有Properties类的实现。
这里主要说明Hashtable和HashMap并没有太大的差异,类似ArrayList和Vector。
这里主要说明三点:
- Hashtable的大部分方法做了同步,而HashMap没有,因此HashMap不是线程安全的。
- Hashtable不允许key或者value使用null值,而HashMap可以。
- 在内部算法上,他们对key的hash算法和hash值到内存索引的映射算法不同。
HashMap的实现原理
HashMap就是将key做hash算法,然后将hash值映射到内存地址,直接取得key所对应的数据。在HashMap中低层数据结构使用的是数组,所谓的内存地址即素组的下标索引。
HashMap的高性能需要保证以下几点:
- hash算法必须是高效的;
- hash值到内存地址(数组索引)的算法是快速的;
- 根据内存地址(数组索引)可以直接取得对应的值。
首先先来看第一点,hash算法的高效性。
int hash = hash(key.hashCode());
public native int hashCode();
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
第一行代码是HashMap中用于计算key的hash值,它前后分别调用了Object类的hashCode( )方法和HashMap的内部函数hash( )。Object类中hashCode( )方法是默认的native的实现,可以认为不存在性能问题。而hash( )函数的实现全部基于位运算,因此,也是高效的。
native方法通常比一般的方法快,因为他直接调用操作系统本地链接库的API。由于hashCode( )方法是可以重载的,因此,为了保证HashMap的性能,需要确保相关的hashCode( )是高效的。而位运算也比算数、逻辑运算快。
当取得key的hash值后需要通过hash值得到内存地址:
int i = indexFor(hash, table.length);
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
indexFor( )函数通过将hash值和数组长度按位取与直接得到数组索引。
最后由indexFor( )函数返回的数组索引直接通过数组下标便可取得对应的值,直接内存访问速度也是相当快的。因此,可以认为HashMap是高性能的。
Hash冲突
如下图所示需要存放到HashMap中的两个元素1和2,通过hash计算后,发现对应在内存中的同一个地址。

那么HashMap是如何处理Hash冲突的呢,这就要深入HashMap,从HashMap的数据结构说起。
虽然HashMap的底层实现使用的数组,但是数组内的元素并不是简单的值,而是一个Entry对象,如下图所示
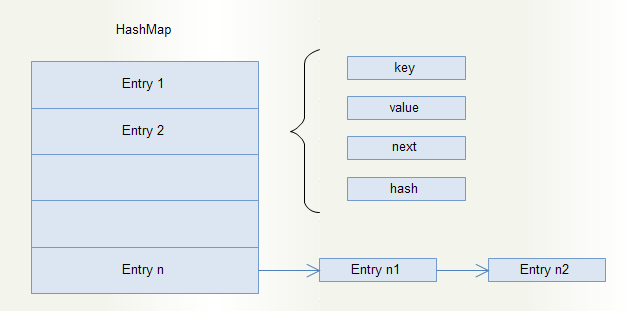
可以看到HashMap的内部维护着一个Entry数组,每一个Entry表项包括key、value、next、hash。这里特别注意,其中next,它指向一个Entry。通过解析HashMap的put( )方法,可以看到当put( )有冲突时,新的Entry依然会被安放在对应的索引下标内,并替换原有的值。同时,为了保证旧值不丢失,会将新的Entry的next指向旧指,这便实现了,在一个数组索引空间内存放多个值项。
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
/*如果当前的key已经存在于HashMap中*/
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //取得旧值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
modCount++;
addEntry(hash, key, value, i); //添加当前表项到i位置
return null;
}
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex]; //取得当前位置的Entry
/*将新增加元素放到i的位置,并将他的next指向旧的元素*/
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
基于HashMap的这种实现机制,只要hashCode( )和hash( )方法实现的足够好,能够尽可能的减少冲突,那么对HashMap的操作几乎等价于对数组的随机访问,具有很好的性能。但是,如果hashCode( )和hash( )方法实现的较差,在大量冲突产生的情况下,HashMap事实上就退化为几个链表,在上一遍博客中,我曾提到过,对链表结构进行随机访问,性能是很差的,这个时候对HashMap的操作无异于遍历链表。
负载因子
除hashCode( )的实现外,影响HashMap性能的还有还有它的容量参数。和ArrayList和Vector一样,这种基于数组的结构,不可避免的需要在数组空间不足时,进行扩容。而数组的重组相对而言较为耗时。
HashMap提供了两个可以指定初始化容量的构造函数:
public HashMap(int initialCapacity)
public HashMap(int initialCapacity, float loadFactor)
其中initialCapacity指定了HashMap的初始容量,loadFactor指定了其负载因子。初始容量即数组的大小,HashMap会使用大于等于initialCapacity并且是2的指数次幂的最小整数作为内置数组的大小(比如,传入initialCapacity的参数为10,2^3 = 8 < 10 < 2^4 = 16,则16作为内置数组的初始化容量)。负载因子又叫做填充比,它是介于0和1之间的浮点数,它决定了HashMap在扩容之前,其内部数组的填充度。默认情况下HashMap初始容量为16,负载因子为0.75。
负载因子 = 元素个数 / 内部数组总大小
loadFactor = threshold / capacity
在实际使用中,负载因子也可以设置为大于1的数,但如果这样做,HashMap会产生大量冲突,无异于尝试往只有10个口袋的书包里放15个苹果。必然有的口袋要装多余一个苹果。
在HashMap内部,还维护了一个threshold变量,它始终被定义为当前数组总容量和负载因子的乘积,它表示HashMap的阈值,。当HashMap的实际容量超过阈值时,便会进行扩容。因此,HashMap的实际填充率不会超过负载因子。
有关HashMap扩容相关代码如下:
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
/*创建新的数组*/
Entry[] newTable = new Entry[newCapacity];
/*将所有数组转移到新的数组中*/
transfer(newTable);
table = newTable;
/*重新设置阈值,为新的容量和负载因子的乘积*/
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
/*遍历源数组内所有元素*/
for (int j = 0; j < src.length; j++) {
Entry e = src[j];
/*当该表项索引有值存在时,则进行迁移*/
if (e != null) {
src[j] = null;
do {
/*进行数据迁移,该索引值下有冲突记录*/
Entry next = e.next;
/*计算该表项在新数组内的索引,并放置到新的数组中,然后建立新的链表关系*/
/*因为新的容量变大,所以每个元素的哈希值和位置都是不一样的*/
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
通过扩容,可以很明显的看到,该操作会遍历整个HashMap,所以,应该尽量避免该操作的发生,设置合理的初始化大小和负载因子,可以有效的减少HashMap扩容的次数。
HashMap中默认的负载因子为0.75,直接分配较大的初始容量可以较少扩容次数,但是这样有会造成内存的浪费。而在尽可能避免扩容次数的情况下,一个较大的负载因子,就意味着使用使用较少的内存空间,而空间越小,就越容易引起hash冲突,因此,更加需要一个可靠,高效的hashCode( )算法。
HashMap的性能在一定程度上取决于
hashCode( )的实现,一个好的hashCode( )算法,可以尽可能减少冲突,从而提高HashMap的访问速度。
LinkedHashMap
总体来说HashMap的性能表现是不错的,但是,它最大的缺点就是无序性,被存入内置数组中的元素,再遍历数组时,输出的总是无序的。如果需希望元素保存输入是的顺序,则需要使用LinkedHashMap。
LinkedHashMap集成HashMap,因此,具备了HashMap的优良特性——高性能。在HashMap的基础上,LinkedHashMap又在内部增加了一个链表,用以存放元素的顺序。因此LinkedHashMap可以理解成一个维护了元素顺次序表的HashMap。
LinkedHashMap提供了两种类型的顺序:一是元素插入时的顺序;二是最近访问的顺序。可以通过构造函数设置顺序类型。
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
其中accessOrder为true时,按照元素最后访问顺序排序(LurCache使用该排序方式);当accessOrder为false时,按照插入顺序排序,默认是false。
在内部实现中,通过集成HashMap.Entry类,实现了LinkedHashMap.Entry内部类,为HashMap.Entry增加了before和after属性用以记录某一表项的前驱和后驱(与LinkedList相似),形成循环链表结构。如下图所示:
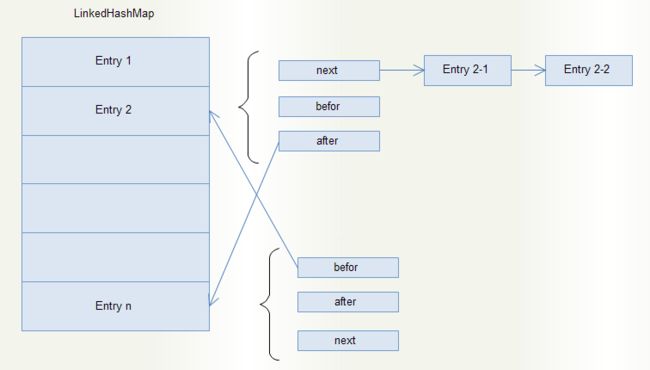
在这种结构中,除了HashMap固有的功能特性外,每个Entry表项的after指向其后驱元素Entry,而后驱元素的before指向其前驱元素,从而构成一个循环链表(类似LinkedList)。
需要注意的是,如果在LinkedHashMap初始化的时候设置了accessOrder为true,应该避免这样的操作:
for (Iterator iterator = (Iterator) linkedHashMap.keySet(); iterator.hasNext(); ) {
String s = iterator.next();
Log.e("joker", linkedHashMap.get(s));
}
该代码会报ConcurrentModificationException,主要出现在迭代过程中集合被修改,不仅是LinkedHashMap,所以集合都不允许在迭代器模式中修改集合。一般会认为put( )和remove( )会修改集合的结构,但是LinkedHashMap的get( )很特殊,get( )方法会修改LinkedHashMap中的链表结构,以便将最近访问的元素放置到链表的末端,所以,会引起这个错误。
片尾Tip:
昨晚翻看IntentService源码发现一个停止服务的API,觉得很有意思。
IntentService中:onHandleIntent回调执行完毕后,会马上调用stopSelf( )方法,试图停止Service。每次通过Context.startService( )启动服务,都会生成一个startId。但是,只有当startId等于最后一次调用Context.startService( )后生成的startId时,才能正确停止掉服务,否则服务是不会停止的。
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1); //停止服务
}
}
@Override
public void onStart(Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}
/**
* Old version of {@link #stopSelfResult} that doesn't return a result.
*
* @see #stopSelfResult
*/
public final void stopSelf(int startId) {
if (mActivityManager == null) {
return;
}
try {
mActivityManager.stopServiceToken(
new ComponentName(this, mClassName), mToken, startId);
} catch (RemoteException ex) {
}
}